
102102151 黄靖 数据采集实践一
作业一
(1)要求:
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
(2) 下面给出代码实现:
import requests
import bs4
import urllib.request
from bs4 import BeautifulSoup
def ThriveList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
a = tr('a')
tds = tr('td')
ulist.append([tds[0].text.strip(), a[0].string.strip(), tds[2].text.strip(),
tds[3].text.strip(), tds[4].text.strip()])
def GetHTML(url):
res = requests.get(url)
res.raise_for_status()
res.encoding = res.apparent_encoding
return res.text
req = urllib.request.Request(url)
response = urllib.request.urlopen(req)
data = response.read().decode()
return data
def PrintList(ulist1, num):
tplt = "{0:^10}\t{1:^10}\t{2:^10}\t{3:^12}\t{4:^10}"
print(tplt.format("排名", "学校", "\t\t省份", "类型", "总分"))
for i in range(num):
u = ulist1[i]
print(tplt.format(u[0], u[1], u[2], u[3], u[4]))
if __name__ == '__main__':
uinfo = []
url = "https://www.shanghairanking.cn/rankings/bcur/2020"
html = GetHTML(url)
ThriveList(uinfo, html)
PrintList(uinfo, 10)
(3)心得:这个任务之前在老师布置的作业里已经完成过了 这次基本就是重新熟悉一下 代码运行无误即可提交
作业二
(1)要求:
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
(2) 下面给出代码实现:
import requests
import re
import bs4
import urllib.request
from bs4 import BeautifulSoup
url = 'https://h5api.m.taobao.com/h5/mtop.alimama.union.xt.en.api.entry/1.0/?jsv=2.5.1&appKey=12574478&t=1695478244004&sign=40359082982e7216b9c3f96d27960de2&api=mtop.alimama.union.xt.en.api.entry&v=1.0&AntiCreep=true&timeout=20000&AntiFlood=true&type=jsonp&dataType=jsonp&callback=mtopjsonp2&data=%7B%22pNum%22%3A0%2C%22pSize%22%3A%2260%22%2C%22refpid%22%3A%22mm_26632360_8858797_29866178%22%2C%22variableMap%22%3A%22%7B%5C%22q%5C%22%3A%5C%22%E4%B9%A6%E5%8C%85%5C%22%2C%5C%22navigator%5C%22%3Afalse%2C%5C%22clk1%5C%22%3A%5C%2286c88e4526fe5dcfa80971971c4961ee%5C%22%2C%5C%22union_lens%5C%22%3A%5C%22recoveryid%3A201_33.61.109.16_52696080_1695478228116%3Bprepvid%3A201_33.61.109.16_52696080_1695478228116%5C%22%2C%5C%22recoveryId%5C%22%3A%5C%22201_33.61.21.33_52706590_1695478243817%5C%22%7D%22%2C%22qieId%22%3A%2236308%22%2C%22spm%22%3A%22a2e0b.20350158.31919782%22%2C%22app_pvid%22%3A%22201_33.61.21.33_52706590_1695478243817%22%2C%22ctm%22%3A%22spm-url%3Aa2e0b.20350158.search.1%3Bpage_url%3Ahttps%253A%252F%252Fuland.taobao.com%252Fsem%252Ftbsearch%253Frefpid%253Dmm_26632360_8858797_29866178%2526keyword%253D%2525E4%2525B9%2525A6%2525E5%25258C%252585%2526clk1%253D86c88e4526fe5dcfa80971971c4961ee%2526upsId%253D86c88e4526fe5dcfa80971971c4961ee%2526spm%253Da2e0b.20350158.search.1%2526pid%253Dmm_26632360_8858797_29866178%2526union_lens%253Drecoveryid%25253A201_33.61.109.16_52696080_1695478228116%25253Bprepvid%25253A201_33.61.109.16_52696080_1695478228116%22%7D'
headers = {
