
Mysql基础(一)安装与基本使用
一、安装(解压版)
官网下载地址:https://dev.mysql.com/downloads/mysql/
1、解压到英文路径下的目录
2、配置环境变量:mysql的解压路径(安装路径) + \bin
3、在mysql的安装路径下创建my.ini文件
[ client ]
port=3306
default-character-set=utf8
[ mysqld ]
# 设置mysql安装目录
basedir=mysql的安装目录
# 设置mysql的数据目录,系统会创建,不需要自己手动创建
datadir=mysql的安装目录\data\
port=3306
character_set_server=utf8
# 跳过安全检查
skip-grant-tables
4、以管理员的方式打开cmd,切换到mysql的安装目录下,执行下面命令
# 安装mysql服务
mysqld -install
# 提示:Service successfully installed. 为安装成功
# 初始化数据库,生成data目录
mysqld --initialize-insecure
#启动mysql服务
net start mysql
#停止mysql服务
net stop mysql
5、进入mysql服务端以及修改密码
#登录mysql客户端
mysql -u root -p
# 使用mysql这个数据库
use mysql;
#修改密码
update user set authentication_string=password('123456') where user='root' and Host='localhost';
#修改完成后刷新权限
flush privileges;
#退出mysql终端
quit;
6、注销my.ini文件中的skip-grant-tables
# 将my.ini文件的skip-grant-tables注销
# skip-grant-tables
# 重启mysql服务
net stop mysql
net start mysql
# 使用密码进行登录
# 第一种方式,直接在后面写上密码
mysql -u root -p123456
# 第二种方式,先执行下面这条语句,回车后再写密码
mysql -u root -p
提醒:使用命令连接Mysql服务
mysql -h 主机IP -P 端口 -u 用户名 -p密码
1、-p密码后面不能有空格
2、-p后面没有写密码,回车会要求输入密码
3、如果没有写-h 主机ip,默认就是本机ip
4、如果没有写 -P端口,默认就是3306端口,实际工作中,3306端口是会进行修改的
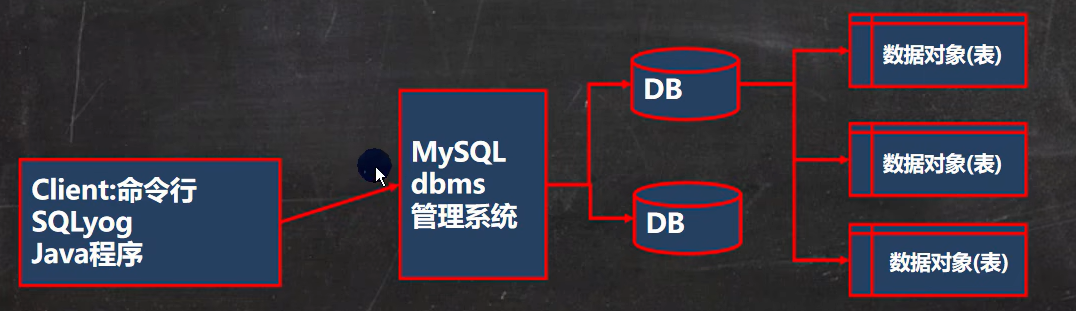
二、数据库三层结构
1、所谓安装Mysql数据库,就是在主机安装一个数据库管理系统(DBMS),这个管理程序可以管理多个数库。DBMS(database manage system)
2、一个数据库中可以创建多个表,以保存数据(信息)。
3、数据库管理系统(DBMS)、数据库和表的关系
SQL语句分类
- DDL:数据定义语句 [创建表(create 表),库]
- DML:数据操作语句 [增加,修改,删除]
- DQL:数据查询语句 [select]
- DCL:数据控制语句 [管理数据库:比如用户权限 grant(赋予) revoke(撤回)]
三、数据库的基本操作
1、创建数据库
create database [if not exists] db_name
[create_specification[,create_specification]...]
