
2018软工实践作业二
Github地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 30 |
| · Design Spec | · 生成设计文档 | 30 | 0 |
| · Design Review | · 设计复审 | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 120 | 240 |
| · Code Review | · 代码复审 | 20 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 345 | 595 |
代码的实现
各函数的关系图如下:
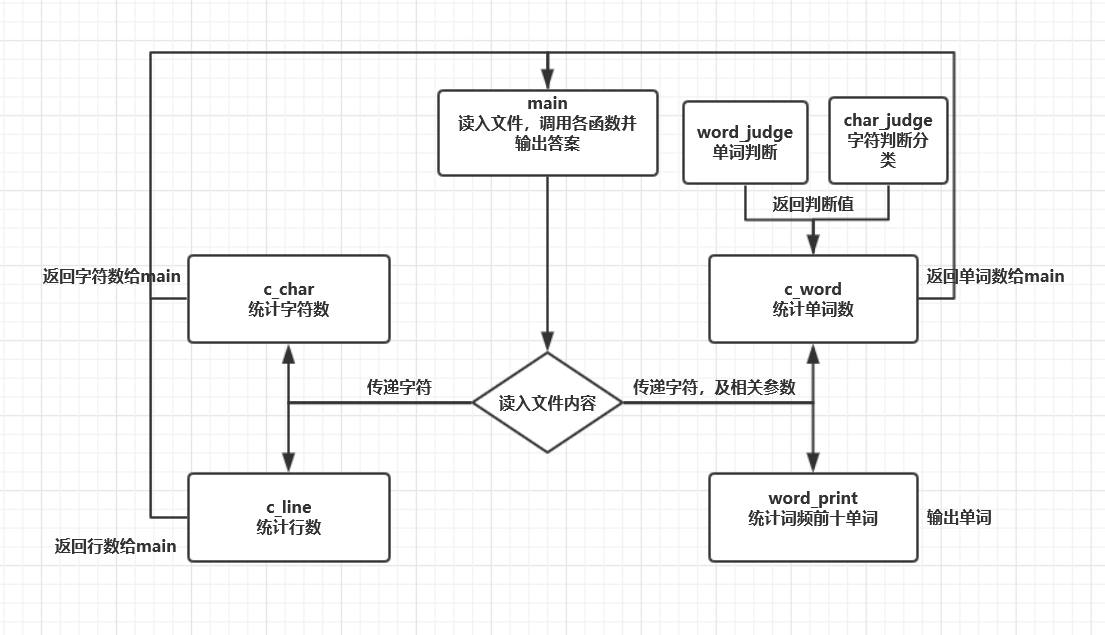
main()函数
主要负责文本文件的读入,调用其他函数及参数传递,并输出函数返回的结果。
c_char()函数
接受main()函数传入的文本字符串,统计文本中的有效字符数并返回。
c_line()函数
接受main()函数传入的文件路径,打开文件,以按行读入的方式统计文本的行数并返回。
c_word()函数