'cookie' : 'miid=402740556623822052; cna=jQrmGe8MNB8CAXAxWIhAaLg2; t=e6bb350810e2ed06def36e881b2959a9; sgcookie=E1007wN9lvV7wvdH1SOl4arzXvGE33AW4x0MpMu8Ear2Go20n7QGskpyVsLfP9o1ublRbxXyPRg9mpb%2FBZE%2FD1VmyUxMzLv48hR4BoK6jeCupOaoJXWwoXwSCEuKKD2VfQN3; uc3=nk2=F5RBzex5G%2Fmro%2FfF&vt3=F8dCsGSKnt0YnCHp%2BDE%3D&lg2=VT5L2FSpMGV7TQ%3D%3D&id2=UUpgRswVvM%2FlXLPRZw%3D%3D; lgc=tb4897206842; uc4=id4=0%40U2gqyZybq3QmrSW25pssDjgHW%2FNQg9Sd&nk4=0%40FY4KqBhn%2Fzh5PsBpg0Zlaq7wn9kCH5M%3D; tracknick=tb4897206842; _cc_=Vq8l%2BKCLiw%3D%3D; mt=ci=181_1; thw=cn; xlly_s=1; _m_h5_tk=320e5f462fba1348ef271c62c19cacc5_1695487228495; _m_h5_tk_enc=e338cff715d089ffeb9aec233fb3c49f; isg=BHl5F-N2OGY2yeP5ET3tHBWqiOVThm04LhpOLJuuhKAfIpm04taQCi57pCbUmgVw; l=fBaSkyNuLOJRTR00BOfZnurza779MIRAguPzaNbMi9fPOo1e530VW1he-k8wCnGVFsHMJ3l82ELDBeYBqBdKnxvtNSVsr7kmnmOk-Wf..; tfstk=dr9HbiA6QB5BIq4CZXBIK8373hGORy65oUeRyTQr_N7_9ThB2gAMcUbKVX6psaYwSwyKAHLG4UxW9D1-RuqBIE28p2GB48XRUq3xHxKBvT6rkdfIHHgEjVtSkxHvAXSCehuxA3fFxTloSvtmzdhRgZq8545qU0pOuH7evH9wLrQ2YCyzUwjhQ6Fag7BgFVFPW7N5TGsGk-uV4g1',
'referer' : 'https://uland.taobao.com/sem/tbsearch?refpid=mm_26632360_8858797_29866178&keyword=%E4%B9%A6%E5%8C%85&clk1=86c88e4526fe5dcfa80971971c4961ee&upsId=86c88e4526fe5dcfa80971971c4961ee&spm=a2e0b.20350158.search.1&pid=mm_26632360_8858797_29866178&union_lens=recoveryid%3A201_33.61.109.16_52696080_1695478228116%3Bprepvid%3A201_33.61.109.16_52696080_1695478228116',
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.289 Safari/537.36'
}
def GetData(url,headers):
Traceback = requests.get(url=url, headers=headers)
data = Traceback.text
price = re.findall("\"price\":\"(.*?)\"", data)
name = re.findall("\"creativeTitle\":\"(.*?)\"", data)
x = 1
for i, j in zip(name, price):
if x <= 10:
print(x, i, j)
x += 1
if __name__ == "__main__":
GetData(url,headers)
运行代码后得:
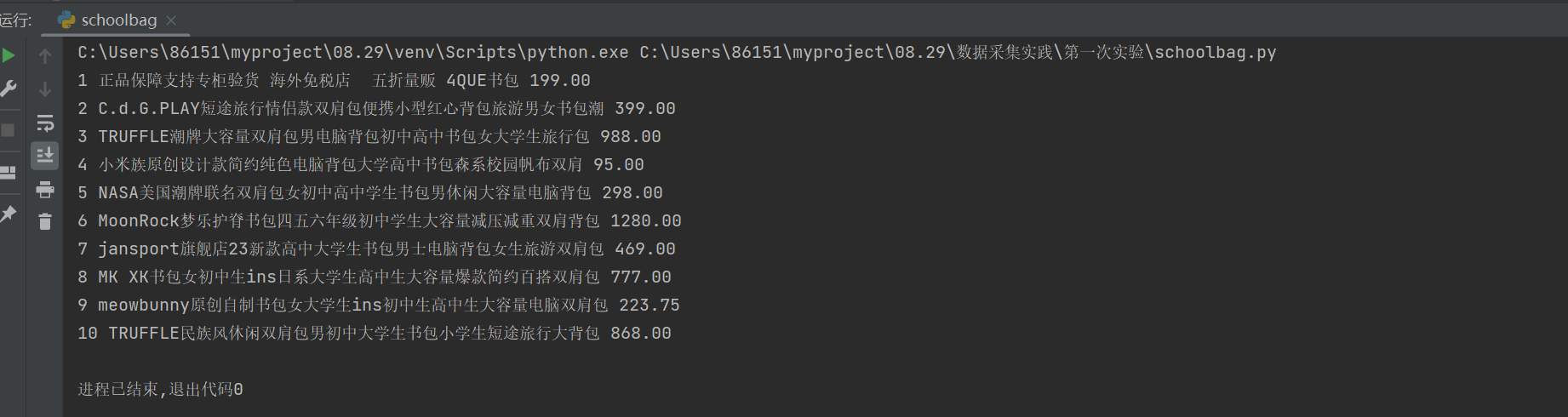
为方便截图仅呈现前十个,具体可修改GetData中的参数
(3)心得:同任务一一样,之前在老师布置的作业里已经完成过了 这次基本就是重新熟悉一下 代码运行无误即可提交
作业三
要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
代码如下:
import re
import requests
def download_images(url, headers):
response = requests.get(url=url, headers=headers)
data = response.text
imagelist = re.findall('<img src="(.*?)" width="600".*?>', data)
for i in imagelist:
url2 = 'https://xcb.fzu.edu.cn/' + i
response2 = requests.get(url2)
imagename = url2[-20:]
with open("image1/" + f'/{y}.jpeg', 'wb') as f:
f.write(response2.content)
if __name__ == "__main__":
url = 'https://xcb.fzu.edu.cn/info/1071/4481.htm'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.31',
'cookie': 'JSESSIONID=46DED7706662743DF17EEC846E043D9B'
}
download_images(url, headers)
可发现在同一目录下的image1文件夹里爬到了八张图片

(3)心得:与之前实现的任务不同点在于这次爬取的是图片 需要另外找到分析的正则表达式 但是总体难度不大