create_specification;
[default]character set charset_name | default collate collation_name
1、character set:指定数据库采用的字符集,如不指定字符集,默认采用utf8
2、collate:指定数据库字符集的校对规则(常用的utf8_bin [区分大小写]、utf8_general_ci [不区分大小写] 注意默认的是 utf8_general_ci)
举例:
1、创建一个名为 test_db01的数据库
create database test_db01;
2、创建一个使用utf8字符集的test_db02数据库
create database test_db02 character set utf8;
3、创建一个使用utf8字符集,并带校对规则的test_db03数据库
create database test_db03 character set utf8 collate utf8_general_ci;
注意点:
utf8_bin [区分大小写] 与 utf8_general_ci [不区分大小写] 的区别
1、如果创建表时没有指定字符集和校对规则,那么这个表就以当前的数据库的字符集和校对规则为准
2、举例
在使用 utf8_bin 的表中添加两条数据
insert into `user` values(1,'tom'),(2,'Tom')
之后执行查询语句
select * from `user` where name = 'tom'
结果只能查出一条数据
在使用 utf8_general_ci 后,以同样的方式添加两条数据,查询出的结果时两条数据
3、在创建数据库时,为了避免关键字,可以使用反引号解决 ``
2、查看、删除数据库
1、显示数据库语句
show databases
2、显示数据库创建语句
show create database db_name
3、数据库删除语句(一定要慎用)
drop database [if exists] db_name
3、数据库备份与恢复
备份数据库(注意:DOS执行)命令行
mysqldump -u 用户名 -p -B 数据库1 数据库2 数据库n > 文件名.sql
恢复数据库
练习:
1、备份数据库 test_db02 和 test_db03,在mysql安装目录的bin目录下打开cmd,执行命令
# 该命令的意思就是将数据库 test_db02 test_db03 备份到d盘下的back.sql文件中
mysqldump -u root -p -B test_db02 test_db03 > d:\\back.sql
2、恢复数据库
使用dos命令,通过cmd登录mysql客户端
# 执行命令
source d:\\back.sql
四、数据表的基本操作
1、常用数据类型
| 分类 | 数据类型 | 说明 |
|---|---|---|
| 数值类型 | bit(M) | 位类型。M指定位数,默认值1,范围1-64 |
| 数值类型 | tinyint [unsigend] 占1个字节 | 带符号的范围时-128到127,无符号0到255。默认时有符号 |
| 数值类型 | smallint [unsigend] 占2个字节 | 带符号时负的2^15 到 215-1,无符号0到216-1 |
| 数值类型 | mediumint [unsigend] 占3个字节 | 带符号时负的2^23 到 223-1,无符号0到224-1 |
| 数值类型 | int [unsigend] 占4个字节 | 带符号时负的2^31 到 231-1,无符号0到232-1 |
| 数值类型 | bigint [unsigend] 占8个字节 | 带符号时负的2^63 到 263-1,无符号0到264-1 |
| 数值类型 | float [unsigend] | 占用空间4个字节 |
| 数值类型 | double [unsigend] | 表示比float精度更大的小数,占用空间8个字节 |
| 数值类型 | decimal(M,D) [unsigend] | 定点数M指定长度,D表示小数点位数 |
| 文本、二进制类型 | char(size) char(20) | 固定长度字符串,最大255 |
| 文本、二进制类型 | varchar(size) varchar(20) | 可变长度字符串 0~65535 即:2^16-1 |
| 文本、二进制类型 | blob longblob | 二进制数据blob长度为[ 0 ~ 2^16-1] longblob [ 0 ~ 2^32-1] |
| 文本、二进制类型 | text longtext | 文本 text 0~2^16 longtext 0~2^32 |
| 时间日期类型 | date/datetime/TimeStamp | 日期类型(YYYY-MM-DD)/(YYYY-MM-DD HH:MM:SS)/TimeStamp表示时间戳,它可以用于自动记录insert、update操作的时间 |
2、创建表
create table table_name(
field1 datatype,
field2 datatype,
field3 datatype,
)character set 字符集 collate 校对规则 engine 引擎(存储引擎)
filed:指定列明(字段名)
datatype:指定列类型(字段类型)
character set:如不指定则为所在数据库字符集
collate:如不指定则为所在数据库校对规则
engine:引擎
注意:创建表时,要根据需保存的数据创建相应的列,并根据数据类型定义相应的列类型
练习:
create table user_info(
id int,
`name` varchar(255),
`password` varchar(255),
`birthday` date
)character set utf8 collate utf8_general_ci engine innodb;
3、数据类型建表
1、tinyint类型
-
有符号的范围 -128 ~ 127 ,没有符号的 0 ~ 255
-
如果没有指定 unsinged ,则 tinyint 就是有符号的
