

102102151 黄靖 作业三
第一题
码云地址:https://gitee.com/HJ_orange/crawl_project/tree/master/实践作业3
(1)要求:使用单线程和多线程的方法爬取中国气象网的限定数量的图片
(2) 下面给出代码实现:
weather.py
import scrapy
from ..items import WeatherItem
class weatherSpider(scrapy.Spider):
page = 0
number = 0
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"
name = "weather"
allowed_domains = ['weather.com.cn']
start_urls = ['http://pic.weather.com.cn']
def parse(self, response):
src_list = response.xpath('/html/body/li/a/img/@src').extract()
url_list = response.xpath('/html/body/li/a/@href').extract()
for src in src_list:
if(self.number < 151):
print(src)
item = WeatherItem()
item['src'] = src
item['num'] = self.number
self.number += 1
yield item
for list in url_list:
if(self.page == 51):
break
yield scrapy.Request(list, callback = self.parse)
item.py
import scrapy
class WeatherItem(scrapy.Item):
src = scrapy.Field()
url = scrapy.Field()
num = scrapy.Field()
pass
pipeline.py
import scrapy
import time
from scrapy.pipelines.images import ImagesPipeline
class imgsPipeLine(ImagesPipeline):
#根据图片地址进行图片数据的请求
def get_media_requests(self, item, info):
yield scrapy.Request(item['img'])
#指定图片存储的路径
def file_path(self, request, response=None, info=None, *, item=None):
imgName = request.url.split('/')[-1]
return imgName
def item_completed(self, results, item, info):
print("successfully saved")
return item
(3)心得:这个任务之前在老师布置的作业里已经完成过类似的作业(爬取当当网图片) 这次基本就是重新熟悉一下 值得注意的是 若要改用多线程,则把setting文件中的concurrent_request改为32即可。
作业二
(1)要求:使用scrapy+xpath爬取股票网站信息
(2) 下面给出代码实现:
stock.py
import scrapy
import json
from ..items import EastmoneyItem
class MoneySpider(scrapy.Spider):
name = "money"
allowed_domains = ["http://65.push2.eastmoney.com"]
start_urls = ["http://65.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112406736638761710398_1697718587304&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1697718587305"]
def parse(self, response):
number=1
response = response.text
response=response[42:-2]
data=json.loads(response)
data = data['data']['diff']
for d in data:
item=EastmoneyItem()
item['data']=d
item['number']=number
number+=1
yield item
item.py
import scrapy
class EastmoneyItem(scrapy.Item):
data = scrapy.Field()
number = scrapy.Field()
pipeline.py
import sqlite3
class EastmoneyPipeline(object):
con=None
cursor=None
def open_spider(self,spider):
self.con=sqlite3.connect("eastmoney.db")
self.cursor=self.con.cursor()
self.cursor.execute("create table money("
"id int,"
"stocksymbol varchar(16),"
"stockname varchar(16),"
"LatestPrice varchar(16),"
"Pricelimit varchar(16),"
"Riseandfall varchar(16),"
"volume varchar(16),"
"turnover varchar(16),"
"amplitude varchar(16),"
"max varchar(16),"
"min varchar(16),"
"today varchar(16),"
"yesterday varchar(16))")
def process_item(self, item, spider):
try:
data = item['data']
num = item['num']
self.cursor.execute("insert into money values(?,?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)",(num,data['f12'],data['f14'],data['f2'],data['f3'],data['f4'],data['f5'],data['f6'],data['f7'],data['f15'],data['f16'],data['f17'],data['f18']))
print("Successfully inserted")
self.con.commit()
except Exception as e:
print(e)
self.con.rollback()
def close_spider(self,spider):
self.cursor.close()
self.con.close()
运行代码后得:
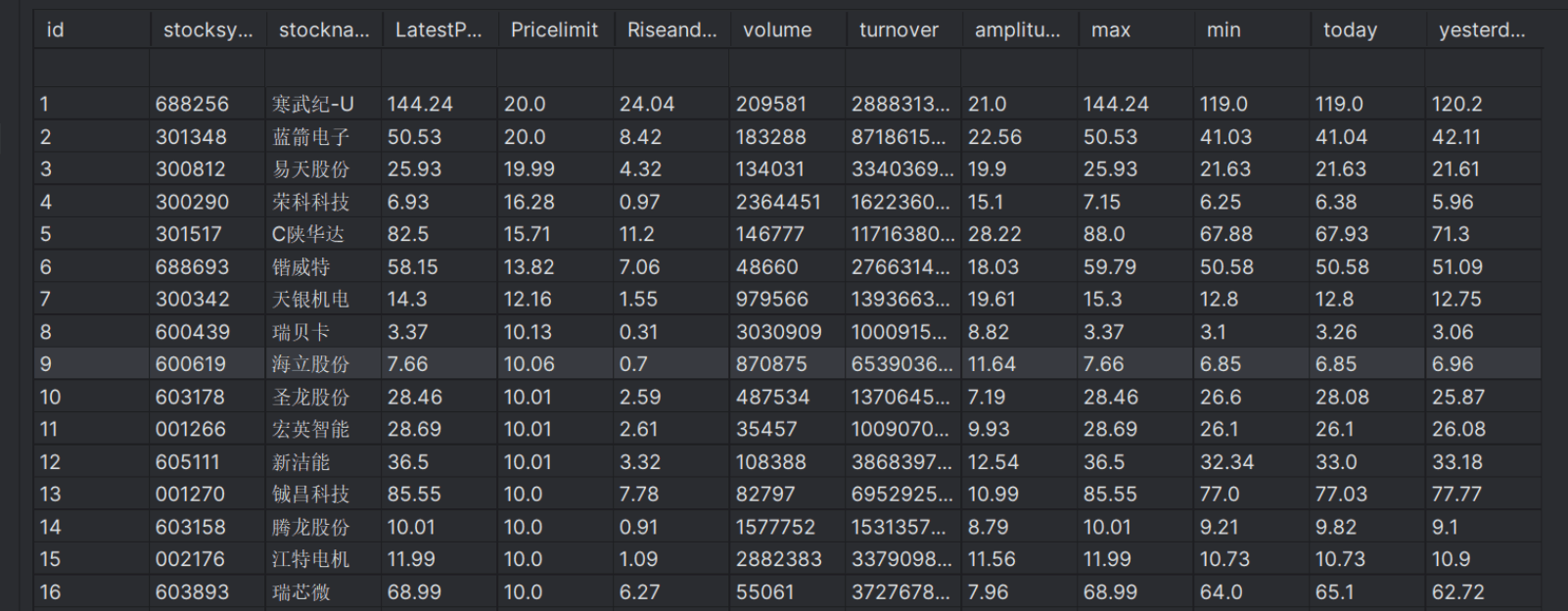
(3)心得:股票交易网站的数据信息的分离较为困难,深刻体会到了Selenium爬取的方便之处,使用scrapy+Selenium的方式加深了对页面爬取的印象。
作业三
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息并存储于数据库中。
代码如下:
money.py
import time
import scrapy
from lxml import etree
from ..items import MoneyItem
from selenium import webdriver
class MySpider(scrapy.Spider):
name = "mySpider3"
def start_requests(self):
url = 'https://www.boc.cn/sourcedb/whpj/' # 要爬取的网页URL
self.driver.get(url)
time.sleep(1) # 等待页面加载完毕
html = etree.HTML(self.driver.page_source) # 获取网页HTML内容
yield scrapy.Request(url, self.parse, meta={'html': html})
# 定义parse方法,用于处理服务器返回的响应
def parse(self, response):
# 定义一个全局变量item,这样在处理响应之外的地方也可以引用到这个变量
global item
html = response.meta['html']
lis = html.xpath('/html/body/div/div[5]/div[1]/div[2]/table/tbody/tr')
number = 1
# 获取元素
for link in lis:
if number != 1:
texts = link.xpath('./td[1]/text()')
if texts:
name = texts[0]
else:
name = ''
texts = link.xpath('./td[2]/text()')
if texts:
TBP = texts[0]
else:
TBP = ''
texts = link.xpath('./td[3]/text()')
if texts:
CBP = texts[0]
else:
CBP = ''
texts = link.xpath('./td[4]/text()')
if texts:
TSP = texts[0]
else:
TSP = ''
texts = link.xpath('./td[5]/text()')
if texts:
CSP = texts[0]
else:
CSP = ''
texts = link.xpath('./td[8]/text()')
if texts:
TIME = texts[0]
else:
TIME = ''
item = Demo3Item()
item["currency"] = name
item["TBP"] = TBP
item["CBP"] = CBP
item["TSP"] = TSP
item["CSP"] = CSP
item["time"] = TIME
yield item
if number == 1:
number = number + 1
item.py
import scrapy
class MoneyItem(scrapy.Item):
currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
time = scrapy.Field()
pass
pipeline.py
import pymysql
class DemoPipeline:
def process_item(self, item, spider):
try:
print(item["currency"])
print(item["TSP"])
print(item["CSP"])
print(item["TBP"])
print(item["CBP"])
print(item["time"])
print()
# 将数据插入数据库的表中
mydb = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb", charset="utf8")
mycursor = mydb.cursor()
sql="insert into currency (currency,TSP,CSP,TBP,CBP,time) values (%s,%s,%s,%s,%s,%s)"
val=(item["currency"], item["TSP"], item["CSP"], item["TBP"], item["CBP"], item["time"])
mycursor.execute(sql, val)
mydb.commit()
except Exception as err:
print(err)
return item
运行结果:

(3)心得:与第二题类似,使用scrapy+Selenium的方式爬取指定内容,在第二题遇到的困难在第三题注意避坑了,所以完成的比较顺利。


