【Redis】一文掌握Redis原理及常见问题
Redis是基于内存数据库,操作效率高,提供丰富的数据结构(Redis底层对数据结构还做了优化),可用作数据库,缓存,消息中间件等。如今广泛用于互联网大厂,面试必考点之一,本文从数据结构,到集群,到常见问题逐步深入了解Redis,看完再也不怕面试官提问!

高性能之道
- 单线程模型
- 基于内存操作
- epoll多路复用模型
- 高效的数据存储结构
redis的单线程指的是数据处理使用的单线程,实际上它主要包含
- IO线程:处理网络消息收发
- 主线程:处理数据读写操作,包括事务、Lua脚本等
- 持久化线程:执行RDB或AOF时,使用持久化线程处理,避免主线程的阻塞
- 过期键清理线程:用于定期清理过期键
至于redis为什么使用单线程处理数据,是因为redis基于内存操作,并且有高效的数据类型,它的性能瓶颈并不在CPU计算,主要在于网络IO,而网络IO在后来的版本中也被独立出来了IO线程,因此它能快速处理数据,单线程反而避免了多线程所带来的并发和资源争抢的问题
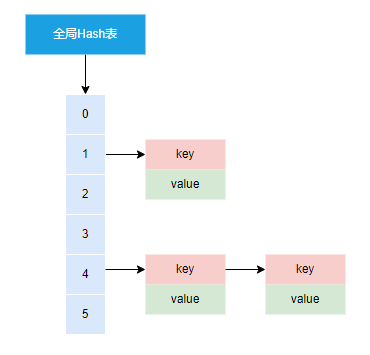
全局数据存储
Redis底层存储基于全局Hash表,存储结构和Java的HashMap类似(数组+链表方式)
rehash
Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。一开始,当你刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash
- 给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;
- 把哈希表 1 中的数据重新进行打散映射到hash表2中;这个过程采用渐进式hash
即拷贝数据时,Redis 仍然正常处理客户端请求,每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的 entries - 释放哈希表 1 的空间。
数据类型
查看存储编码类型:object encoding key
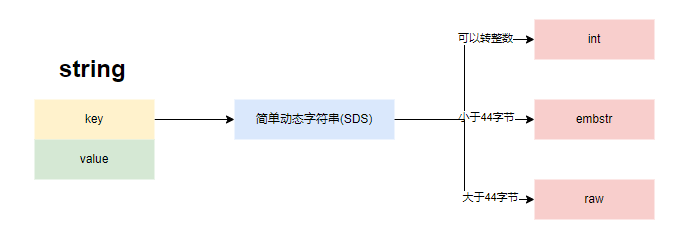
1. string
源码位置:t_string.c
string是最常用的类型,它的底层存储结构是SDS
存储结构
redis的string分三种情况对对象编码,目的是为了节省内存空间:
robj *tryObjectEncodingEx(robj *o, int try_trim)
- if: value长度小于20字节且可以转换为整数(long类型),编码为OBJ_ENCODING_INT,其中若数字在0到10000之间,还可以使用内存共享的数字对象
- else if: 若value长度小于OBJ_ENCODING_EMBSTR_SIZE_LIMIT(44字节),编码为OBJ_ENCODING_EMBSTR
- else: 保持编码为OBJ_ENCODING_RAW
常用命令
SET key value
MSET key value [key value ...]
SETNX key value #常用作分布式锁
GET key
MGET key [key ...]
DEL key [key ...]
