
爬虫综合大作业
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
一.把爬取的内容保存取MySQL数据库
- import pandas as pd
- import pymysql
- from sqlalchemy import create_engine
- conInfo = "mysql+pymysql://user:passwd@host:port/gzccnews?charset=utf8"
- engine = create_engine(conInfo,encoding='utf-8')
- df = pd.DataFrame(allnews)
- df.to_sql(name = ‘news', con = engine, if_exists = 'append', index = False)
二.爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
爬取目标:爬取豆瓣top250的电影
豆瓣top250的网页结构:
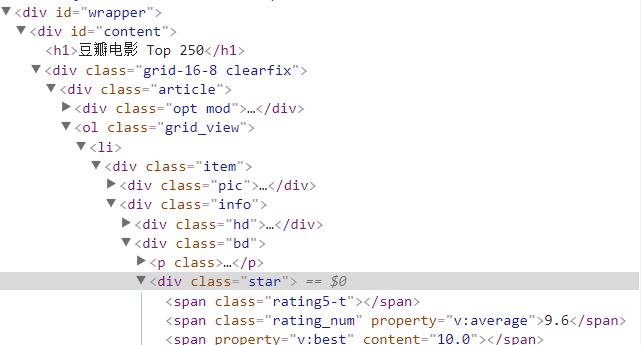
可以看出该网页的数据是分别以item,info,bd,star..等等来命名的class
所以我们可以通过class爬取他们的属性
代码如下:
# -*- coding: utf-8 -*- import requests from lxml import etree if __name__ == '__main__': ranks=[] names=[] directors=[] types=[] juqing=[] stars=[] dd=[] gg=[] people=[] grades=[] quotes=[] numbers=['0','25','50','75','100','125','150','175','200','225'] for number in numbers: url = 'https://movie.douban.com/top250?start={}&filter='.format(number)#实现翻页功能 headers = { "User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" } req = requests.get(url = url,headers = headers) req.encoding = 'utf-8' html = req.text html1=etree.HTML(html) rank=html1.xpath('//div[@class="item"]/div/em/text()')#x-path地址并获取文字 for rank1 in rank: ranks.append(rank1) name=html1.xpath('//div[@class="info"]/div[1]/a/span[1]/text()') for name1 in name: names.append(name1) director=html1.xpath('//div[@class="bd"]/p[1]/text()') for director1 in director: directors.append(director1) people1=html1.xpath('//div[@class="star"]/span[4]/text()') for people2 in people1: people.append(people2) grade=html1.xpath('//div[@class="star"]/span[@class="rating_num"][@property="v:average"]/text()') for grade1 in grade: grades.append(grade1) quote=html1.xpath('//p[@class="quote"]/span/text()') for quote1 in quote: quotes.append(quote1) for i in directors: gg.append(i.strip()) for k in gg: dd.append("".join(k.split())) for q in range(25): juqing.append(dd[2*q-1]) for q in range(25): stars.append(dd[2*q]) import pandas as pd #字典中的key值即为csv中列名 columns1= ['豆瓣排名','电影名','剧情','导演/主演','评分','评价人数','queto']#csv会按首字母进行排序,所以加表格自己排序 dataframe = pd.DataFrame({'豆瓣排名':ranks,'电影名':names,'剧情':juqing,'导演/主演':stars,'评分':grades,'评价人数':people,'queto':quotes}) #dataframe = pd.DataFrame({'类型':types}) #将DataFrame存储为csv,index表示是否显示行名,default=True dataframe.to_csv("豆瓣电影top250.csv",encoding="utf_8_sig",index=False,columns=columns1)
生成的CSV文件

文件分析:
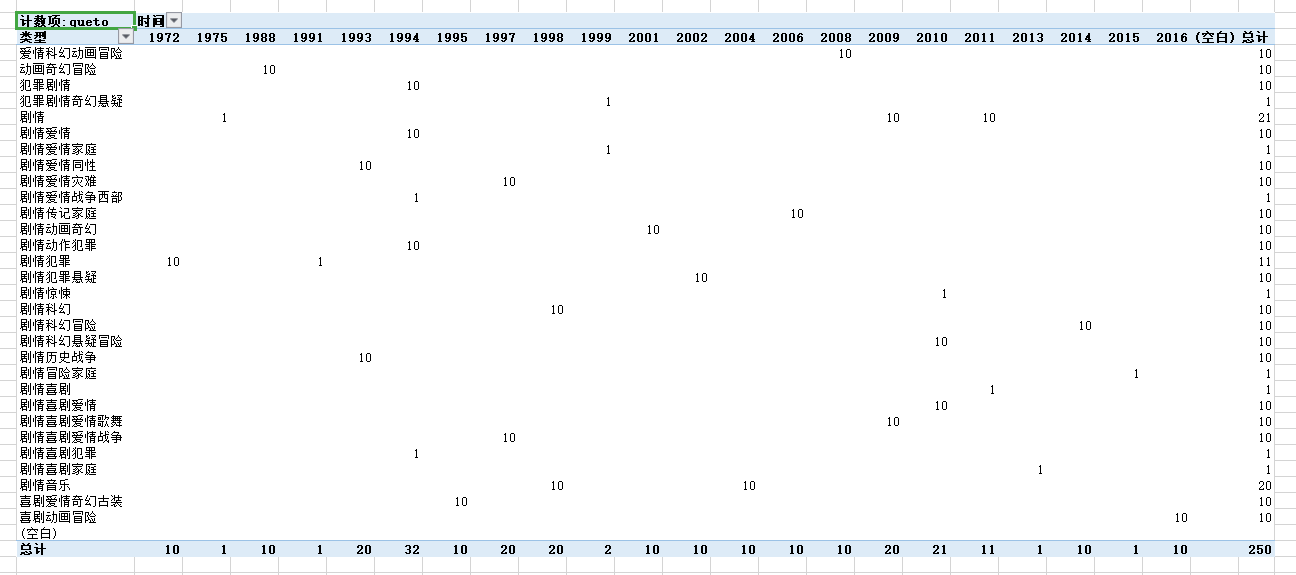
1. 可以看出剧情类的电影在TOP250中的数量是最多的,也就是说比较多人偏向纯剧情类型的电影,还有20部电影是剧情音乐类型的,也是会有挺多人的喜欢看得
2. 犯罪剧情奇幻悬疑,剧情爱情家庭,战争西部片,比较少好的电影,也比较少人看,也有部分的喜剧类电影比较少人看,比如犯罪类型和家庭类喜剧。
3. 从上图也可以看出来在1994年的电影占豆瓣TOP250比较多的比例,一共32部电影入选。1975和1991年就比较少了,只有1部电影,13和15年亦是如此只有一部电影可以进入豆瓣TOP250
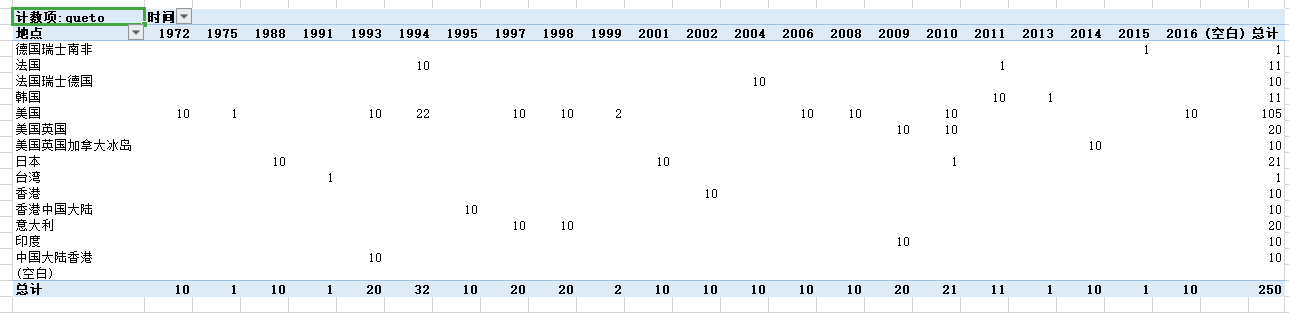
4. 从上图可以分析得出,在豆瓣TOP250中,美国的电影是占了大部分的,250部电影里就有105部电影,可以说美国在电影产业是遥遥领先的,而中国总共只有30部电影榜上有名,看来中国的电影产业有待发展
5. 美国在1994年,电影行业迅速发展,一下子有22部电影可以进入豆瓣YOP250。而在中国台湾就比较惨淡了,只有一部电影可以进入豆瓣TOP250。在1994年之后全球的电影又回到平平淡淡的时期了
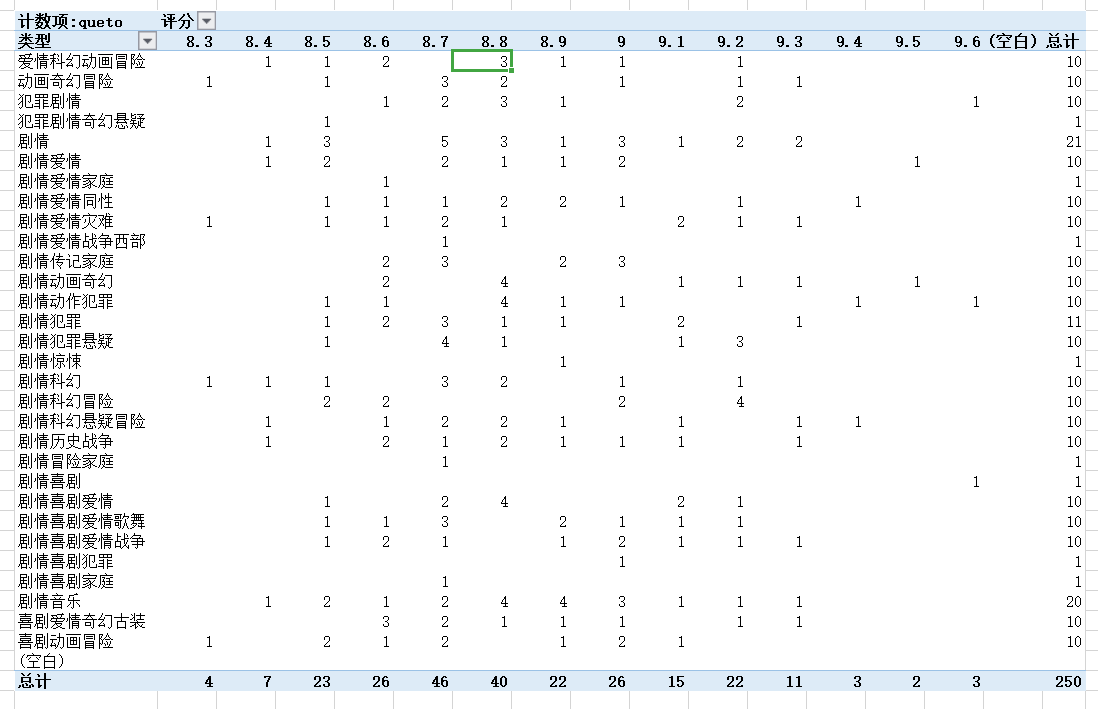
6. 我们从所有的评分人数统计可以看出,大多数人会是比较中肯,都会评价8.7或者8.8 分,而且越往两边就人数越少。
7. 犯罪类型和喜剧类型收获过最高分9.6分,看来大家还是比较喜欢看犯罪类型的电影去寻求一些刺激。
