吴恩达机器学习笔记|(9)异常检测(Anomaly-Detection)
例:飞机引擎检测、欺诈检测(用户的网站行为检测)
一、高斯分布
- \(X\sim N(\mu,\sigma^2)\)
- \(p(x;\mu,\sigma^2)=\frac{1}{\sqrt{2\pi}\sigma}\exp(-\frac{(x-\mu)^2}{2\sigma^2})\)
参数估计:估计参数 \(\mu\) 和 \(\sigma\) 。
二、异常检测算法
-
特征提取。提取出一些对异常敏感的特征量 \(x_i\) ,得到无标签训练集 \(\{x^{(1)},\ldots,x^{(m)}\}\)
-
参数拟合(估计)。\(\mu_1,\ldots,\mu_n,\sigma_1^2,\ldots,\sigma_n^2\)
\[\begin{align} &\mu_j=\frac{1}{m}\sum_{i=1}^mx_j^{(i)}\\ &\sigma_j^2=\frac{1}{m}\sum_{i=1}^m(x_j^{(i)}-\mu_j)^2 \end{align} \]注意:对于大训练集,估计方差时用 \(m或(m-1)\) 影响不大。
-
获取一些新的实测数据 \(x\) (测试集),计算其概率值 \(p(x)\)
\[p(x)=\prod_{j=1}^np(x_j;\mu_j,\sigma_j^2)=\prod_{j=1}^n\frac{1}{\sqrt{2\pi}\sigma_j}\exp(-\frac{(x_j-\mu_j)^2}{2\sigma_j^2}) \]若 \(p(x)<\varepsilon\) (一个很小的值),则该值为异常值。
\(p(x)=p(x_1;\mu_1,\sigma_1^2)\times p(x_2;\mu_2,\sigma_2^2)\times\ldots\times p(x_n;\mu_n,\sigma_n^2)\)
示例:\(\sigma\) 越大,分布越平缓,说明数据分布越分散
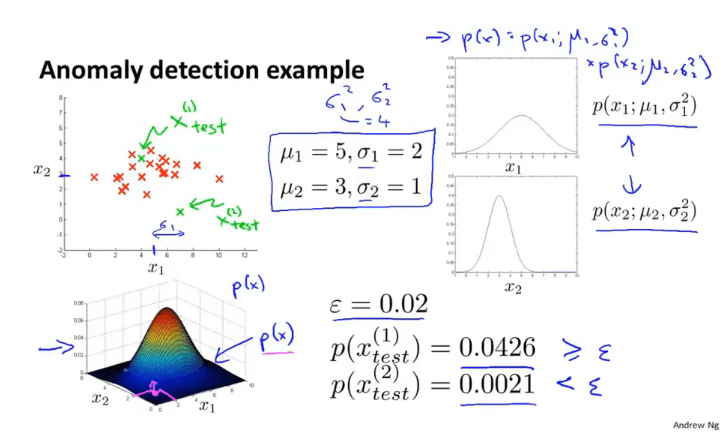
三、开发和评估异常检测系统
飞机引擎示例:
- 10000 good engines(normal)
- 20 flawed engines(anomalous)