如何定义一个无符号的
# 定义有符号的,默认时有符号
create table t3(
id tinyint
);
# 定义无符号字段
create table t4(
id tinyint unsigned
);
2、bit类型
细节说明:
- bit字段显示时,按照位的方式显示
- 查询的时候仍然可以使用添加的数值
- 如果一个值只有0,1可以考虑使用 bit(1),可以节约空间
- 位类型。M指定位数,默认值为 1,范围 1- 64
- 使用不多
- 添加的数据按照给定的位数比如 M = 8,表示一个字节 0~255
- 查询时仍然可以按照数来查询
create table t5(
num bit(8)
);
insert into t5 values(255);
select * from t5;
3、数值型(小数)的基本使用
1、float单精度 [UNSIGNED]
2、double双精度 [UNSIGNED]
3、decimal[M,D] [UNSIGNED]
- 可以支持更加精确的小数位。M是小数位数(精度的总数),D是小数点(标度)后面的位数
- 如果D是0,则值没有小数点或分数部分,M最大65,D最大是30。如果D被省略,默认是0,如果M被省略,默认是10
- 建议:如果希望小数精度高,推荐使用decimal
create table t6 (
num1 float,
num2 double,
num3 decimal(30,20)
)
insert into t6 values(88.135345236456436534,88.135345236456436534,88.135345236456436534)
select * from t6
4、字符串的基本使用
1、char(size)
固定长度字符串,最大255字符
create table t9(
`name` char(255)
);
2、varchar(size) 如果用utf8编码时,size的最大能写到21844,如果编码发生变化,size的大小也会发生变化
可变长度字符串,最大65532字节 ,utf8编码最大21844字符 1-3个字节用于记录大小,也就是要预留出1-3个字节
-- 编码utf8,varchar的size大小计算 size = (65535-3) / 3 = 21844
create table t10(
`name` varchar(21844)
)
-- 编码gbk,varchar的size大小计算 size = (65535-3) / 2 = 32766
create table t11(
`name` varchar(32766)
)character set gbk;
使用细节:
1、char(4) 这个4表示字符数(最大255),不是字节数,不管是中文还是字母都是放四个,按照字符计算
2、varchar(4) 这个4表示字符数,不管是字母还是中文都以定义好的表的编码来存放数据,如果是utf8的编码,那就按照utf8的编码格式进行存放,如果是gbk,那就按照gbk的编码存放,字符占用多少个字节由编码决定
3、不管是中文还是英文字母,都是最多存放4个,按照字符来存放的
-- 不区分英文还是中文,占4个字符
create table t12(
`name` char(4)
);
-- 成功
insert into t12 values('abcd')
insert into t12 values('你好世界')
-- 失败,超过长度
insert into t12 values('abcde')
insert into t12 values('你好啊世界')
select * from t12
-- 不区分英文还是中文,占4个字符
create table t13(
`name` varchar(4)
)
-- 成功
insert into t13 values('abcd')
insert into t13 values('你好世界')
-- 失败,超过长度
insert into t13 values('abcde')
insert into t13 values('你好啊世界')
select * from t13
4、char(4) 是定长(固定大小),就是说,即使插入 ‘aa’ 两个字符,也会占用分配的4个字符
5、varchar(4) 是变长(变化大小),就是说,如果插入 ‘aa’,实际占用空间大小并不是4个字符,而是按照实际占用空间来分配,varchar本身还需要占用1-3个字节来记录存放内容长度 L(实际数据大小) + (1到3个字节)
6、char 和 varchar 的使用场景
- 如果数据定长,推荐使用char,比如md5的密码、邮箱、手机号、身份证号码等 char(32)
- 如果一个字段的长度不确定,那就使用varchar,比如留言,文章等
- 查询速度:char 大于 varchar
7、在存放文本时,也可以使用text数据类型,可以将text列视为varchar列,注意text不能有默认值,大小 0-2^16 字节,如果希望存放更多细节,可以选择 mediumtext 0-2^24 或者 longtext 0-2^32
create table t14 (
content text,
content1 mediumtext,
content2 longtext
)
5、日期类型的基本使用
1、date类型
2、datetime类型
3、TimeStamp类型(时间戳)
细节说明:
TimeStamp类型(时间戳)在insert和update时,自动更新
create table t15(
birthday date, -- 年月日
jobtime datetime, -- 年月日 时分秒
login_time timestamp not null default current_timestamp on update current_timestamp -- 配置需要自动更新
);
select * from t15
insert into t15(birthday,jobtime) values('2022-11-11','2022-11-11 10:10:10')
6、练习
创建一张员工表,要求如下
| 字段 | 属性 |