本程序的最关键的部分,用了最直接的遍历判断法。
从首字符开始遍历,利用char_judge()函数判断当前字符是否是字母:
若不是字母,则判断下一字符;
若是字母,则进入word_judge()函数判断当前字母后的三位字符是否是字母:
若其后三位均是字母,则符合“单词”条件,单词数加1,进入单词合成循环将其后的字符合并成一个单词知道遇到非法字符为止,并将单词加入字符串数组word[i]存储;
若有一位不是字母,则不符合“单词”条件,返回检测过的单词数num,上层循环参数跳num位,再次执行循环。
遍历结束后跳出循环,得到合法单词数并返回主函数,同时将合法单词合成后存入字符串数组word[i],方便单词频率统计。
word_print()函数
利用word[i]数组中已存储的单词,遍历后,去掉重复单词,并统计出每个单词的频率,以及单词的acill码值和,作为排序条件;
用了最简单但并不快捷的冒泡排序,以单词频率作为首要排序条件,以单词的acill码值和作为次要排序条件,对单词进行排序;
排序后,输出排名前10的单词,以及其频率;
代码性能
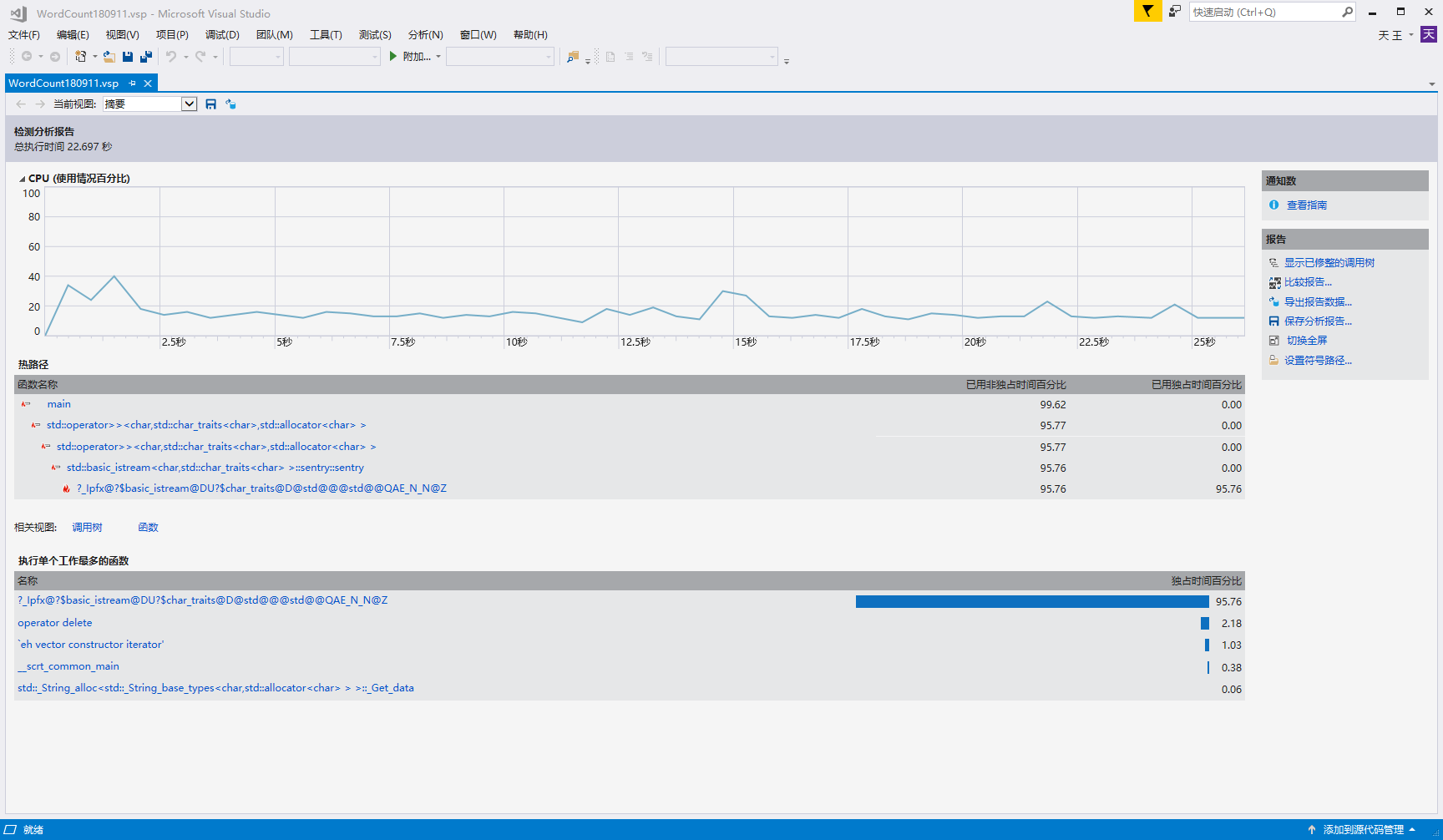
