

102102151 黄靖 作业四
任务一:
1.实验要求
熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内容。
使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块的股票数据信息。
候选网站:东方财富网:
http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头
Gitee 文件夹链接:文件链接
2.代码
from selenium.webdriver.common.by import By
from selenium import webdriver
import pymysql
import time
conn = pymysql.connect(host='localhost',password='123456',user='root',database='spider')
cursor = conn.cursor()
cursor.execute("create table 沪深A股(序号 varchar(20),股票代码 varchar(20),股票名称 varchar(20),最新报价 varchar(20),涨跌幅 varchar(20),涨跌额 varchar(20),成交量 varchar(20),成交额 varchar(20),振幅 varchar(20),最高 varchar(20),最低 varchar(20),今开 varchar(20),昨收 varchar(20))")
cursor.execute("create table 上证A股(序号 varchar(20),股票代码 varchar(20),股票名称 varchar(20),最新报价 varchar(20),涨跌幅 varchar(20),涨跌额 varchar(20),成交量 varchar(20),成交额 varchar(20),振幅 varchar(20),最高 varchar(20),最低 varchar(20),今开 varchar(20),昨收 varchar(20))")
cursor.execute("create table 深证A股(序号 varchar(20),股票代码 varchar(20),股票名称 varchar(20),最新报价 varchar(20),涨跌幅 varchar(20),涨跌额 varchar(20),成交量 varchar(20),成交额 varchar(20),振幅 varchar(20),最高 varchar(20),最低 varchar(20),今开 varchar(20),昨收 varchar(20))")
conn.commit()
sql1 = "INSERT INTO 沪深A股 (序号,股票代码, 股票名称,最新报价,涨跌幅,涨跌额,成交量,成交额,振幅,最高,最低,今开,昨收) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"
sql2 = "INSERT INTO 上证A股 (序号,股票代码, 股票名称,最新报价,涨跌幅,涨跌额,成交量,成交额,振幅,最高,最低,今开,昨收) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"
sql3 = "INSERT INTO 深证A股 (序号,股票代码, 股票名称,最新报价,涨跌幅,涨跌额,成交量,成交额,振幅,最高,最低,今开,昨收) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
page = input("请分别输入“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块要爬取的页数:")
pagelist = list(map(int, page.split()))
