
腾讯云+阿里云 搭建hadoop + hbase
历时两天,踩了无数坑最后搭建成功。。。
准备
服务器配置
以下1-3步骤中两台服务器都要配置
1、修改hostname
主节点修改成master
从节点修改成slave1
使用命令:vim /etc/hostname
master
# or slave1
重启服务器:reboot
2、修改服务器hosts
假如主节点是阿里云。则在阿里配置
命令: vi /etc/hosts
ip master
ip1 slave1
其中 ip=阿里的内网ip;ip1=腾讯的外网ip
在腾讯配置
ip master
ip1 slave1
其中 ip=阿里的外网ip;ip1=腾讯的内网ip。
3、安装jdk1.8,并配置环境变量
4、ssh配置(master主机)
输入命令生成密匙对
ssh-keygen -t rsa
一路回车
上述命令将在/root/.ssh目录下生成公钥文件id_rsa.pub。将此文件拷贝到.ssh目录下的authorized_keys:
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
使用ssh登录本机

将公钥复制到从节点
ssh-copy-id -i ~/.ssh/id_rsa.pub root@slave1
可能需要输入从节点密码。
完成后确保从master免密码登录到slave1

对服务的配置就完成了,接下了配置hadoop。
hadoop
在master构建好hadoop,然后利用ssh分发到slave。所以下面配置在master进行
在home创建hadoop目录和配置文件路径
cd /home/
mkdir hadoop
cd hadoop
mkdir hadoop_data
cd hadoop_data
mkdir tmp
mkdir hdfs
cd hdfs
mkdir data
mkdir name
1、下载并解压:
可以使用wget下载或者上传都可以。
tar zxvf hadoop-2.7.3.tar.gz -C /home/hadoop/
2、 配置hadoop
hadoop配置文件路径 /home/hadoop/hadoop-2.7.3/etc/hadoop
hadoop-env.sh
修改JAVA_HOME。jdk路径
vi /home/hadoop/hadoop-2.7.3/etc/hadoop/hadoop-env.xml
export JAVA_HOME=/usr/local/jdk1.8.0_171
core-site.xml
vi /home/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/hadoop_data/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
</configuration>
hdfs-site.xml
vi /home/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
<description>备份namenode的http地址</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hjh/hadoop_data/hdfs/name</value>
<description>namenode的目录位置</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hjh/hadoop_data/hdfs/data</value>
<description>datanode's address</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>hdfs系统的副本数量</description>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
yarn-site.xml
vi /home/hadoop/hadoop-2.7.3/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
mapred-site.xml
vi /home/hadoop/hadoop-2.7.3/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指明mapreduce的调度框架为yarn</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
<description>指明mapreduce的作业历史地址</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
<description>指明mapreduce的作业历史web地址</description>
</property>
salve
vi /home/hadoop/hadoop-2.7.3/etc/hadoop/salve
master
slave1
该文件指定datanode从节点所在的服务器ip,这里只有两台服务器,所以将主节点master也加上去)
配置环境变量(方便后续操作)
vim /etc/profile
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin . source /etc/profile
最后copy这个hadoop给slave1
scp -r /home/hadoop/hadoop-2.7.3 root@slave1:/home/hadoop/
启动hadoop
以下在master进行
1、先格式化namenode
hadoop namenode -format
2、启动hadoop
./start-all.sh
执行:jps,查看相关进程
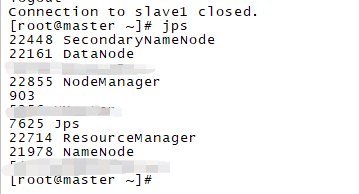
在slave1执行jps,
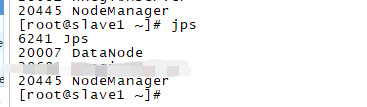
如果相关进程没有启动则去查看logs对应的模块的日志。准备埋坑。
在hdfs创建目录试试:
在master
hdfs dfs -ls /
hdfs是空的没有返回任何东西。
创建目录test
hdfs dfs -mkdir /test
hdfs dfs -ls /

在slave1中同样可以看到test

至此hadoop搭建完成。
hbase
在master构建,然后分发到slave
1、下载并解压:
可以使用wget下载或者上传都可以。
tar zxvf hbase-1.2.4.tar.gz -C /home/hadoop/
2、 配置hbase
hbase配置文件路径 /home/hadoop/hbase-1.2.4/conf
复制hadoop的hdfs-site.xml和core-site.xml到conf
cp -u /home/hadoop/hadoop-2.7.3/etc/hadoop/hdfs-site.xml /home/hadoop/hbase-1.2.4/conf
cp -u /home/hadoop/hadoop-2.7.3/etc/hadoop/core-site.xml /home/hadoop/hbase-1.2.4/conf
hbase-env.sh
vi /home/hadoop/hbase-1.2.4/conf/hbase-env.sh
由于使用jdk1.8 将如下注释