EXPIRE key seconds
INCR key
DECR key
INCRBY key increment
DECRBY key increment
常用场景
- 简单键值对
- 自增计数器
INCR作为主键的问题
- 缺陷:若数据量大的情况下,大量使用INCR来自增主键会让redis的自增操作频繁,影响redis的正常使用
- 优化:每台服务可以使用INCRBY一次性获取一百或者一千或者多少个id段来慢慢分配,这样能大量减少redis的incr命令所带来的消耗
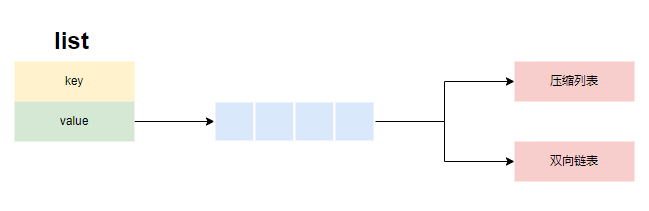
2. list
源码位置:t_list.c
存储结构
redis的list首先会按紧凑列表存储(listPack),当紧凑列表的长度达到list_max_listpack_size之后,会转换为双向链表
// 1.LPUSH/RPUSH/LPUSHX/RPUSHX这些命令的统一入口
void pushGenericCommand(client *c, int where, int xx)
// 2.追加元素,并尝试转换紧凑列表
void listTypeTryConversionAppend(robj *o, robj **argv, int start, int end, beforeConvertCB fn, void *data)
// 3.尝试转换紧凑列表
static void listTypeTryConversionRaw(robj *o, list_conv_type lct, robj **argv, int start, int end, beforeConvertCB fn, void *data)
// 4.尝试转换紧凑列表
// 若紧凑列表的长度达到list_max_listpack_size之后,则转换
static void listTypeTryConvertQuicklist(robj *o, int shrinking, beforeConvertCB fn, void *data)
当redis进行list元素移除时
// 1.移除list元素的统一入口
void listElementsRemoved(client *c, robj *key, int where, robj *o, long count, int signal, int *deleted)
// 2.尝试转换
void listTypeTryConversion(robj *o, list_conv_type lct, beforeConvertCB fn, void *data)
// 3.尝试转换
static void listTypeTryConversionRaw(robj *o, list_conv_type lct, robj **argv, int start, int end, beforeConvertCB fn, void *data)
// 4.尝试转换双向链表
// 若双向链表中只剩一个节点,且是压缩节点,则对双向链表转换为紧凑列表
static void listTypeTryConvertQuicklist(robj *o, int shrinking, beforeConvertCB fn, void *data)
以下参数可在redis.conf配置
list_max_listpack_size:默认-2
常用命令
LPUSH key value [value ...]
RPUSH key value [value ...]
LPOP key
RPOP key
LRANGE key start stop
BLPOP key [key ...] timeout #从key列表头弹出一个元素,若没有元素,则阻塞等待timeout秒,0则一直阻塞等待
BRPOP key [key ...] timeout #从key列表尾弹出一个元素,若没有元素,则阻塞等待timeout秒,0则一直阻塞等待
组合数据结构
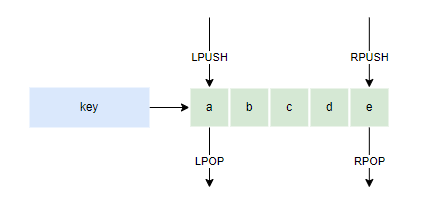
根据list的特性,可以组成实现以下常用的数据结构
- Stack(栈):LPUSH + LPOP
- Queue(队列):LPUSH + RPOP
- Blocking MQ(阻塞队列):LPUSH + BRPOP
redis实现数据结构的意义在于分布式环境的实现
常用场景
- 缓存有序列表结构
- 构建分布式数据结构(栈、队列等)
3. hash
源码位置:t_hash.c
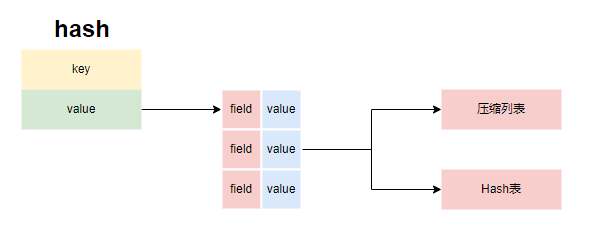
存储结构
redis的hash首先会按紧凑列表存储(listPack),当紧凑列表的长度达到hash_max_listpack_entries或添加的元素大小超过hash_max_listpack_value之后,会转换为Hash表
// 1.添加hash元素
void hsetCommand(client *c)
void hsetnxCommand(client *c)
// 2.尝试转换Hash表
// 若紧凑列表的长度达到hash_max_listpack_entries
// 或添加的元素大小超过hash_max_listpack_value
// 则进行转换
void hashTypeTryConversion(robj *o, robj **argv, int start, int end)
// 3.尝试转换Hash表
void hashTypeConvert(robj *o, int enc)
// 4.转换Hash表
void hashTypeConvertListpack(robj *o, int enc)
以下参数可在redis.conf配置
hash_max_listpack_value:默认64
hash_max_listpack_entries:默认512
常用命令
HSET key field value
HSETNX key field value
HMSET key field value [field value ...]
