吴恩达机器学习笔记|(2)线性回归(Linear-Regression)
一、模型描述
-
建立y关于x的线性函数
-
Hypothesis Function:\(H_\theta(x)=\theta_0+\theta_1 x\)
用\(H_\theta(x)\)来拟合y与x的关系
-
Parameters:\(\theta_0,\theta_1\)
需要估计的参数
-
Cost Function:\(J(\theta_0,\theta_1)=\frac{1}{2m}\sum_\limits{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})^2\)
此处为平方误差代价函数。即通过令\(H_\theta(x)\)与y差异最小使得假设函数最接近真实值。
其中m是训练样本集的容量,\(\frac{1}{2m}\)表示求平均误差最小。 -
Goal Funtion: \(\min_\limits{\theta_0\theta_1}J(\theta_0,\theta_1)\)
-
-
Cost Function
-
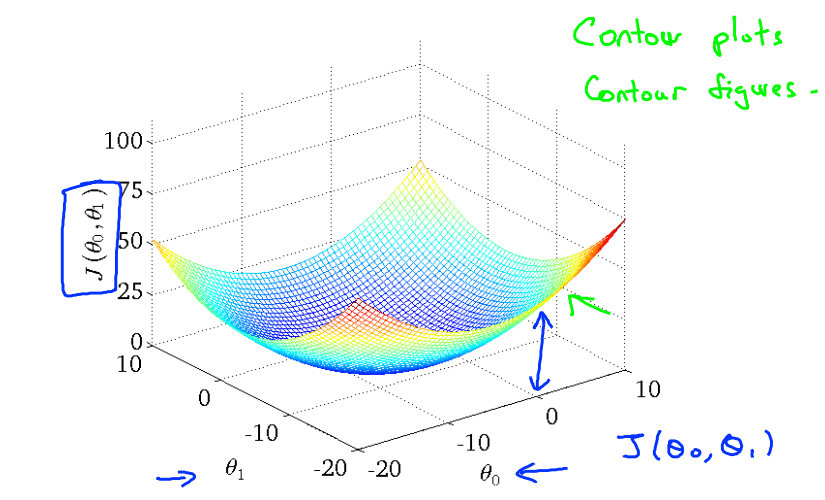
代价函数-3维图像
每个点到底部的距离为一次拟合的代价函数的值
![代价函数-3维图像]()
-
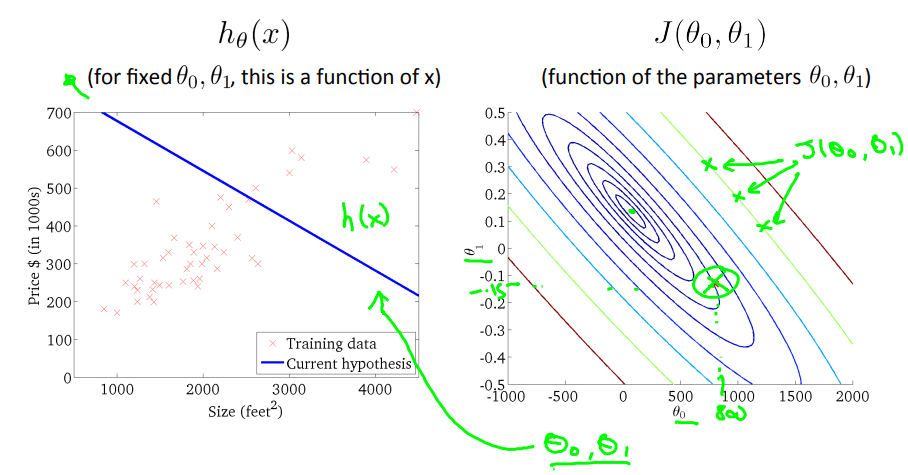
代价函数-等高线图
每条等高线代表拥有相同代价函数值的参数配置
绿点为此次拟合直线的代价值,中心为最小代价值![代价函数-等高线图]()
-
二、梯度下降算法
用于最小化代价函数(不仅仅是最小化线性回归的代价函数)
特点:
- 只能得到局部最小值
- 相比正规方程组法(直接计算最小值),Gradient Descent更适合大数据集
此处的梯度下降算法被称为"Batch" Gradient Descent,因为每一次迭代遍历整个样本集
- 思想
- 从任意参数值\(\theta_0,\theta_1\)开始,如 \(\theta_0=0,\theta_1=0\)
- 不断改变 \(\theta_0,\theta_1\)(朝梯度方向),以减小 \(J(\theta_0,\theta_1)\)
- 直到我们找到 J 的最小值或者局部最小值
- 图像解释
将图像想象成一座山,沿着下山最快的方向下降(即梯度方向),直到到达山谷
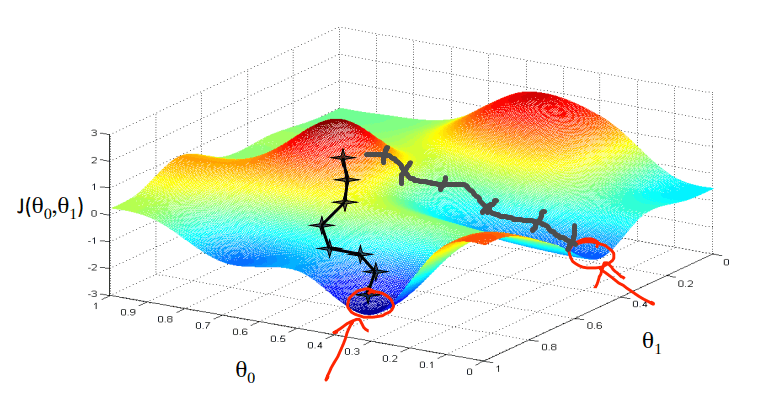
-
迭代公式
循环直至收敛 {\(\theta_j=\theta_j-\alpha\frac{\partial}{\partial\theta_j}J(\theta_0,\theta_1)\)
(for j = 0 and j = 1)
}-
其中\(\alpha\)是学习速率,决定以多大幅度更新参数
-
更新过程(注意\(\theta\)和temp0赋值的执行顺序不能交换,因为需要同步更新\(\theta_0\theta_1\))
\(temp0=\theta_0-\alpha\frac{\partial}{\partial\theta_0}J(\theta_0,\theta_1)\)