pageA = pagelist[0]
pageB = pagelist[1]
pageC = pagelist[2]
driver = webdriver.Chrome()
driver.get(url)
print("沪深 A 股")
for i in range(pageA):
content = driver.find_elements(By.XPATH, '//*[@id="table_wrapper-table"]/tbody/tr')
for j in content:
list = j.text.split(" ")
values = (
list[0], list[1], list[2], list[6], list[7], list[8], list[9], list[10], list[11], list[12], list[13], list[14],
list[15])
cursor.execute(sql1, values)
conn.commit()
next_button = driver.find_element(By.XPATH, '//a[@class="next paginate_button"]')
next_button.click()
time.sleep(2)
driver.get("http://quote.eastmoney.com/center/gridlist.html#sh_a_board")
print("上证 A 股")
time.sleep(2)
for i in range(pageB):
content = driver.find_elements(By.XPATH, '//*[@id="table_wrapper-table"]/tbody/tr')
for j in content:
list = j.text.split(" ")
values = (
list[0], list[1], list[2], list[6], list[7], list[8], list[9], list[10], list[11], list[12], list[13],
list[14],
list[15])
cursor.execute(sql2, values)
conn.commit()
next_button = driver.find_element(By.XPATH, '//a[@class="next paginate_button"]')
next_button.click()
time.sleep(2)
driver.get("http://quote.eastmoney.com/center/gridlist.html#sz_a_board")
print("深证 A 股")
time.sleep(2)
for i in range(pageC):
content = driver.find_elements(By.XPATH, '//*[@id="table_wrapper-table"]/tbody/tr')
for j in content:
list = j.text.split(" ")
values = (
list[0], list[1], list[2], list[6], list[7], list[8], list[9], list[10], list[11], list[12], list[13],
list[14],
list[15])
cursor.execute(sql3, values)
conn.commit()
next_button = driver.find_element(By.XPATH, '//a[@class="next paginate_button"]')
next_button.click()
time.sleep(2)
cursor.close()
conn.close()
3.运行结果:
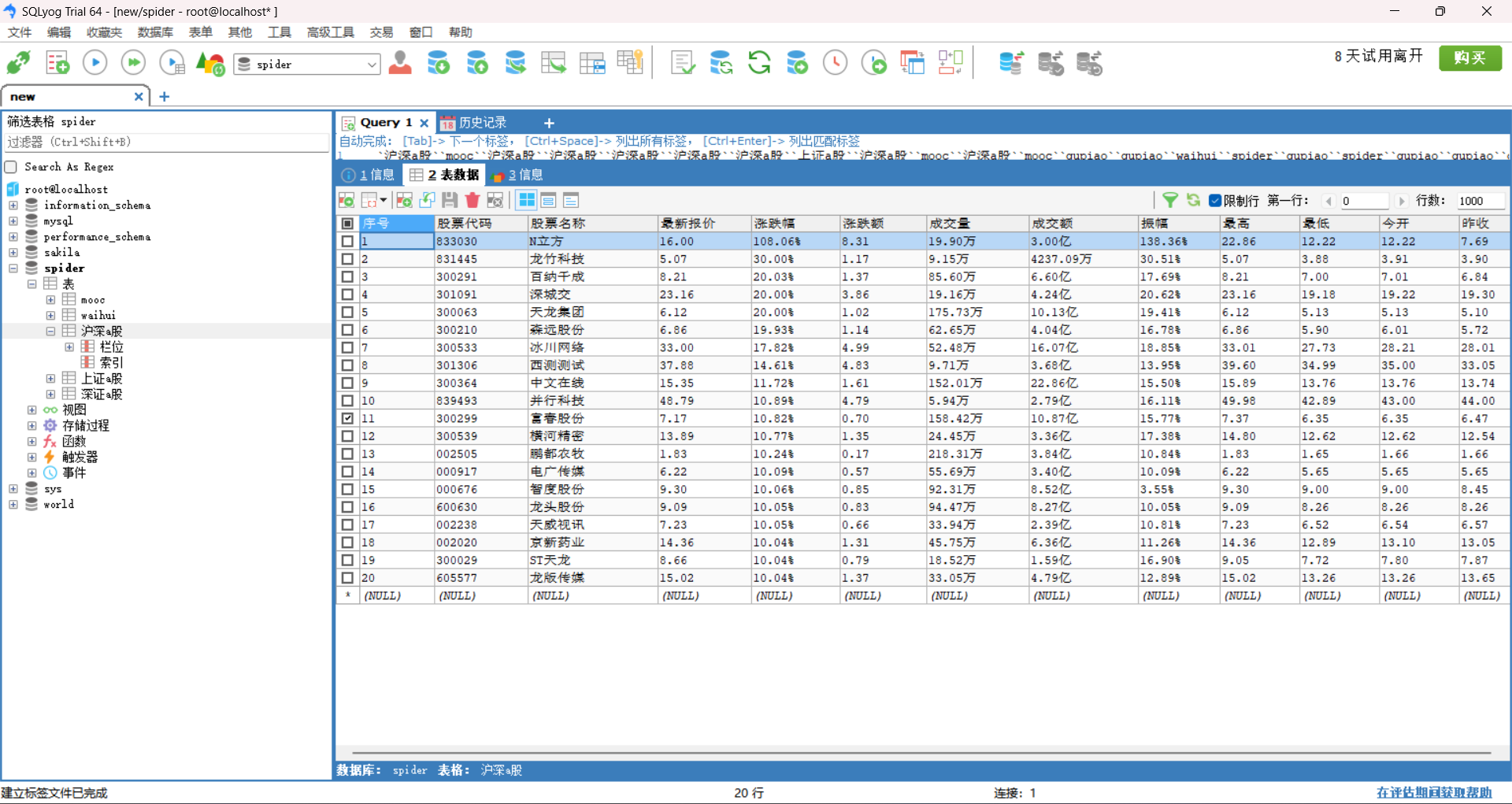


4.实验心得:
这个任务总体不难,对于爬取的网站经过前几次实验课已经相当熟悉,这次使用Selenium的技术路线爬取所需信息,让我对Selenium爬虫更为熟悉,也更了解了pysql的相关操作
任务二:
1.实验要求:
熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、等待 HTML 元素等内容。
使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国 mooc 网:https://www.icourse163.org
输出信息:MYSQL 数据库存储和输出格式
Gitee 文件夹链接:文件链接
2.代码:
from selenium.webdriver.common.by import By
from selenium import webdriver
import time
import pymysql
n = 1
zhanghao = input("请输入你的账号:")
mima = input("请输入你的密码:")
conn = pymysql.connect(host='localhost', user='root', password='123456', database='spider')
cursor = conn.cursor()
cursor.execute("create table mooc(Id varchar(20),cCourse varchar(20),cCollege varchar(20),cTeacher varchar(20),cTeam varchar(20),cCount varchar(20),cProcess varchar(50),cBrief varchar(1000))")
conn.commit()
sql = "INSERT INTO mooc (Id,cCourse,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("https://www.icourse163.org/")
load = driver.find_element(By.XPATH,'//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div')
load.click()
time.sleep(3)
iframe = driver.find_element(By.XPATH,'/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe')
driver.switch_to.frame(iframe)
driver.find_element(By.XPATH,'/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input').send_keys(zhanghao)
driver.find_element(By.XPATH,'/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]').send_keys(mima)
driver.find_element(By.XPATH,'/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a').click()
time.sleep(5)
driver.switch_to.default_content()
time.sleep(3)
driver.find_element(By.XPATH,'//*[@id="privacy-ok"]').click()
driver.find_element(By.XPATH,'/html/body/div[4]/div[2]/div[1]/div/div/div[1]/div[1]/div[1]/span[1]/a').click()