HGET key field
HMGET key field [field ...]
HDEL key field [field ...]
HLEN key
HGETALL key
HINCRBY key field increment
常用场景
- 对象缓存
4. set
源码位置:t_set.c
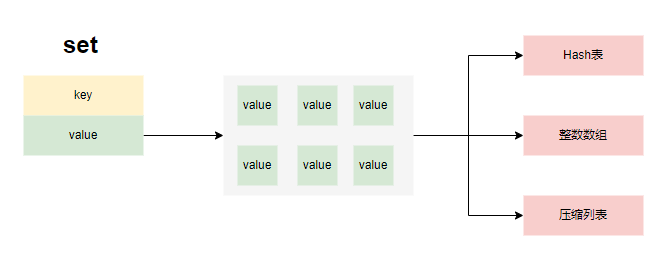
存储结构
- redis的set添加元素时,若存储对象是整形数字且集合小于set_max_intset_entries,则存储为OBJ_ENCODING_INTSET,若集合长度小于set_max_listpack_entries时,存储为紧凑列表。否则,存储为Hash表
// 1.添加set元素
void saddCommand(client *c)
// 2.1.创建set表
// 若存储对象是整形数字且集合小于set_max_listpack_entries,则存储为OBJ_ENCODING_INTSET
// 若集合长度小于set_max_listpack_entries时,存储为紧凑列表
// 否则存储为Hash表
robj *setTypeCreate(sds value, size_t size_hint)
// 2.2 尝试转换set表
// 如果编码是OBJ_ENCODING_LISTPACK(紧凑列表),且集合长度大于set_max_listpack_entries
// 或编码是OBJ_ENCODING_INTSET(整形集合),且集合长度大于set_max_intset_entries
// 则进行转换为Hash表
void setTypeMaybeConvert(robj *set, size_t size_hint)
// 2.3 添加元素
int setTypeAdd(robj *subject, sds value)
int setTypeAddAux(robj *set, char *str, size_t len, int64_t llval, int str_is_sds)
// 2.4 若整形数组添加元素,长度超过set_max_intset_entries,则转换为Hash表
static void maybeConvertIntset(robj *subject)
以下参数可在redis.conf配置
set_max_intset_entries:默认512
set_max_listpack_entries:默认128
常用命令
SADD key member [member ...]
SREM key member [member ...]
SMEMBERS key
SCARD key
SISMEMBERS key member
SRANDMEMBER key [count]
SPOP key [count]
SRANDOMEMBER key [count]
SINTER key [key ...] #交集运算
SINTERSTORE destination key [key ...] #将交集结果存入新集合destination
SUNION key [key ...] #并集运算
SUNIONSTORE destination key [key ...] #将并集结果存入新集合destination
SDIFF key [key ...] #差集运算
SDIFFSTORE destination key [key ...] #将差集结果存入新集合destination
常用场景
- 缓存无序集合
- 需要求交集并集差集的场景
5. sortedset
源码位置:t_zset.c
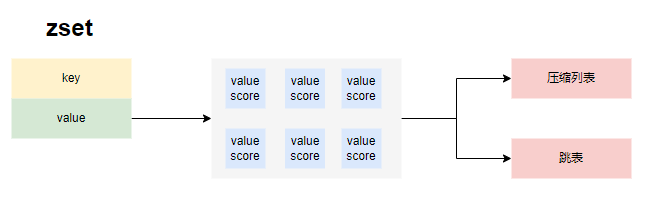
存储结构
根据情况可能创建紧凑列表或跳表
// 1.添加元素
void zaddCommand(client *c)
void zaddGenericCommand(client *c, int flags)
// 2.1 创建元素
// 若集合长度<=zset_max_listpack_entries 并且值的长度<=zset_max_listpack_value,则创建紧凑列表
// 否则创建跳表节点
robj *zsetTypeCreate(size_t size_hint, size_t val_len_hint)
// 2.2 添加元素
// 若集合是紧凑列表,且集合元素超过zset_max_listpack_entries
// 或当前添加的元素长度超过zset_max_listpack_value
// 则将紧凑列表转换为跳表
int zsetAdd(robj *zobj, double score, sds ele, int in_flags, int *out_flags, double *newscore)
以下参数可在redis.conf配置
zset_max_listpack_entries:默认128
zset_max_listpack_value:默认64
跳表仅在以下情况转换回压缩列表
- 使用命令georadius时,判断元素长度若小于等于zset_max_listpack_entries,并且最大元素的长度小于等于zset_max_listpack_value
void georadiusGeneric(client *c, int srcKeyIndex, int flags)
- 使用命令zunion/zinter/zdiff命令(求并集交集差集)时,判断元素长度若小于等于zset_max_listpack_entries,并且最大元素的长度小于等于zset_max_listpack_value
void zunionInterDiffGenericCommand(client *c, robj *dstkey, int numkeysIndex, int op, int cardinality_only)
常用命令
ZADD key score member [[score member]...]
