吴恩达机器学习笔记|(8)无监督学习
一、无监督学习
定义:训练数据不带有任何标签。算法的目的是找到数据本身具有的结构特征。
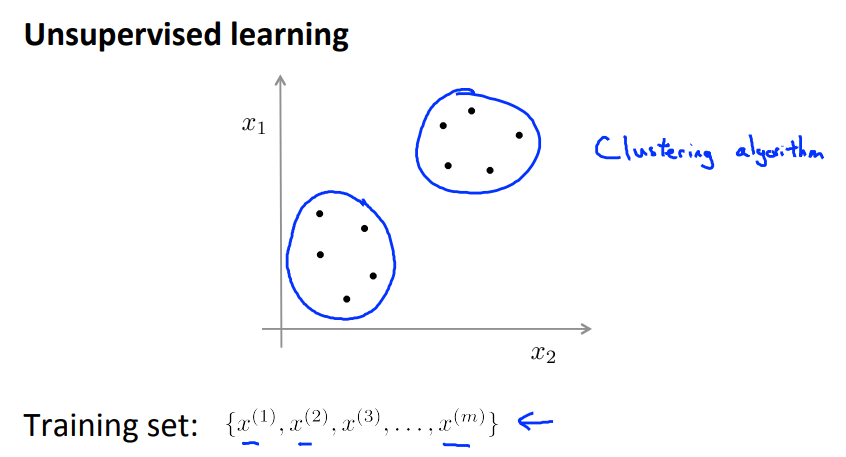
经典的算法:聚类(cluster)、降维(dimensionality reduction)
二、K-means 聚类
2.1 算法步骤:
Input:
- K(簇的数量)
- 无标签训练集\(\{x^{(1)},x^{(2)},\ldots,x^{(m)}\},x^{(i)}\in\mathbb{R}^n\) (注意,没有 \(x_0=1\) )
-
随机初始化 \(K\) 个簇,分别以 \(\mu_1,\mu_2,\ldots,\mu_K\in\mathbb{R}^n\) 为簇中心。
-
重复以下步骤直到达到一定的精度或到达最大迭代次数:
- 簇分配。分别计算每个样本点 \(x^{(i)}\) 到每个簇中心的距离,并选择距离其最近的簇中心,记录距离为 \(c^{(i)}\) ,即 \(\min_\limits{K}||x^{(i)}-\mu_k||^2\) 。并将该点归为距离最近的簇内。
- 移动聚类中心。针对上一步得到的 \(K\) 个簇,计算每个簇内每个点(假设有n个)位置的平均值,作为新的簇中心的位置,\(\mu_k'=\frac{1}{n}\sum_{i=1}^nx^{(i)},~x^{(i)}\in\mathbb{R}^n\) (注意得到的 \(\mu_k'\) 是一个 n 维向量,即一个点的位置)。
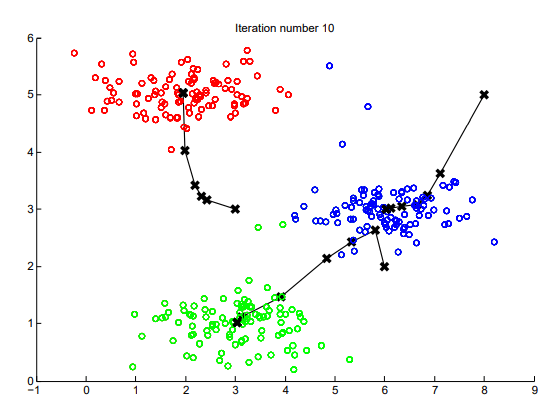
![聚类过程]()
随着算法的运行,簇中心从随机初始化点逐渐移动到真正的簇中心。
算法应用:
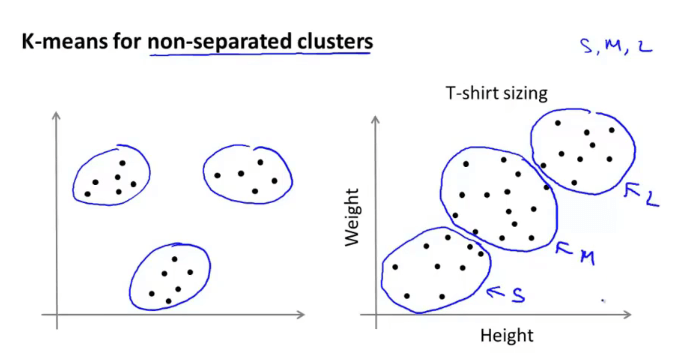
一般来说是左图这类数据结构差异明显的,但也可用于右图这样分布结构比较紧密的数据。
2.2 K-means 算法的优化目标
Optimization Objective:(失真函数)
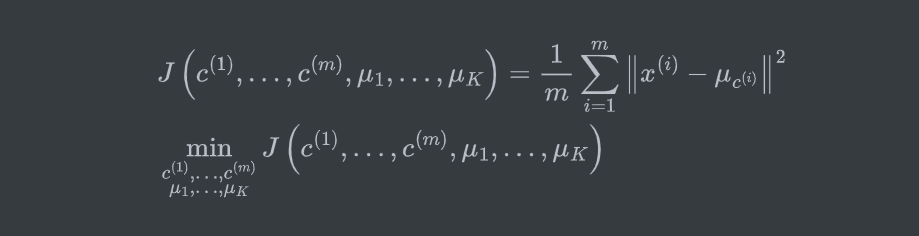
2.3 随机初始化
目的:找到最优的簇,避免局部最优解。
局部最优的例子:
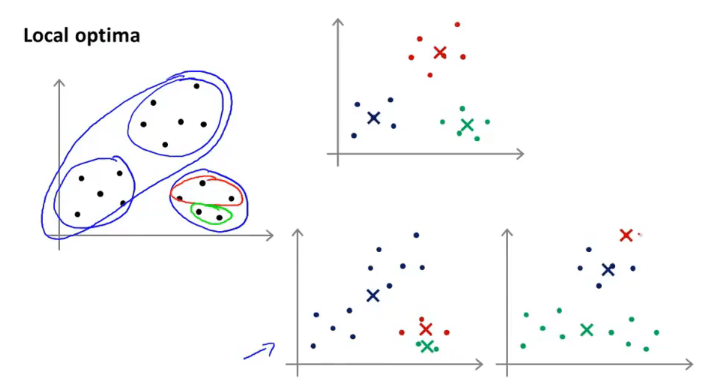
如何避免局部最优?
随机初始化簇中心,并以最小化代价函数 \(J(·)\) 为目标进行迭代。随机初始化方法如直接选取 \(K\) 个样本点作为簇中心。
2.4 簇数量 \(K\) 的选择
-
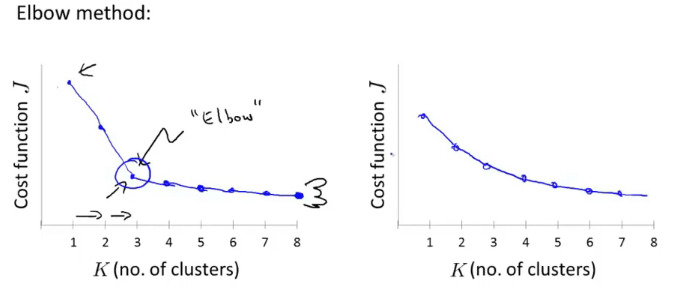
“肘部法则”