driver.switch_to.window(driver.window_handles[-1])
for _ in range(2):
for i in range(5):
list = driver.find_element(By.XPATH,f'//*[@id="channel-course-list"]/div/div/div[2]/div[1]/div[{i+1}]/div/div[3]/div[1]').text.split("\n")
driver.find_element(By.XPATH,f'//*[@id="channel-course-list"]/div/div/div[2]/div[1]/div[{i+1}]').click()
driver.switch_to.window(driver.window_handles[-1])
team = driver.find_elements(By.XPATH,'//*[@class="f-fc3"]')
m = []
for j in team:
m.append(j.text)
m = ','.join(m)
list.append(m)
count = driver.find_element(By.XPATH,'//*[@class="count"]').text
list.append(count[2:-3])
date = driver.find_element(By.XPATH,'//*[@id="course-enroll-info"]/div/div[1]/div[2]/div/span[2]').text
list.append(date)
brief = driver.find_element(By.XPATH,'//*[@id="j-rectxt2"]').text
list.append(brief)
values = (n, list[0], list[1], list[2], list[3], list[4], list[5], list[6])
cursor.execute(sql, values)
conn.commit()
n = n+1
driver.close()
driver.switch_to.window(driver.window_handles[-1])
driver.find_element(By.XPATH,'//*[@id="channel-course-list"]/div/div/div[2]/div[2]/div/a[10]').click()
time.sleep(2)
cursor.close()
conn.close()
3.运行结果:
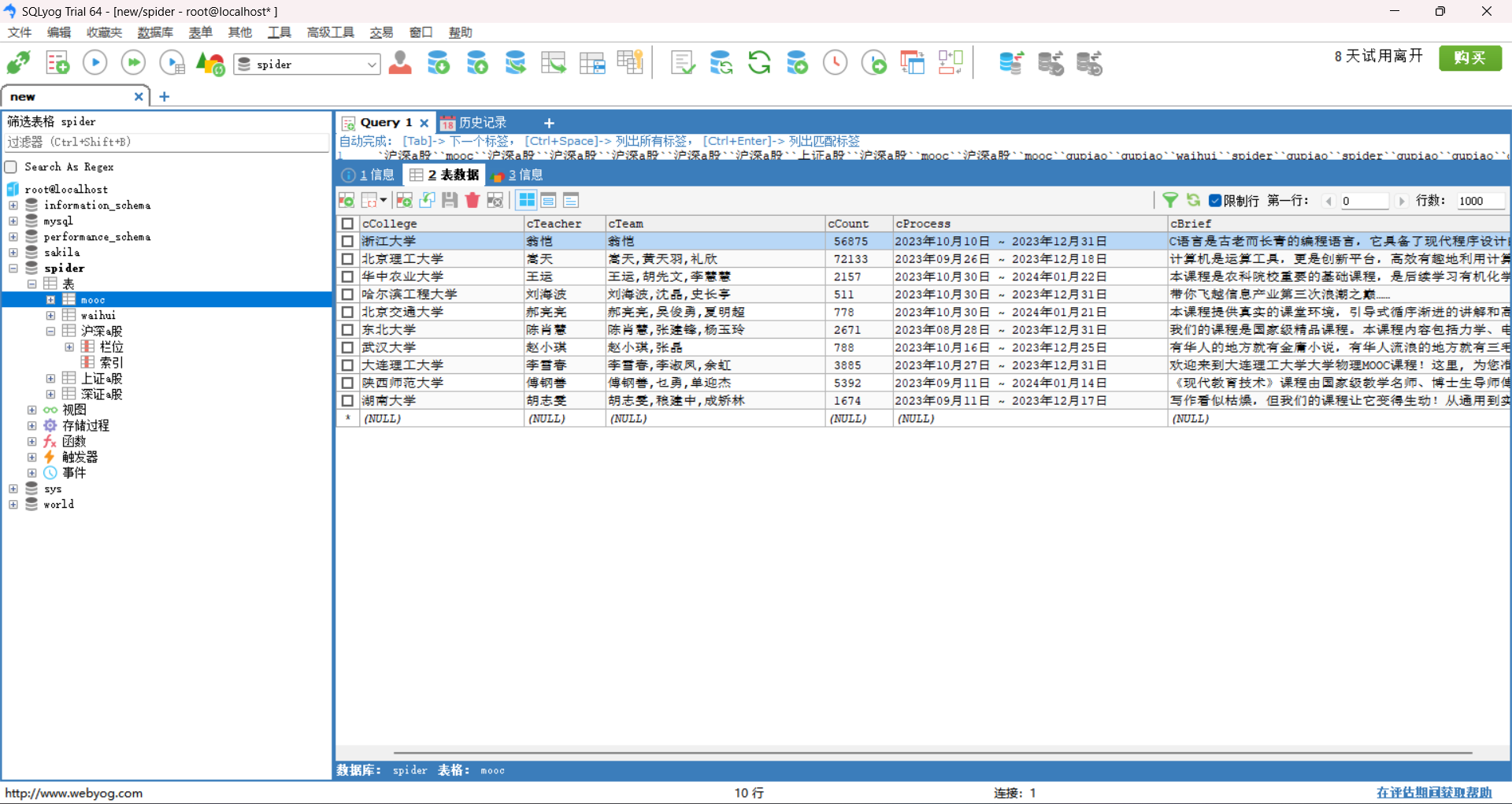
4.心得体会:
相比前面的实验,这个任务在登陆的时候涉及到iframe的弹窗知识和新网页切换的知识,需要对相关内容进行学习,更有难度一些
任务三:
要求:掌握大数据相关服务,熟悉 Xshell 的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
环境搭建:
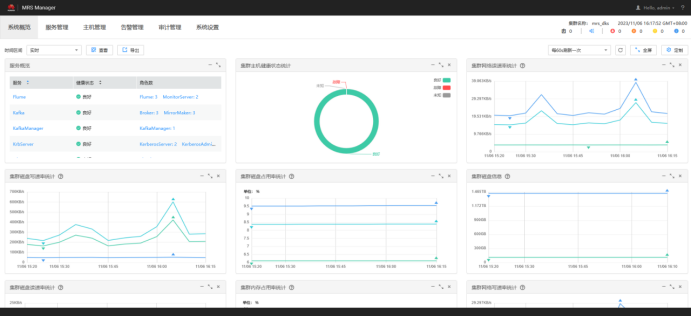
任务一:开通 MapReduce 服务
实时分析开发实战:
任务一:Python 脚本生成测试数据

任务二:配置 Kafka

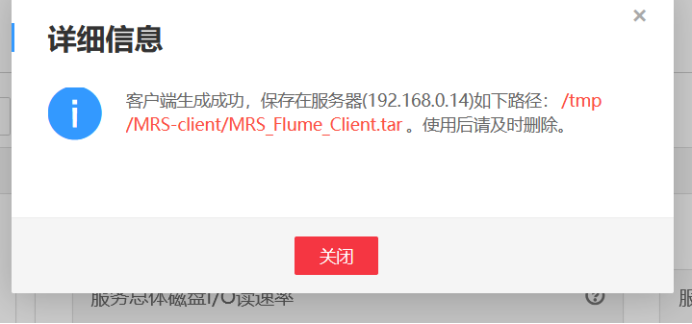
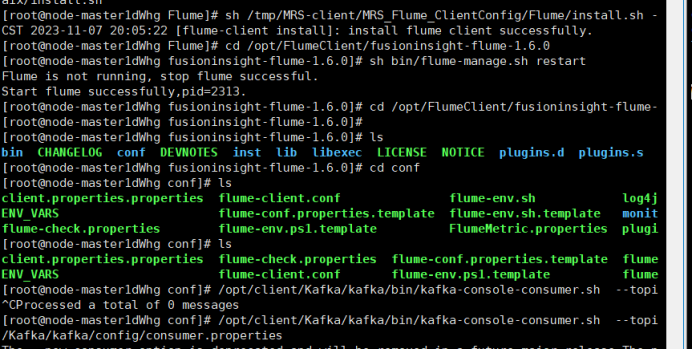
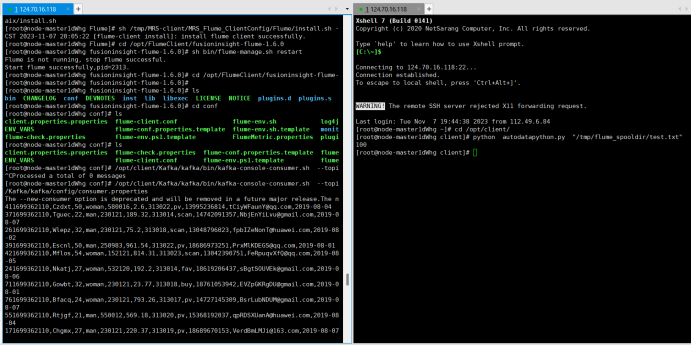
任务三: 安装 Flume 客户端


任务四:配置 Flume 采集数据



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)