ZREM key member [member ...]
ZSCORE key member
ZINCRBY key increment member
ZCARD key
ZRANGE key start stop [WITHSCORES]
ZREVRANGE key start stop [WITHSCORES]
ZUNIONSTORE destkey numkeys key [key ...] # 并集计算
ZINTERSTORE destkey numkeys key [key ...] # 交集计算
常用场景
- 排行榜
底层数据结构
RedisObject
源码位置:server.h
{
unsigned type:4;//类型 五种对象类型
unsigned encoding:4;//编码
void *ptr;//指向底层实现数据结构的指针
int refcount;//引用计数
unsigned lru:24;//记录最后一次被命令程序访问的时间
}robj;
- type :表示对象的类型,占4个比特;目前包括REDIS_STRING(字符串)、REDIS_LIST (列表)、REDIS_HASH(哈希)、REDIS_SET(集合)、REDIS_ZSET(有序集合)。
- encoding:占4个比特,Redis支持的每种类型,都有至少两种内部编码,例如对于字符串,有int、embstr、raw三种编码。通过encoding属性,Redis可以根据不同的使用场景来为对象设置不同的编码,大大提高了Redis的灵活性和效率。以列表对象为例,有紧凑列表和双端链表两种编码方式;如果列表中的元素较少,Redis倾向于使用紧凑列表进行存储,因为紧凑列表占用内存更少,而且比双端链表可以更快载入;当列表对象元素较多时,紧凑列表就会转化为更适合存储大量元素的双端链表。
- ptr:指针指向具体的数据。
- refcount:记录的是该对象被引用的次数,类型为整型。主要用于对象的引用计数和内存回收。Redis中被多次使用的对象(refcount>1),称为共享对象。Redis为了节省内存,当有一些对象重复出现时,新的程序不会创建新的对象,而是仍然使用原来的对象。这个被重复使用的对象,就是共享对象。目前共享对象仅支持整数值的字符串对象。共享对象只能是整数值的字符串对象,但是5种类型都可能使用共享对象。Redis服务器在初始化时,会创建10000个字符串对象,值分别是0~9999的整数值;
- lru:Redis 对象头中的 lru 字段,在 LRU 算法下和 LFU 算法下使用方式并不相同。
- 在 LRU 算法中,Redis 对象头的 24 bits 的 lru 字段是用来记录 key 的访问时间戳,因此在 LRU 模式下,Redis可以根据对象头中的 lru 字段记录的值,来比较最后一次 key 的访问时间长,从而淘汰最久未被使用的 key。
- 在 LFU 算法中,Redis对象头的 24 bits 的 lru 字段被分成两段来存储,高 16bit 存储 ldt(Last Decrement Time),低 8bit 存储 logc(Logistic Counter)。
- 一个redisObject对象的大小为16字节:4bit+4bit+24bit+4Byte+8Byte=16Byte
SDS 简单动态字符串(Simple Dynamic String)
源码位置:sds.h
typedef char *sds;
struct __attribute__ ((__packed__)) sdshdr5 { // 对应的字符串长度小于 1<<5 32字节
unsigned char flags; /* 3 lsb of type, and 5 msb of string length intembstr*/
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 { // 对应的字符串长度小于 1<<8 256
