吴恩达机器学习笔记|(10)推荐系统(Recommendeder-System)
1. 基于内容的推荐系统(Content-based recommender systems)
如将每部电影的内容划分为爱情元素(romance) \(x_1\) +动作元素(action)\(x_2\) ,并且有一定的数值描述该电影成分。根据用户对电影的评价分数及相应电影的内容分布情况训练某个用户对于电影评价的相关参数,并用其预测该用户对其它电影的评价分数(个性化)。
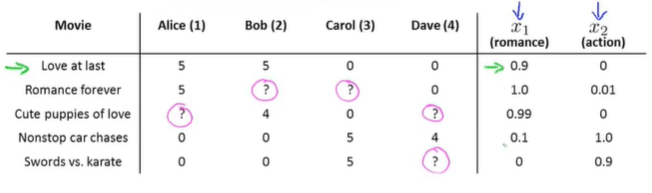
训练过程:简单地,同样可用使用类似于线性回归的方式,通过最小化平方误差和来寻找最合适的参数 \(\theta\) 。为了防止过拟合还可以加入正则化。得到类似下面的一个公式:
Given \(x^{(i)}\) ,to learn \(\theta\)
-
针对单个用户的参数估计:\(\theta^{(j)}\in\mathbb{R}^{n+1}\) ,n是电影特征数量,1是偏置项。
![]()
其中 \(r(i,j)=1\) 指的是用户评价过的电影(未评价的值为0)。注意与线性回归不同,这里计算的是 平方误差和 而非 均方误差和,其实就是去掉 了 \(\frac{1}{2m}\) 项,只是为了后面的公式更为简化,对参数训练没有影响。
-
针对所有用户的参数估计:\(\theta^{(1)},\ldots,\theta^{(n_u)}\)
![]()
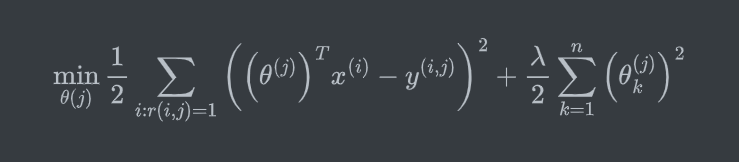
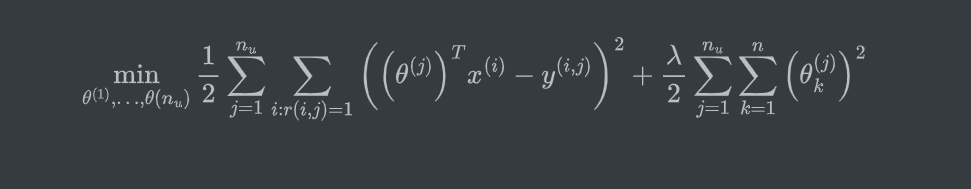
然后可用利用梯度下降求解。
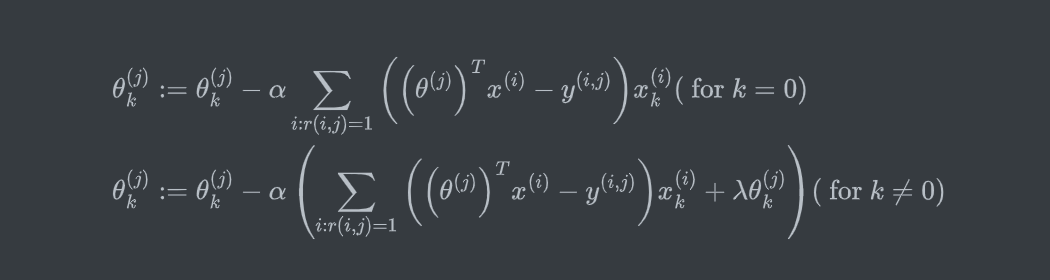
2. 协同过滤算法(Collaborative filtering algorithm)
基于内容的推荐系统存在一定缺陷,因为对于大多数电影或者需要销售的商品来说,很难用完整并且量化的特征量去概括或者描述,于是有了协同过滤算法推荐系统,该系统能自动学习所要使用的特征,并同时利用特征和用户的喜好参数以及评分进行协同过滤。
特征学习算法
该算法的前提:用户已经告诉系统他们的偏好。 即模型参数 \(\theta\) 和一部分电影评分已知。
作用:利用用户提供的信息(\(\theta\) 已知),对电影特征进行学习。
示例:电影推荐系统
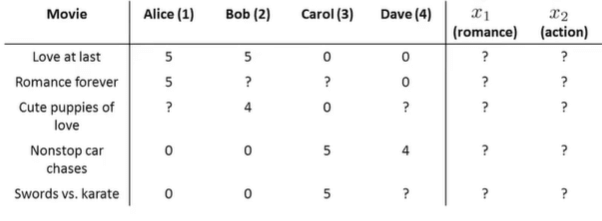
-
学习单个特征。Given \(\theta^{(1)},\ldots,\theta^{(n_u)}\) ,to learn \(x^{(i)}\) :
![]()
-
学习多个特征。Given \(\theta^{(1)},\ldots,\theta^{(n_u)}\) ,to learn \(x^{(1)},\ldots,x^{(n_m)}\) :
![]()
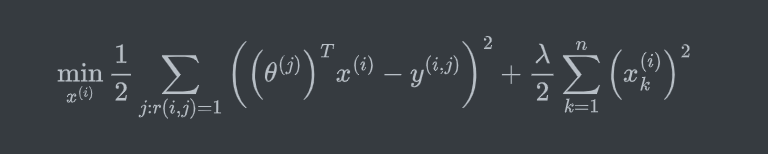
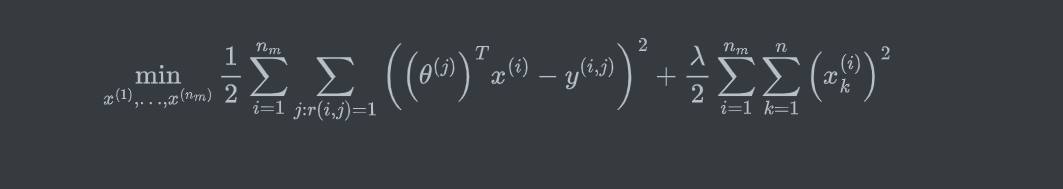
协同过滤算法