|---|---|
| id | 整形 |
| name | 字符型 |
| sex | 字符型 |
| birthday | 日期型(date) |
| entry_date | 日期型(date) |
| job | 字符型 |
| salary | 小数型 |
| resume | 文本型 |
-- 建表
create table emp(
id int,
`name` varchar(32),
sex char(1),
birthday date,
entry_date datetime,
job varchar(32),
salary double,
resume text
)charset utf8 collate utf8_bin engine innodb;
-- 插入数据
insert into emp values(100,'您好','男','2022-11-11','2022-11-11 10:10:10','java开发',1200.67,'大家好,我是个开发工程师')
-- 查询
select * from emp
4、修改表
基本介绍
使用 alter table 语句最佳,修改或删除的语法
-- 添加列
alter table tablename add (column datatype [default expr] [,column datatype]...)
-- 修改列
alter table tablename modify (column datatype [default expr] [,column datatype]...)
-- 删除列
alter table tablename drop (column datatype [default expr] [,column datatype]...)
-- 查看表结构
desc 表名;
-- 修改表名
rename table 表名 to 新表名;
--修改字符集
alter table 表名 character set 字符集;
练习:
1、在员工表emp上增加一个新的image列,varchar类型(要求在resume后面)
alter table emp add image varchar(32) not null default '' after `resume`
2、修改job列,使其长度为60
alter table emp modify job varchar(60) not null default ''
3、删除sex列
alter table emp drop sex
4、修改表名为employee
rename table emp to employee
5、修改表的字符集为utf-8
alter table employee character set utf8
6、列名name修改为user_name
alter table employee change `name` user_name varchar(32) not null default ''
7、查看表结构
desc employee
8、删除表
drop table 表名;
五、CRUD语句
基本说明:
C [create]、R [read]、U[update]、D[delete]
1、insert语句
语法:
insert into table_name [(column [, column])] values(value [, value...])
示例:
创建一个商品表 goods(id,goods_name,price),向其中加入两条数据
create table `goods`(
id int,
goods_name varchar(10),
price double
)
insert into `goods`(id,goods_name,price)
values(10,'华为手机',12.7);
insert into `goods`(id,goods_name,price)
values(12,'苹果手机',12);
select * from `goods`
细节:
1、插入的数据应与字段的数据类型相同。比如把字符串 'abc' 添加到 int 类型会错误
-- 插入失败,mysql底层无法将 'abc' 转型为 int 类型数据
insert into `goods`(id,goods_name,price)
values('abc','小米手机',13)
-- 插入成功,mysql底层可以将 '30' 转型为 int 类型数据
insert into `goods`(id,goods_name,price)
values('30','小米手机',13)
2、数据的长度应在列的规定范围内,例如:不能将一个长度为80的字符串加入到长度为40的列中
insert into `goods`(id,goods_name,price)
values(40,'vivo手机vivo手机vivo手机vivo手机vivo手机vivo手机vivo手机vivo手机vivo手机vivo手机vivo手机',15)
--报错,因为goods_name的长度小于插入数据的长度
Data too long for column 'goods_name' at row 1
3、在values中列出的数据位置必须与被加入到列的排列位置相对应
-- 插入的数据顺序与字段顺序不一致,插入失败
insert into `goods`(id,goods_name,price)
values('联想手机',50,15.4)
-- 插入成功
insert into `goods`(id,goods_name,price)
values(50,'联想手机',15.4)
4、字符和日期类型数据应包含在单引号中
-- 字符类型,需要用引号''进行包裹,否则报错 Unknown column '红米手机' in 'field list',插入失败
insert into `goods`(id,goods_name,price)
values(60,红米手机,10)
--插入成功
insert into `goods`(id,goods_name,price)
values(60,'红米手机',10)