uint8_t len; /* used */ //目前字符创的长度 用1字节存储
uint8_t alloc; //已经分配的总长度 用1字节存储
unsigned char flags; //flag用3bit来标明类型,类型后续解释,其余5bit目前没有使用 embstr raw
char buf[]; //柔性数组,以'\0'结尾
};
struct __attribute__ ((__packed__)) sdshdr16 { // 对应的字符串长度小于 1<<16
uint16_t len; /*已使用长度,用2字节存储*/
uint16_t alloc; /* 总长度,用2字节存储*/
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 { // 对应的字符串长度小于 1<<32
uint32_t len; /*已使用长度,用4字节存储*/
uint32_t alloc; /* 总长度,用4字节存储*/
unsigned char flags;/* 低3位存储类型, 高5位预留 */
char buf[];/*柔性数组,存放实际内容*/
};
struct __attribute__ ((__packed__)) sdshdr64 { // 对应的字符串长度小于 1<<64
uint64_t len; /*已使用长度,用8字节存储*/
uint64_t alloc; /* 总长度,用8字节存储*/
unsigned char flags; /* 低3位存储类型, 高5位预留 */
char buf[];/*柔性数组,存放实际内容*/
};
字符串类型的内部编码有3种
- int:8个字节的长整型。字符串值是整型时,这个值使用long整型表示。
- embstr:**<=44字节的字符串。embstr与raw都使用redisObject和sds保存数据,区别在于,embstr的使用只分配一次内存空间(因此redisObject和sds是连续的),而raw需要分配两次内存空间(分别为redisObject和sds分配空间)。因此与raw相比,embstr的好处在于创建时少分配一次空间,删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便。而embstr的坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个redisObject和sds都需要重新分配空间**,因此redis中的embstr实现为只读。
- raw:大于44个字节的字符串
embstr和raw进行区分的长度,是44;是因为redisObject的长度是16字节,sds的长度是4+字符串长度;因此当字符串长度是44时,embstr的长度正好是16+4+44 =64,jemalloc正好可以分配64字节的内存单元。
压缩列表zipList
ziplist 被设计成一种内存紧凑型的数据结构,占用一块连续的内存空间,不仅可以利用 CPU 缓存,而且会针对不同长度的数据,进行相应编码,这种方法可以有效地节省内存开销。
ziplist 是一个特殊双向链表,不像普通的链表使用前后指针关联在一起,它是存储在连续内存上的。
/* 创建一个空的 ziplist. */
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
zl[bytes-1] = ZIP_END;
return zl;
}
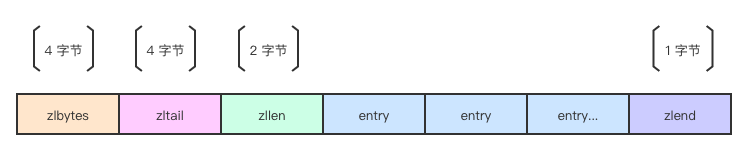
- zlbytes: 32 位无符号整型,记录 ziplist 整个结构体的占用空间大小。当然了也包括 zlbytes 本身。这个结构有个很大的用处,就是当需要修改 ziplist 时候不需要遍历即可知道其本身的大小。 这和SDS中记录字符串的长度有相似之处。
- zltail: 32 位无符号整型, 记录整个 ziplist 中最后一个 entry 的偏移量。所以在尾部进行 POP 操作时候不需要先遍历一次。