\(temp1=\theta_1-\alpha\frac{\partial}{\partial\theta_1}J(\theta_0,\theta_1)\)
\(theta_0=temp0\)
\(theta_1=temp1\)
-
-
收敛
-
学习速率\(\alpha\)
如果\(\alpha\)过小,收敛速度会非常慢
如果\(\alpha\)过大,梯度下降可能会越过最小值,收敛速度慢甚至发散 -
由于最低点导数值为0,因此随着梯度下降算法的执行,它会自动采取较小的幅度(因为导数值越来越小),因此没必要逐渐减小\(\alpha\)
-
三、矩阵乘法的特性
- 不符合交换律: \(A\times B\ne B\times A\)
- 符合结合律: \((A\times B)\times C=A\times (B\times C)\)
- 单位矩阵\(I_{n\times n}\),\(I\times A=A\times I=A\)
四、特殊运算
- 矩阵的逆: \(AA^{-1}=A^{-1}A=I\)(其中A是一个方阵)
- 矩阵的转置 \(A^T\),\(A_{ij}=A^T_{ji}\)
五、多元梯度下降法
-
Hypothesis Function: \(H_\theta(x)=\theta_0+\theta_1 x_1+\theta_2 x_2+...+\theta_n x_n\)
- 为了方便,一般假设 \(x_0=1\)
- 可用矩阵形式表示: \(H_\theta(x)=\theta^T\mathrm{x}\)
-
Parameters: \(\theta_0,\theta_1,...,\theta_n\),n+1维向量
-
Cost Function: \(J(\theta_0,\theta_1,\dots,\theta_n)=\frac{1}{2m}\sum_\limits{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})^2\)
-
Multiple Gradient Descent:
Repeat{
\(\theta_j=\theta_j-\alpha\frac{1}{m}\sum_\limits{i=1}^m(h_\theta(x^{(i)})-y^{(i)})x^{(i)}_j\)
更新 \(\theta_j,j=0,1,\dots,n\)
}
例如有2个特征的梯度下降算法:
\(\theta_0=\theta_0-\alpha\frac{1}{m}\sum_\limits{i=1}^m(h_\theta(x^{(i)})-y^{(i)})x^{(i)}_0\)
\(\theta_1=\theta_1-\alpha\frac{1}{m}\sum_\limits{i=1}^m(h_\theta(x^{(i)})-y^{(i)})x^{(i)}_1\)
\(\theta_2=\theta_2-\alpha\frac{1}{m}\sum_\limits{i=1}^m(h_\theta(x^{(i)})-y^{(i)})x^{(i)}_2\) -