- 训练集 \(Training~set\) :6000 good(y=0)
- 验证集 \(CV\) :2000 good(y=0);10 anomalous(y=1)
- 测试集 \(test\) :2000 good(y=0);10 anomalous(y=1)
评估方法:
- 真/假阳性、真/假阴性
- 精确度/召回率
- \(F_1\) score
四、异常检测 VS 监督学习
| 异常检测 | 监督学习 |
|---|---|
| 正常样本数非常少(0~50) | 拥有大量正常样本和异常样本 |
| 大量异常样本 | |
| 很多不同类型的异常样本 | |
| 未来的异常样本很大可能与之前出现过的不一样 | 未来出现的异常样本很大可能与已经出现的异常样本类似 |
| 欺诈检测、工厂产品检测、数据中心监控计算机 | 天气预测、邮件分类、癌症分类 |
五、异常检测算法的特征选择
- 对于数据分布不像高斯分布的,可以尝试进行变换,令其更接近高斯分布。如对数变换(如 \(\log(x)\))、指数变换(如 \(x^{0.5}\))等。
- 选择值不会很大也不会很小的特征量。
- 可以对一些特征变量进行组合得到新的特征量(寻找变量间的关系)。
六、多变量高斯分布
单变量高斯分布的缺陷:数据中的某些异常点,单独观测其某一特征可能是在合理范围内的。如下图中的异常点(绿点)
形象地来说,单变量高斯分布异常检测器认为紫色环内的样本点出现概率是一样的,而实际上蓝色椭圆中的点才是真正的正常点。
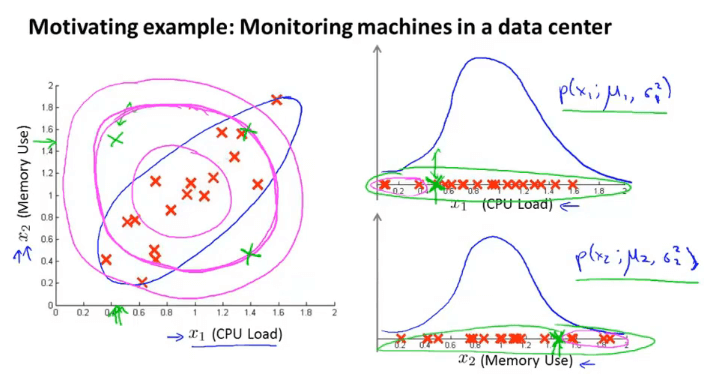
针对特征变量 \(x\in\mathbb{R}^n\) ,不单独对每个变量进行高斯分布建模,而是把它们建模为一个多变量高斯分布模型。
- 参数:均值 \(\mu\in\mathbb{R}^n\) ,协方差矩阵 \(\Sigma\in\mathbb{R}^{n\times n}\) 。
- 概率值:\(p(x;\mu,\sigma^2)=\frac{1}{(2\pi)^{\frac{n}{2}}|\Sigma|^{\frac{1}{2}}}\exp(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu))\)