分别设置不同的 \(K\) 值,然后运行同样的 K-means 算法,得到各自的代价函数 \(J(·)\) 。画出代价函数关于 \(K\) 的变化趋势图并根据该图进行选择。如下图:
![elbow method]()
-
根据实际需要/目的决定 \(K\) 值。如对 T-shirt 的大小范围进行聚类(S、M、L,K=3 或 XS、S、M、L、XL,K=5),需要根据市场需求、销量等进行选择。
三、降维
降维(Dimension Reduction)的目的:数据压缩,数据可视化。
3.1 数据压缩
数据的某些特征可能是高度相关的,可以通过减少特征冗余达到数据压缩的目的。
例:\(3D\rightarrow 2D,~x^{(i)}\in\mathbb{R}^3\rightarrow z^{(i)}\in\mathbb{R}^2\) 。一些在3D空间中的点云,大多数分布在一个2D的平面内,可以将这些点投影到这个2D平面,从而仅使用两个变量来描述数据特征。
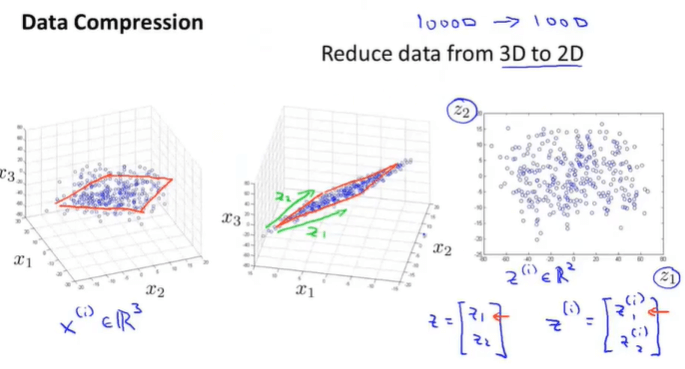
3.2 数据可视化
当数据维度很高时,无法进行数据可视化以直观地观察数据之间的关系及变化。可以通过降维将数据维度降低至2或3维,从而画出图像。
3.3 主成分分析(Principal Component Analysis,PCA)
寻找一个低维空间,然后将数据投影在上面,数据点到该空间的距离称为投影误差,PCA 的目的是找到一个令平方投影误差最小的低维空间。
PCA 与线性回归的区别:
- 在进行线性回归时,计算误差计算的是点到直线在垂直方向的距离。而 PCA 计算的是点到投影点的正交距离(最短距离)。
- 线性回归服务于特殊的变量 \(y\) ,从而进行预测。而 PCA 的目的是降低数据维度,没有这个特殊变量。
PCA 的步骤:
-
训练集:\((x^{(1)},x^{(2)},\ldots,x^{(m)})\)
-
数据预处理
- 均值标准化(零均值化)。对每个 \(x_j^{(i)}\) 执行 \(x_j-\mu_j\)
- 特征缩放。若不同特征数值范围差异很大,需要进行特征缩放。\(x_j^{(i)}=\frac{x_j^{(i)}-\mu_j}{s_j}\) (\(s_j\) 为标准偏差或 \(x_{j_{max}}-x_{j_{min}}\))
-
计算协方差矩阵(covariance matrix)
\[\Sigma=\frac{1}{m}\sum_{i=1}^m(x^{(i)})(x^{(i)})^T \] -
做 SVD 分解,计算协方差矩阵 \(\Sigma\) 的特征向量(eigenvectors)\(U\in\mathbb{R}^{n\times n}\)
