软件工程实践之词频统计
Github:https://github.com/1561602610/PersonProject-C2
PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 720 | 1000 |
| Development | 开发 | 600 | 900 |
| • Analysis | • 需求分析 (包括学习新技术) | 180 | 210 |
| • Design Spec | • 生成设计文档 | 40 | 50 |
| • Design Review | • 设计复审 | 30 | 60 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 10 | 30 |
| • Design | • 具体设计 | 30 | 50 |
| • Coding | • 具体编码 | 180 | 260 |
| • Code Review | • 代码复审 | 30 | 40 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 200 |
| Reporting | 报告 | 120 | 100 |
| • Test Repor | • 测试报告 | 30 | 20 |
| • Size Measurement | • 计算工作量 | 30 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 60 | 50 |
| 合计 | 720 | 1000 |
需求分析
-
统计文件的字符数:
- 只需要统计Ascii码,汉字不需考虑
- 空格,水平制表符,换行符,均算字符
-
统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 英文字母: A-Z,a-z
- 字母数字符号:A-Z, a-z,0-9
- 分割符:空格,非字母数字符号
- 例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
- 统计文件的有效行数:任何包含非空白字符的行,都需要统计。
- 统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
计算模块接口的设计与实现过程
实现字符计数:
#include "CharNum.h"
#include<fstream>
#include<iostream>
int CharNum(char * filename)
{
int count = 0;
char ch;
FILE *file;
fopen_s(&file,filename, "rt");
for (; (ch=fgetc(file)) != EOF;)
{
if (ch >= 0&&ch <= 255)
count++;
}
fclose(file);
return count;
}
实现单词计数:
#include"WordNum.h" int WordNum(char * filename) { map<string, int> Word_Num_map; char ch; FILE *file; fopen_s(&file, filename, "rt"); int flag = 0; int count = 0; for (; (ch = fgetc(file)) != EOF;) { if ((ch >= 97 &&ch <= 122 )|| (ch >= 65 && ch <= 90))//英文字母 { if (flag >= 0)flag++; if (flag < 0)flag--; } else if (ch >= 48 && ch <= 57)//数字 { if (flag >= 4)flag++; else flag = -1; } else //非字母数字符号 { if (flag >= 4) { count++; flag = 0; } else { flag = 0; } } } fclose(file); return count; }
实现行数计数:
#include "LineNum.h" int LineNum(char * filename) { FILE *file; fopen_s(&file,filename, "rt"); int count = 0; char ch; int flag = 0; for (; (ch = fgetc(file)) != EOF;) { if (ch == '\n') { if (flag > 0)count++; flag = 0; } else if (ch != ' '&&ch!='\t') { flag++; } }if (flag > 0)count++; fclose(file); return count; }
实现词频统计及输出前十名:
#include"Word_Fre.h" typedef pair<string, double> PAIR; bool CmpByValue(const PAIR& lhs, const PAIR& rhs) { return (lhs.second != rhs.second) ? lhs.second > rhs.second : lhs.first < rhs.first; } int Word_Fre(char * filename) { map<string, int> Word_Num_map; char ch; string word; int flag = 0; FILE *file; fopen_s(&file, filename, "r"); for (; (ch = fgetc(file)) != EOF;) { if ('A' <= ch && ch <= 'Z') ch = ch + 32; if (ch >= 'a' && ch <= 'z')//英文字母 { if (flag >= 0) { flag++; word = word + ch; } if (flag < 0) { flag = 0; word = ""; } } else if (ch >= 48 && ch <= 57)//数字 { if (flag >= 4) { flag++; word = word + ch; } else { flag = 0; word = ""; } } else //非字母数字符号 { if (flag >= 4) { Word_Num_map[word]++; word = ""; flag = 0; } else { flag = 0; word = ""; } } } if (flag >= 4) { Word_Num_map[word]++; } vector <PAIR> Word_Num_vec(Word_Num_map.begin(), Word_Num_map.end()); sort(Word_Num_vec.begin(), Word_Num_vec.end(), CmpByValue); if (Word_Num_vec.size() < 10) for (int i = 0; i != Word_Num_vec.size(); ++i) { const char *ss = Word_Num_vec[i].first.c_str(); cout << '<' << ss << '>' << ":" <<' '<< Word_Num_vec[i].second << endl; } else for (int i = 0; i != 10; ++i) { const char *ss = Word_Num_vec[i].first.c_str(); cout << '<' << ss << '>' << ":" <<' '<< Word_Num_vec[i].second << endl; } return 0; }
主要解题思路:
设置标志位flag用于判断该位是否为单词的组成部分。
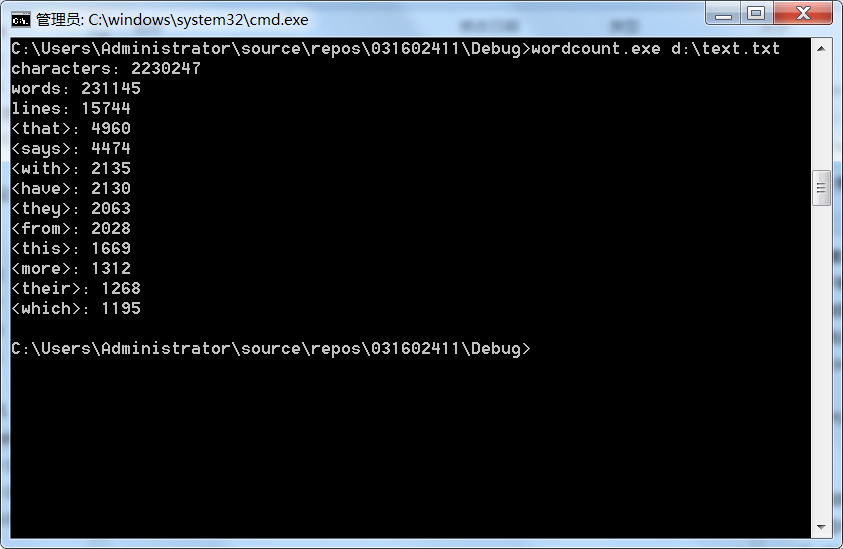
测试样例:
测试文本:

测试结果:
心路历程与收获:
在努力完成这次实践的过程中,遇到了很多问题,首先的问题就是关于文件读取的问题,在遇到一个个问题的时候四处查找资料、请教同学,感觉确实有在学到东西。
在解决词频统计这个问题上花了很长的时间,主要是用于思考记录单词及其频率的方法,后来查找以及问同学相关问题,知道了map这个东东还有一堆奇奇怪怪的函数,实在是后悔没好好学C++和数据结构。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号