梯度下降运算的技巧
-
特征缩放(Feature Scaling)
使几个特征的大小在相似的规模,使变量间具有可比性,这样会使得梯度下降收敛得更快
如让每一个特征的取值都在与 \(-1\le x_i\le 1\) 相近的范围内
例如可以接受 \(0\le x_1\le 3,-2\le x_2\le 0.5\) ,不能接受 \(-100\le x_3\le 100,-0.0001\le x_4\le 0.0001\)
方法有:- Z-Score标准化: \(x^*=\frac{x-\mu}{\sigma}\)
- min-max归一化(将结果映射到0-1之间): \(x^*=\frac{x-min}{max-min}\)
- ...
-
调试(Debugging)
-
确定梯度下降是否正确运行
代价函数的值应该随迭代减小。在迭代到达一定程度时,代价函数值变化不会太大,可以通过画出代价函数值随着迭代次数的变化曲线,判断应该选择的迭代次数
-
选择合适的学习速率
可以通过每隔一段步长选择 \(\alpha\) 值,画出代价函数值的变化曲线来选取合适的 \(\alpha\) 值。如0.001,0.003,0.01,0.03,0.1,0.3,...,1,...
-
-
-
特征和多项式回归
通过观察数据分布选择多项式如二次模型、三次模型等
\(h_\theta(x)=\theta_0+\theta_1 x_1+\theta_2 x_2^2\)
\(h_\theta(x)=\theta_0+\theta_1 x_1+\theta_2 x_2^2+\sqrt{\theta_3 x_3}\)
\(h_\theta(x)=\theta_0+\theta_1 x_1+\theta_2 x_2^2+\theta_3 x_3^3\)
六、正规方程解法(区别于迭代法的直接解法)
-
方法
- 如让目标函数对每一个未知变量求偏导,并将其置零,得到每一个变量值
- 令 \(\theta=(X^TX)^{-1}X^TY\) ,会得到代价函数的最小值 \(\min_\limits{\theta}J(\theta)\)
-
和梯度下降法的对比(m个训练样本,n个特征值)
-
梯度下降法(Gradient Descent)
- 需要选择学习速率 \(\alpha\)
- 需要多次迭代
- 在特征量很多时效果比较好
-
正规方程法(Normal Equation)
- 不需要选择 \(\alpha\)
- 不需要迭代
- 需要计算 \((X^TX)^{-1}\) (是一个 \(n\times n\) 的矩阵,计算逆矩阵的时间复杂度是 \(O(n^3)\) )
- 特征量多时运行很慢
- 矩阵可逆才能使用
-
-
正规方程法在矩阵不可逆的情况下的解决方法
不可逆的原因:
- 由于某些原因,学习问题包含了多余的特征
- 学习算法有很多特征,导致m小于n,即样本数少于特征数
解决:- 可以通过观察特征之间的关系,也许是线性相关的,可以删掉多余特征
- 可以用MATLAB的求逆函数求出伪逆

 浙公网安备 33010602011771号
浙公网安备 33010602011771号