已知通过给定的电影特征 \(x\) 以及电影评分可以估计用户偏好参数 \(\theta\) 。同样通过给定的用户偏好参数 \(\theta\) 可以估计电影特征 \(x\) 。因此可以通过随机地猜取一部分 \(\theta\) 值,然后用来估计一些 \(x\) 值,然后再用来估计 \(\theta\) ,如此循环:\(\theta\rightarrow x\rightarrow \theta\rightarrow x \rightarrow \ldots\) ,最终收敛得到一组合理的 \(\theta\) 和 \(x\) 值。这就是最基本的协同过滤算法。
改进算法:同时计算 \(x\) 和 \(\theta\)
-
代价函数:
![]()
-
优化目标:\(\min_\limits{\substack{x^{(1)},\ldots,x^{(n_m)}\\\theta^{(1)},\ldots,\theta^{(n_u)}}}J\left(x^{(1)}, \ldots, x^{\left(n_{m}\right)}, \theta^{(1)}, \ldots, \theta^{\left(n_{u}\right)}\right)\)
-
协同过滤算法
-
随机初始化 \(x^{(1)}, \ldots, x^{\left(n_{m}\right)}, \theta^{(1)}, \ldots, \theta^{\left(n_{u}\right)}\) 为较小值。(类似神经网络的初始化)
-
使用梯度下降或高级优化算法最小化代价函数 \(J\) 。
![]()
其中由于同时进行 \(x,\theta\) 的计算,第二项实际是代价函数分别对 \(x,\theta\) 的偏微分。此外,这里没有像之前的算法一样的偏置项 \(x_0=1\) ,也不存在需要做特殊处理的 \(\theta_0\) 。
-
对拥有偏好参数 \(\theta\) 的用户以及具有特征参数 \(x\) 的电影进行评分预测。
-
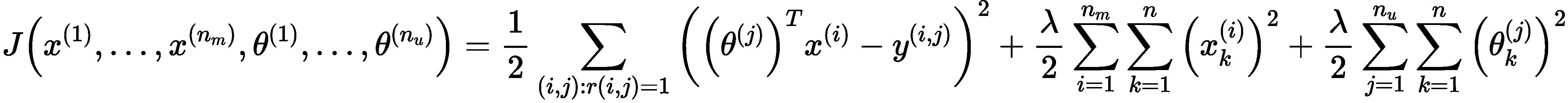
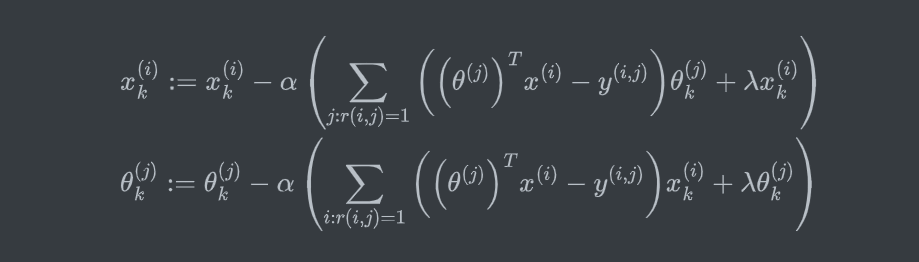
3. 算法实现细节
矢量化:低秩矩阵分解
利用低秩矩阵的性质矩阵化计算预测评分。
将电影和评分数据写成矩阵形式,然后相应地用矩阵 \(\theta^Tx\) 进行预测。
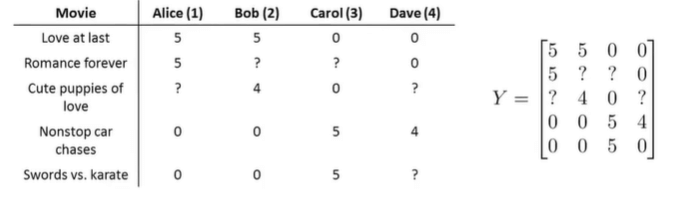

如何找到与电影 \(j\) 类似的电影 \(i\) ?(即推荐什么电影)
计算每部电影的相似度:\(||x^{(i)}-x^{(j)}||\) ,值最小的则是最相似的。
均值归一化(Mean Normalization)
可能会有一些用户从来没进行过任何电影评分,此时若直接按照算法计算,最终结果都是0,即不会有任何电影被推荐给该用户。我们可以对每行或每列进行均值归一化,这样可以将无评分用户的影响降低,得到一个合理的推荐结果。
无评分用户导致预测结果为0的原因:对于优化目标函数,只有正则化项会对该用户对应的参数 \(\theta^{(i)}\) 产生影响(第一项只跟有评分的相关),而该 \(\theta^{(i)}\) 为0满足令目标函数最小化的要求。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号