- \(\mu=\frac{1}{m}\sum_\limits{i=1}^mx^{(i)}\)
- \(\Sigma=\frac{1}{m}\sum_\limits{i=1}^m(x^{(i)}-\mu)(x^{(i)}-\mu)^T\)
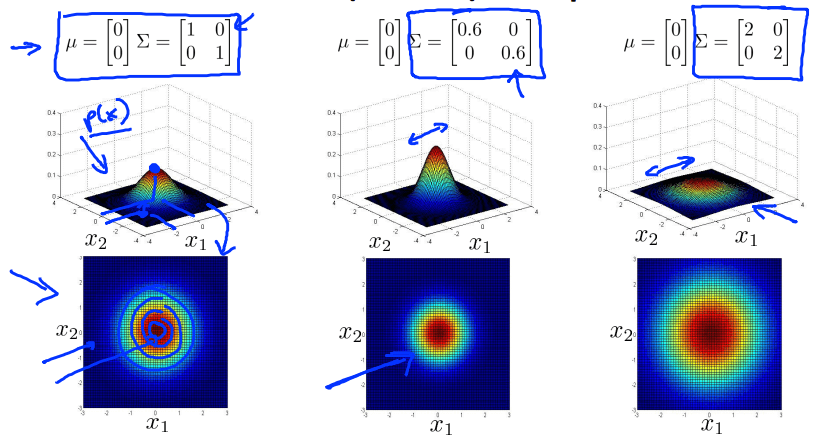
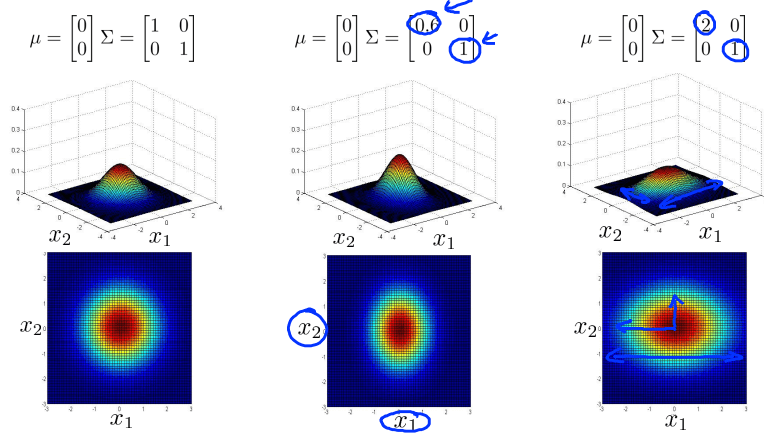
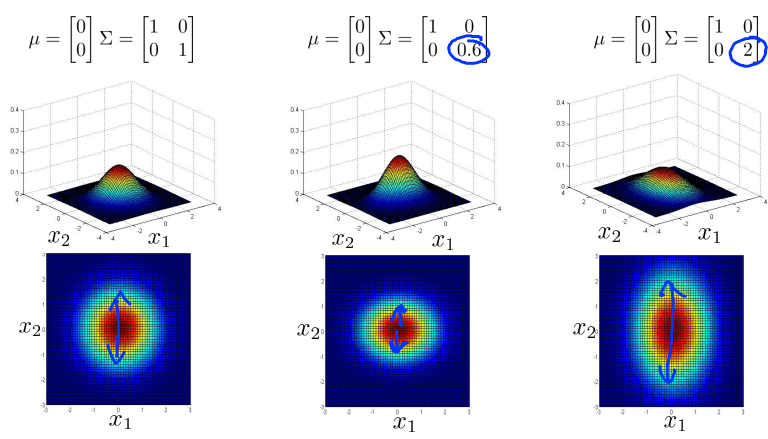
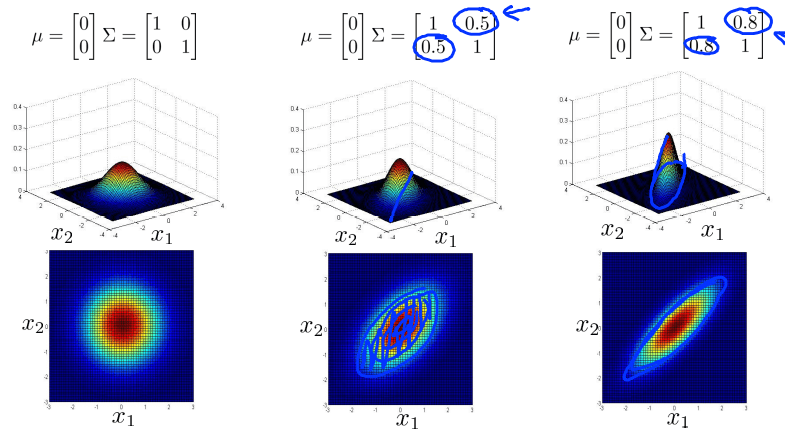
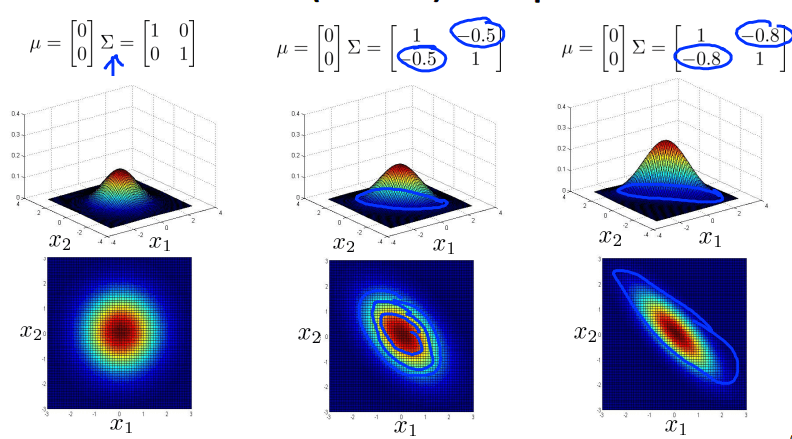
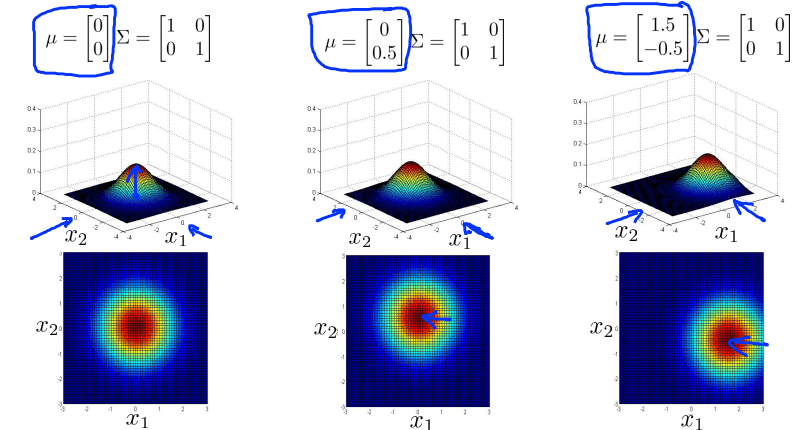
对于多变量高斯分布,通过调整参数元素的分布,可以得到侧重不同方面的数据分布图像。如下图
-
协方差矩阵对角线元素调整
![]()
![]()
![]()
-
协方差矩阵次对角线元素调整
![]()
![]()
-
均值调整
![]()
七、单变量高斯分布 VS 多变量高斯分布
| 单变量 | 多变量 |
|---|---|
| \(p(x_1;\mu_1,\sigma_1^2)\times p(x_2;\mu_2,\sigma_2^2)\times\ldots\times p(x_n;\mu_n,\sigma_n^2)\) | \(p(x;\mu,\sigma^2)=\frac{1}{(2\pi)^{\frac{n}{2}}|\Sigma|^{\frac{1}{2}}}\exp(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu))\) |
| 当需要手动设计新特征变量时,如 \(x_3=\frac{x_1}{x_2}\) (其实就是寻找变量间的关系) | 自动捕捉特征变量间的关系 |
| 计算复杂度低 | 计算复杂度高 |
| 可用样本数 m 较小时 | 必须满足条件:\(m>n\) (远大于会更好)否则 \(\Sigma\) 将不可逆(矩阵奇异,含有冗余特征) |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号