\[[U,S,V] = \mathrm{svd}(\Sigma); \] -
仅取矩阵 \(U\) 的前 \(k\) 个向量组成的矩阵 \(U_{reduce}\in\mathbb{R}^{n\times k}\) 。降维后得到新的特征向量(\(x\in\mathbb{R}^n\rightarrow z\in\mathbb{R}^k\))
\[z=U_{reduce}^Tx,\quad z\in\mathbb{R}^k \]
选择合适的主成分的数量 \(k\) ,以最小化平均平方投影误差
-
平均平方投影误差:\(\frac{1}{m}\sum_\limits{i=1}^m||x^{(i)}-x_{approx}^{(i)}||^2\)
压缩重现:\(z=U_{reduce}^Tx \rightarrow x_{approx}=(U_{approx}^T)^{-1}z \approx x\)
-
总方差:\(\frac{1}{m}\sum_\limits{i=1}^{m}||x^{(i)}||^2\)
-
一般来说,选择尽可能小的 \(k\) 值,但要求保证
\[\frac{\frac{1}{m}\sum_\limits{i=1}^m||x^{(i)}-x_{approx}^{(i)}||^2}{\frac{1}{m}\sum_\limits{i=1}^{m}||x^{(i)}||^2}\le 0.01/0.05/0.10/\ldots \]保留 99%(95%, 90%,…) 的方差(方差保留比例),代表了投影数据逼近原始数据的程度。
对于这个计算,实际上相当于计算 \(1-\frac{\sum_\limits{i=1}^kS_{ii}}{\sum_\limits{i=1}^nS_{ii}}\le 0.01\) ,其中 \(S_{ii}\) 为前面进行 \(SVD\) 分解时得到的对角矩阵 \(S(\in\mathbb{R}^{n\times n})\) 对角线上的值。
3.4 PCA 应用建议
注意在使用 PCA 之前,首先需要考虑不使用 PCA ,应该如何利用原始数据解决问题。
当应用 PCA 在模型中时,只能在训练集上应用 PCA ,并通过得到的新训练集计算出所需模型参数 \(\theta\) 。此时我们已经得到了原始数据 \(x\) 到主成分 \(z\) 的映射关系,将此映射关系应用至交叉验证集和测试集进行模型选择和泛化性能评估。
PCA 的错误应用:应用 PCA 以防止过拟合。可能效果不错,但不如正则化,而且 PCA 并不会利用标签,并且舍弃了一些有价值的信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号