5、列可以插入空值,前提是该字段允许为空,insert into table value(null)
-- 允许插入null值,但是前提是创建表时该字段允许为null的情况下
insert into `goods`(id,goods_name,price)
values(70,'锤子手机',null)
6、insert into tab_name(列名.....) values(),(),()形式添加多条数据
-- 添加多条数据
insert into `goods`(id,goods_name,price)
values(1,'三星手机',12),(2,'四星手机',12),(3,'五星手机',12)
7、如果是给表中的所有字段添加数据,可以不写前面的字段名称
-- 插入失败,因为表的字段为3个,但只插入两个,没有对应
insert into `goods` values(21,'海尔手机')
-- 插入成功
insert into `goods` values(21,'海尔手机',10)
8、默认值的使用,当不给某个字段的值时,如果有默认值就会添加,否则就会报错
-- 插入成功,因为price字段默认为null,插入时只需要指定插入的字段,就会给没有指定的字段插入默认值
insert into `goods`(id,goods_name)
values(24,'海尔手机')
-- 修改字段的默认值
alter table `goods` modify goods_name varchar(12) not null default '默认手机'
-- 执行插入字段,goods_name没有传入,就会赋值默认值
insert into `goods`(id,price)
values(25,100)
2、update语句
语法:
update table_name set col_name1=expr1 [,col_name1=expr1...]
[where where_definition]
示例:
-- 准备测试表
create table emp(
id int,
emp_name varchar(32),
salary double
)
insert into emp(id,emp_name,salary)
values(1,'小王',4500),(2,'小红',3500),(3,'小李',4600)
-- 将所有员工的薪资修改为5000,没有带上限定条件 where,会修改表中所有数据
update emp set salary = 5000
-- 修改小王薪水为3000,添加限定条件,进行限定修改
update emp set salary = 3000 where emp_name = '小王'
-- 将小李的薪水在原来的基础上增加1000,在实际开发中可能不会知道salary旧的值,所以salary + 1000会获得新的值
update emp set salary = salary + 1000 where emp_name = '小李'
细节:
1、update语法可以用新值更新原有表行中的各个列
2、set子句表示要修改哪些列和要赋予哪些值
3、where字句指定应更新哪些,没有where字句,更新所有的行,在使用update更新时,一定要小新,加上where条件限定语句,除非需要修改的是表中的所有值
4,、如果需要修改多个字段的值,可以通过set 字段1 = 值1,字段2 = 值2...
-- 将小王的名字改为小黄,薪水在原来的基础上加上1000
update emp set emp_name = '小黄',salary = salary + 1000 where emp_name = '小王'
3、delete语句
语法:
delete from table_name
[where where_definition]
示例:
-- 删除表中小黄的记录
delete from emp where emp_name = '小黄'
-- 删除表中所有的记录
delete from emp
细节:
1、如果不适用where子句,将删除表中所有数据
2、delete语句不能删除某一列的值(可以使用update设为null或者 '')
3、使用delete语句仅删除记录,不能删除表本身。如果删除表,使用drop table 语句。drop table 表名
4、select语句
语法:
-- 基本查询
select [distinct] * | {column1,colunm2,colunm2...} from table_name
-- 使用表达式对查询的列进行运算
select * | {column1 | expression,column1 | expression...} from table_name
-- 在select语句中可以使用as语句
select columnname as 别名 from 表名
注意事项:
- select 指定查询哪些数据列
- column 指定列名
- *号代表查询所有列
- from指定查询哪张表
- distinct可选,指显示结果时,是否去掉重复数据
示例:
-- 准备表和数据
create table `student`(
id int not null default 1,
`name` varchar(32) not null default '',
chinese float not null default 0.0,
english float not null default 0.0,
math float not null default 0.0
)
insert into `student`
values(1,'张三',89,88,90),
(2,'李四',67,98,56),
(3,'王五',59,60,77),
(4,'赵六',89,88,87),
(5,'孙奇',55,90,73),
(6,'王飞',98,84,71),
(7,'谢安',90,58,66)
-- 查询表中所有的记录
select * from `student`
-- 查询表中所有学生的名字和语文成绩
select `name`,chinese from `student`
-- 去重,distinct 条件是查出来的这一行数据必须全部相同,才会进行去重