一开始使用c++输入输出流函数来输出,单次测试总执行时间达到了20s+;
于是,改用printf函数来输出,单次测试结果如下:
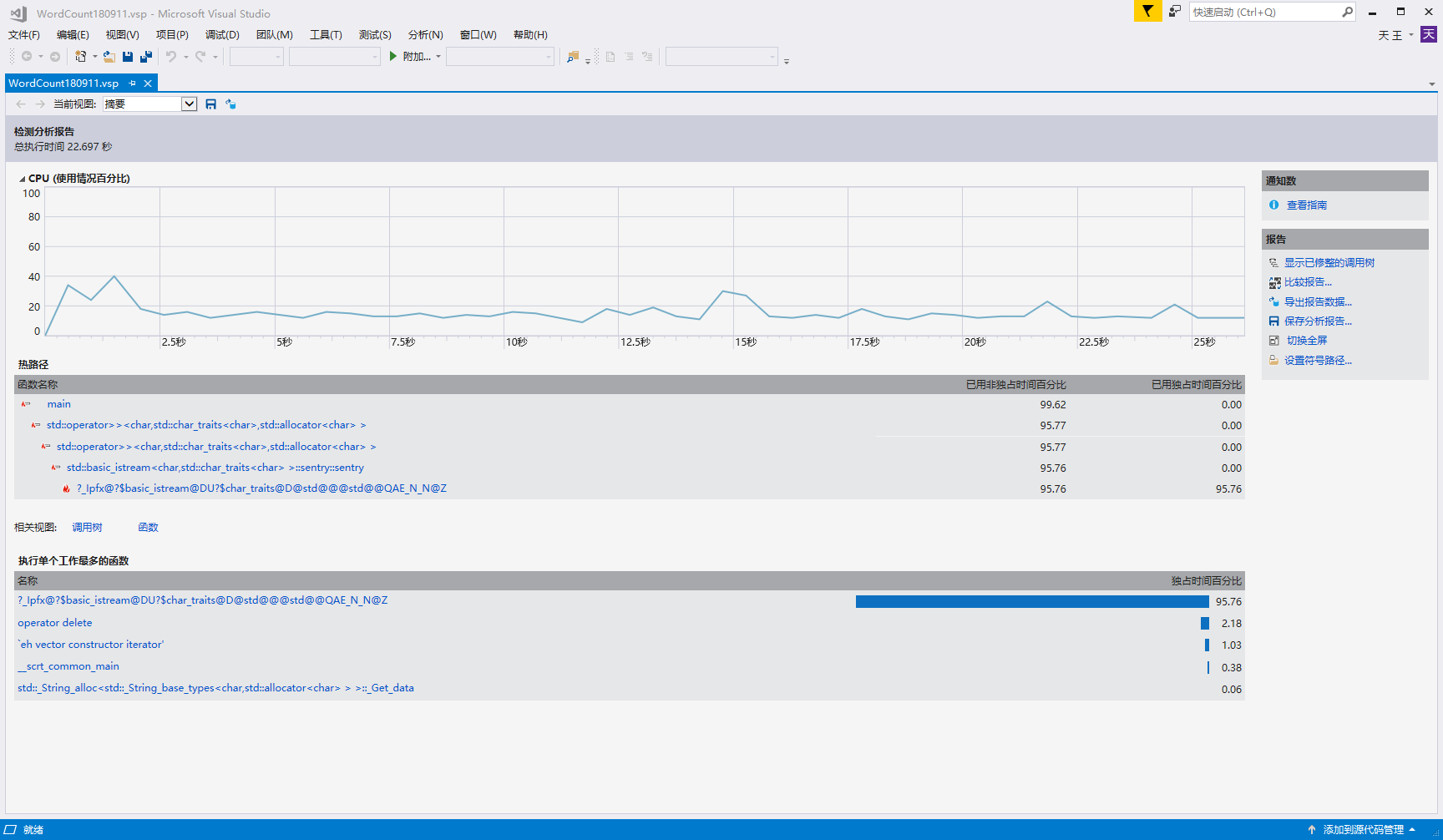
单次执行后时间变成了12s+,有了不少的提升;
其余可改进的地方还有很多,比如:更好的数据结构、更好的排序算法等等,但因为时间原因来不及改进,后面会继续改进。
体会和感想
之前代码被自己荒废了很久,这次也算是通过这次作业捡起来一些,当然过程就显得比较曲折。
在时间花费上,主要在编码和Github的使用上花费了很多很多时间:
编码问题是因为长期荒废,遗忘和手生导致了编码过程磕磕绊绊;
Github的使用出现了不少问题,到最后莫名出现了commit失败无法提交的问题,到现在也没有解决,所以只能是提交初版比较粗糙的代码。
但总体来讲,还是有很大的收获,捡起了荒废了很久的代码,让我有一个新的开始;看过了别人的博客和代码,让我认识到自己的不足;一次次程序的debug、Github的崩溃、软件功能的学习,让我受益匪浅;还有,就是现在最后时刻的博客编辑,锻炼了我良好的心态~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号