- zllen: 16 位无符号整型, 记录 entry 的数量, 所以只能表示 2^16。但是 Redis 作了特殊的处理:当实体数超过 2^16 ,该值被固定为 2^16 - 1。 所以这种时候要知道所有实体的数量就必须要遍历整个结构了。
- entry: 真正存数据的结构。
- zlend: 8 位无符号整型, 固定为 255 (0xFF)。为 ziplist 的结束标识。
zipList缺陷
ziplist 在更新或者新增时候,如空间不够则需要对整个列表进行重新分配。当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。
ziplist 节点的 prevlen 属性会根据前一个节点的长度进行不同的空间大小分配:
- 如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值。
- 如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值。
假设有这样的一个 ziplist,每个节点都是等于 253 字节的。新增了一个大于等于 254 字节的新节点,由于之前的节点 prevlen 长度是 1 个字节。
为了要记录新增节点的长度所以需要对节点 1 进行扩展,由于节点 1 本身就是 253 字节,再加上扩展为 5 字节的 pervlen 则长度超过了 254 字节,这时候下一个节点又要进行扩展了
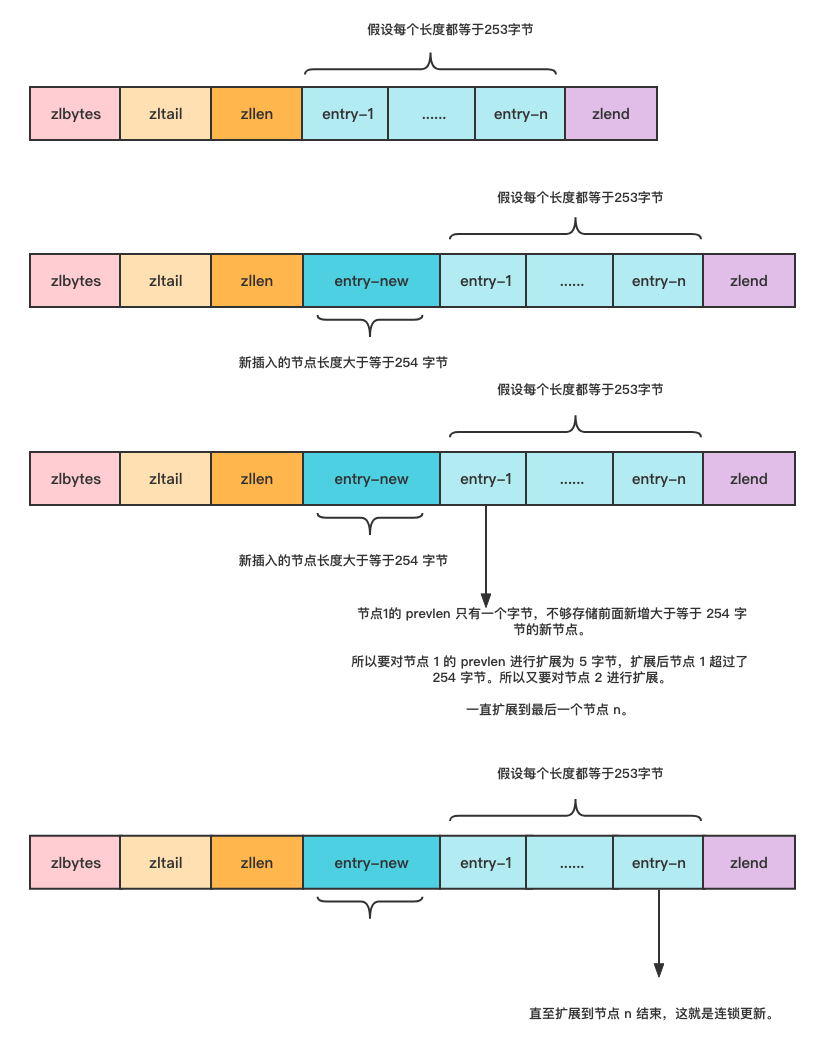
zipList特性
- ziplist 为了节省内存,采用了紧凑的连续存储。所以在修改操作下并不能像一般的链表那么容易,需要从新分配新的内存,然后复制到新的空间。
- ziplist 是一个双向链表,可以在时间复杂度为 O(1) 从下头部、尾部进行 pop 或 push。
- 新增或更新元素可能会出现连锁更新现象。
- 不能保存过多的元素,否则查询效率就会降低。
紧凑列表listPack
Redis7.0之后采用listPack全面替代zipList
在 Redis5.0 出现了 listpack,目的是替代压缩列表,其最大特点是 listpack 中每个节点不再包含前一个节点的长度,压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患。
unsigned char *lpNew(size_t capacity) {
unsigned char *lp = lp_malloc(capacity > LP_HDR_SIZE+1 ? capacity : LP_HDR_SIZE+1);
if (lp == NULL) return NULL;
lpSetTotalBytes(lp,LP_HDR_SIZE+1);
lpSetNumElements(lp,0);
lp[LP_HDR_SIZE] = LP_EOF;
return lp;
}
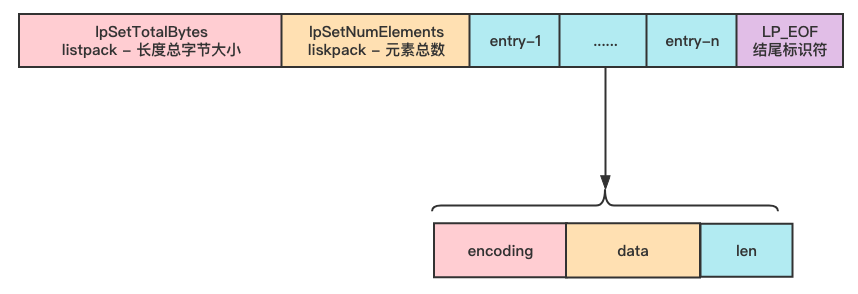
- listpack 中每个节点不再包含前一个节点的长度,避免连锁更新的隐患发生。
- listpack 相对于 ziplist,没有了指向末尾节点地址的偏移量,解决 ziplist 内存长度限制的问题。但一个 listpack 最大内存使用不能超过 1GB。
跳表
数组:查询快,插入删除慢
链表:查询慢,插入删除快
跳表:跳表是基于链表的一个优化,在链表的插入删除快的特性之上,也增加了它的查询效率。它是将有序链表改造为支持折半查找算法,它的插入、删除、查询都很快
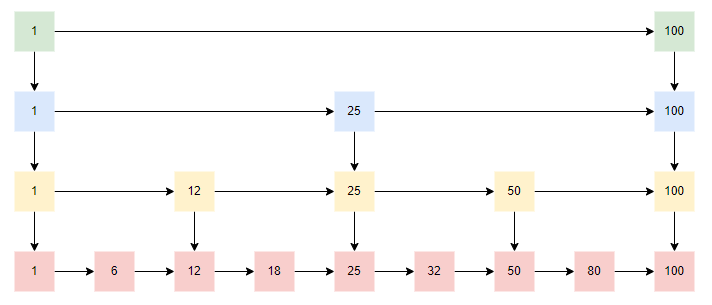
跳表缺陷:需要额外空间来建立索引层,以空间换时间,因此zset一开始是以紧凑列表存储,后续才会转换为跳表
- 跳表的创建(添加元素时)