select distinct chinese from `student` --会去重
select distinct `name`,chinese from `student` --不会去重
-- 统计每个学生的总分
select `name`,(chinese+english+math) from `student`
-- 在每个学生的总分上加10分
select `name`,(chinese+english+math+10) from `student`
-- 别名,别名可以是英文也可以是中文
select `name` as 名字,(chinese+english+math) as total_score from `student`
select语句中的运算符
| 运算符类型 | 运算符 | 说明 |
|---|---|---|
| 比较运算符 | > < <= >= = <> != | 大于,小于,大于(小于)等于,不等于 |
| 比较运算符 | between....and... | 显示在某一区间的值 |
| 比较运算符 | in(set) | 显示在in列表中的值,例如:in(100,200) |
| 比较运算符 | like 张pattern、not like '' |
模糊查询 |
| 比较运算符 | is null | 判断是否为空 |
| 逻辑运算符 | and | 对个条件同时成立 |
| 逻辑运算符 | or | 多个条件任一条件成立 |
| 逻辑运算符 | not | 不成立,例:where not (salary > 100) |
示例:
-- 查询姓名为张三的学生成绩
select * from `student` where `name` = '张三'
-- 查询英语成绩大于90分的同学
select * from `student` where english > 90
-- 查询总分大于260分的同学
select * from `student` where (chinese+english+math) > 260
-- 查询math大于60并且id大于4的学生成绩
select * from `student`
where math > 60 and id > 4
-- 查询英语成绩大于语文成绩的学生
select * from `student`
where english > chinese
-- 查询总分大于200分并且数学成绩小于语文成绩并且姓张的的学生
-- 这里的%号代表的是0到多,通配符
select * from `student` where (chinese+english+math) > 200 and math < chinese and `name` like '张%'
-- 查询英语成绩 80-90 之间的学生 两种写法
select * from `student`
where english >= 80 and english <= 90
select * from `student`
where english between 80 and 90
-- 查询数学分数为89,90,91的同学 两种写法
select * from `student`
where math = 89 or math = 90 or math = 91
select * from `student`
where math in(89,90,91)
-- 查询所有姓张的学生 模糊查询
select * from `student`
where `name` like '张%'
-- 查询数学分数>80,语文分数>80的同学
select * from `student`
where math > 80 and chinese > 80
-- 练习
-- 查询语文分数在 60-80 之间的同学 两种写法
select * from `student`
where chinese >= 60 and chinese <= 80
select * from `student`
where chinese between 60 and 80
-- 查询总分为250,260,270的同学 两种写法
select * from `student`
where (math+chinese+english) = 250 or (math+chinese+english) = 260 or (math+chinese+english) = 270
select * from `student`
where (math+chinese+english) in(250,260,270)
-- 查询所有姓李 或者 姓张的学生
select * from `student`
where `name` like '李%' or `name` like '张%'
-- 查询数学比语文多30分的同学
select * from `student`
where chinese+30 < math
order by 子句的使用
语法:
select column1,column1,column1... from table_name order by column asc|desc
说明:
- order by 指定排序的列,排序的列既可以是表中的列名,也可以是select语句后指定的列名
- asc 升序[默认]、desc降序
- order by 子句应位于select语句的结尾
示例:
-- 对数学成绩排序后输出 升序
select * from `student` order by math
-- 对总分按从高到低的顺序输出 降序 可以使用别名进行排序
select `name`,(chinese+math+english) as total_score from `student` order by total_score desc
-- 对姓李的学生成绩排序输出 升序
select `name`,(chinese+math+english) as total_score from `student` where `name` like '李%' order by total_score asc

 浙公网安备 33010602011771号
浙公网安备 33010602011771号