机器学习:Kmeans练习
实验介绍
1.实验内容
- 通过对给定数据进行聚类分析来了解K-means算法。
2.实验目标
- 通过本实验掌握K-means聚类算法
3.实验知识点
- K-means算法原理
- K-means算法流程
- K-means算法应用
4.实验环境
- python 3.6.5
- numpy 1.13.3
- matplotlib 2.2.3
实验准备
点击屏幕右上方的下载实验数据模块,选择下载KmeansData.txt到指定目录下,然后再依次选择点击上方的File->Open->Upload,上传刚才下载的数据集
数据介绍
本数据是随机生成的符合高斯分布的二维样本点
[K-means] 实验流程
import numpy as np
import matplotlib.pyplot as plt
1. 数据的读取与处理
def loadDataSet(fileName):
#初始化空列表
dataSet = []
#读取文件
fr = open(fileName)
# 循环遍历文件所有行
for line in fr.readlines():
# 切割每一行的数据
curLine = line.strip().split('\t')
# 将数据转换为浮点类型,便于后面的计算
# fltLine = [float(x) for x in curLine]
# 将数据追加到dataMat
fltLine = list(map(float,curLine)) # 映射所有的元素为 float(浮点数)类型
dataSet.append(fltLine)
# 返回dataMat
return np.matrix(dataSet)
2. 样本点间的距离计算
def distEclud(vecA, vecB):
return np.sqrt(sum(np.power(vecA - vecB, 2)))
"""
函数说明:利用欧式距离来计算每个样本点之间的距离
parameters:
vecA - A样本的特征向量(本数据中指它的二维坐标值)
vecB - B样本的特征向量(本数据中指它的二维坐标值)
return:
Dist - 样本点间的欧式距离
"""
3. 簇中心的初始化
def randCent(DataMat, k):
"""
函数说明:从当前样本点中随机选取k个初始簇中心
parameters:
DataMat - 数据集
k - 聚类后簇的数量
return:
centroids - 簇中心列表
"""
# 获取样本数与特征值
m, n = np.shape(dataMat)
# 初始化质心,创建(k,n)个以零填充的矩阵
centroids = np.mat(np.zeros((k, n)))
# 循环遍历特征值
for j in range(n):
# 计算每一列的最小值
minJ = min(dataMat[:, j])
# 计算每一列的范围值
rangeJ = float(max(dataMat[:, j]) - minJ)
# 计算每一列的质心,并将值赋给centroids
centroids[:, j] = np.mat(minJ + rangeJ * np.random.rand(k, 1))
# 返回质心
return centroids
4. K-means的中心思想实现---即通过不断更新簇中心,把与各个簇中心距离相近的样本点归为一类
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
"""
函数说明:K-均值算法
parameters:
dataSet -数据集
k -簇个数
distMeas -距离计算函数
createCent -创建初始质心函数
return:
centroids -质心列表
clusterAssment -簇分配结果矩阵
"""
# 获取样本数和特征数
m, n = np.shape(dataMat)
# 初始化一个矩阵来存储每个点的簇分配结果
# clusterAssment包含两个列:一列记录簇索引值,第二列存储误差(误差是指当前点到簇质心的距离,后面会使用该误差来评价聚类的效果)
clusterAssment = np.mat(np.zeros((m, 2)))
# 创建质心,随机K个质心
centroids = createCent(dataMat, k)
# 初始化标志变量,用于判断迭代是否继续,如果True,则继续迭代
clusterChanged = True
while clusterChanged:
clusterChanged = False
# 遍历所有数据找到距离每个点最近的质心,
# 可以通过对每个点遍历所有质心并计算点到每个质心的距离来完成
for i in range(m):
minDist = np.inf
minIndex = -1
for j in range(k):
# 计算数据点到质心的距离
# 计算距离是使用distMeas参数给出的距离公式,默认距离函数是distEclud
distJI = distMeas(centroids[j, :], dataMat[i, :])
# 如果距离比minDist(最小距离)还小,更新minDist(最小距离)和最小质心的index(索引)
if distJI < minDist:
minDist = distJI
minIndex = j
# 如果任一点的簇分配结果发生改变,则更新clusterChanged标志
if clusterAssment[i, 0] != minIndex: clusterChanged = True
# 更新簇分配结果为最小质心的index(索引),minDist(最小距离)的平方
clusterAssment[i, :] = minIndex, minDist ** 2
# print(centroids)
# 遍历所有质心并更新它们的取值
for cent in range(k):
# 通过数据过滤来获得给定簇的所有点
ptsInClust = dataMat[np.nonzero(clusterAssment[:, 0].A == cent)[0]]
# 计算所有点的均值,axis=0表示沿矩阵的列方向进行均值计算
centroids[cent, :] = np.mean(ptsInClust, axis=0)
# 返回所有的类质心与点分配结果
return centroids, clusterAssment
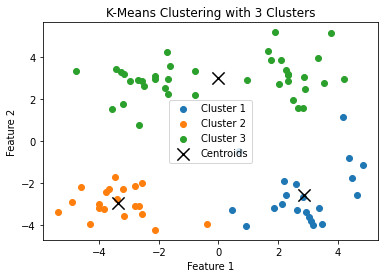
5. 实验结果的可视化
def drawDataSet(dataMat, centList, clusterAssment, k):
"""
函数说明:将聚类结果可视化
parameters:
centList -质心列表
clusterAssment -簇列表
dataMat -数据集
k -簇个数
return:
A picture
"""
m, n = np.shape(dataMat)
# 创建一个画布
plt.figure()
# 用不同的颜色绘制不同簇的点
for i in range(k):
# 找到属于第i簇的数据点
ptsInClust = dataMat[np.nonzero(clusterAssment[:, 0].A == i)[0]]
# 使用不同颜色绘制每个簇的数据点
plt.scatter(ptsInClust[:, 0].A[:, 0], ptsInClust[:, 1].A[:, 0], label=f'Cluster {i+1}')
# 绘制质心的位置
centroids = np.array(centList)
plt.scatter(centroids[:, 0], centroids[:, 1], marker='x', s=150, color='black', label='Centroids')
# 添加图例
plt.legend()
# 添加标题和轴标签
plt.title(f'K-Means Clustering with {k} Clusters')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
# 显示图像
plt.show()
6. 主函数调用上述函数
if __name__ == '__main__':
# 载入数据集
fileName = 'KmeansData.txt'
dataMat = loadDataSet(fileName)
# 设置簇的数量 k
k = 3 # 假设我们希望聚成 3 个簇
# 执行K-Means聚类
centroids, clusterAssment = kMeans(dataMat, k)
# 可视化聚类结果
drawDataSet(dataMat, centroids, clusterAssment, k)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通