- 当前zset不存在时,若添加元素时集合长度达到zset_max_listpack_entries,或添加的最后一个元素的大小超过zset_max_listpack_value,则直接创建跳表,跳表头结点创建最大层数(ZSKIPLIST_MAXLEVEL:32)的索引,并插入跳表当前添加的元素
- 当前zset存在时,判断若元素长度超过zset_max_listpack_entries,则将紧凑列表转换为跳表,跳表头结点创建最大层数(ZSKIPLIST_MAXLEVEL:32)的索引,然后把其他元素依次插入跳表
- 跳表的查询
从起始节点开始,通过多级索引进行折半查找,最终找到需要的数据 - 跳表的插入
先通过折半查找找到节点对应要插入的链表位置,然后通过随机得到一个要插入的节点的索引层数,然后插入节点,并构建对应的多级索引 - 跳表的删除
先通过折半查找找到要删除的节点的链表位置,删除节点,并删除对应的多级索引
淘汰策略
- noeviction(默认策略): 不会删除任何数据,拒绝所有写入操作并返回客户端错误消息(error)OOM command not allowed when used memory,此时 Redis 只响应删和读操作;
- allkeys-lru: 从所有 key 中使用 LRU(Least Recently Used)算法进行淘汰(LRU 算法:最近最少使用算法);
- allkeys-lfu: 从所有 key 中使用 LFU(Least Frequently Used)算法进行淘汰(LFU 算法:最不常用算法,根据使用频率计算,4.0 版本新增);
- volatile-lru: 从设置了过期时间的 key 中使用 LRU 算法进行淘汰;
- volatile-lfu: 从设置了过期时间的 key 中使用 LFU 算法进行淘汰;
- allkeys-random: 从所有 key 中随机淘汰数据;
- volatile-random: 从设置了过期时间的 key 中随机淘汰数据;
- volatile-ttl: 在设置了过期时间的key中,淘汰过期时间剩余最短的。
Redis的LRU实现
由于Redis 主要运行在单个线程中,它采用的是一种近似的 LRU 算法,而不是传统的完全 LRU 算法(没有把所有key组织为链表)。这种实现方式在保证性能的同时,仍然能够有效地识别并淘汰最近最少使用的键。当 Redis 进行内存淘汰时,会使用随机采样的方式来淘汰数据,它是随机取 5 个值(此值可配置),然后淘汰最久没有使用的那个。
Redis的LFU实现
Redis 在访问 key 时,对 logc进行变化:
- 先按照上次访问距离当前的时长,来对 logc 进行衰减;
- 再按照一定概率增加 logc 的值
redis.conf 提供了两个配置项,用于调整 LFU 算法从而控制 logc 的增长和衰减:
- lfu-decay-time 用于调整 logc 的衰减速度,它是一个以分钟为单位的数值,默认值为1,lfu-decay-time 值越大,衰减越慢;
- lfu-log-factor 用于调整 logc 的增长速度,lfu-log-factor 值越大,logc 增长越慢
删除策略
redis的key过期删除策略采用惰性删除+定期删除实现:
- 惰性删除:不主动删除过期键,每次从数据库访问 key 时,都检测 key 是否过期,如果过期则删除该 key
Redis 的惰性删除策略由 db.c 文件中的 expireIfNeeded 函数实现,代码如下:
int expireIfNeeded(redisDb *db, robj *key) {
// 判断 key 是否过期
if (!keyIsExpired(db,key)) return 0;
....
/* 删除过期键 */
....
// 如果 server.lazyfree_lazy_expire 为 1 表示异步删除,反之同步删除;
return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
dbSyncDelete(db,key);
}