#配置jdk环境
export JAVA_HOME=/usr/local/jdk1.8.0_171
#配置zookeeper,true则说明使用hbase内置的zookeeper,false则说明使用单独的zookeeper集群
export HBASE_MANAGES_ZK=true
hbase-site.xml
vi /home/hadoop/hbase-1.2.4/conf/hbase-site.xml
<!--这是regionServer的共享目录,用来持久化hbase的,端口默认9000-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<!--hbase的运行模式,false是单机模式,true是分布式模式;
若设置为false,hbase和zookeeper会运行在同一个JVM里面-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--hbase主节点的端口,默认60000-->
<property>
<name>hbase.master</name>
<value>master:60000</value>
</property>
<!--zookeeper集群的地址列表,用逗号分割,默认localhost,这里的机器太少所以只用了一个zookeeper。否则会出错-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>master</value>
</property>
regionservers
vi /home/hadoop/hbase-1.2.4/conf/regionservers
master
slave1
最后分发个slave1
scp -r /home/hadoop/hbase-1.2.4 root@slave1:/home/hadoop/
在master 启动hbase
在hbase/bin 下启动hbase
./start-hbase.sh
master运行jps查看相关进程
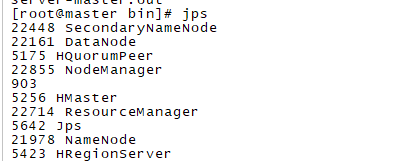
slave1
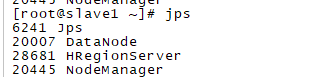
出错看logs查看那个模块出问题。
运行hbase shell
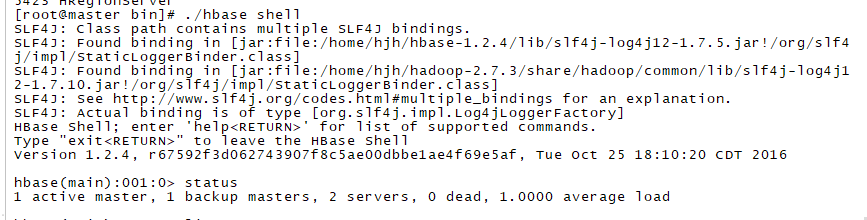
整个hadoop + hbase 就搭建好了
JAVA测试
/**
* @Description:
* @Author: HJH
* @Date: 2019-09-04 17:06
*/
public class HBaseConn {
private static final HBaseConn INSTANCE = new HBaseConn();
private static Configuration configuration;
private static Connection connection;
private HBaseConn() {
try {
if (configuration == null) {
configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "ip"); //master ip
System.setProperty("hadoop.home.dir", "E:\\hadoop-2.7.3");
configuration.set("hbase.zookeeper.property.clientPort","2181"); //端口号
}
} catch (Exception e) {
e.printStackTrace();
}
}
private Connection getConnection() {
if (connection == null || connection.isClosed()) {
try {
connection = ConnectionFactory.createConnection(configuration);
} catch (Exception e) {
e.printStackTrace();
}
}
return connection;
}
public static Connection getHBaseConn() {
return INSTANCE.getConnection();
}
public static Table getTable(String tableName) throws IOException {
return INSTANCE.getConnection().getTable(TableName.valueOf(tableName));
}
public static void closeConn() {
if (connection != null) {
try {
connection.close();
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
}
}
public class HBaseUtil {
public static void main(String[] args) {
createTable("FileTable", new String[]{"fileInfo", "saveInfo"});
}
/**
* 创建TABLE
* @param tableName 表名
* @param cfs 列族
* @return 是否创建成功
*/
public static boolean createTable(String tableName, String[] cfs) {
try (HBaseAdmin admin = (HBaseAdmin) HBaseConn.getHBaseConn().getAdmin()) {
if (admin.tableExists(tableName)) {
return false;
}
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf(tableName));
Arrays.stream(cfs).forEach(cf -> {
HColumnDescriptor columnDescriptor = new HColumnDescriptor(cf);
columnDescriptor.setMaxVersions(1);
tableDescriptor.addFamily(columnDescriptor);
});
admin.createTable(tableDescriptor);
} catch (Exception e) {
e.printStackTrace();
}
return true;
}
创建成功