- 定期删除:定期删除策略的做法是,每隔一段时间随机从数据库中取出一定数量的 key 进行检查,并删除其中的过期key
在 Redis 中,默认每秒进行 10 次过期检查一次数据库,此配置可通过 Redis 的配置文件 redis.conf 进行配置,配置键为 hz 它的默认值是 hz 10;定期删除的实现在 expire.c 文件下的 activeExpireCycle 函数中,其中随机抽查的数量由 ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP 定义的,它是写死在代码中的,数值是 20;也就是说,数据库每轮抽查时,会随机选择 20 个 key 判断是否过期。
管道Pipeline
redis提供pipeline,可以让客户端一次发送一连串的命令给服务器执行,然后再返回执行结果
- 应用场景:
- 需要多次执行一连串的redis命令,且命令之间没有依赖的场景
- 缺陷:
- 不保证原子性,pipeline拿到命令只管串行执行,不管执行成功与否,也没有回滚机制
- pipeline在执行过程中无法知道执行结果,只有全部执行结束才会返回全部结果
- pipeline也不宜一次性发送过多命令,尽管节省了IO,但在redis端也依然会进行执行队列顺序执行
使用示例
/**
* 一次io获取个值
*
* @param redisKeyEnum
* @param ids
* @param clz
* @param <T>
* @param <E>
* @return
*/
public <T, E extends T> List<T> multiGet(RedisKeyEnum redisKeyEnum, List<String> ids, Class<E> clz) {
ShardRedisConnectionFactory factory = getShardRedisConnectionFactory(redisKeyEnum);
ShardedJedis shardedJedis = factory.getConnection();
return execute(factory, shardedJedis, new Supplier<List<T>>() {
@Override
public List<T> get() {
// 1.获取管道
ShardedJedisPipeline pipeline = shardedJedis.pipelined();
List<T> list = new ArrayList<>();
List<Response<String>> respList = new ArrayList<>();
for (String id : ids) {
String key = getKey(redisKeyEnum, id);
// 2.通过管道执行命令
Response<String> resp = pipeline.get(key);
respList.add(resp);
}
// 3.统一提交命令
pipeline.sync();
for (Response<String> resp : respList) {
// 4.遍历获取全部的命令执行返回结果
String result = resp.get();
if (result == null) {
continue;
}
if (clz.equals(String.class)) {
list.add((E) result);
} else {
list.add(JsonUtil.json2Obj(result, clz));
}
}
return list;
}
});
}
事务
Redis 事务的本质是一组命令的集合。事务支持一次执行多个命令,一个事务中所有命令都会被序列化。在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。
事务的命令:
- MULTI :开启事务,redis会将后续的命令逐个放入队列中,然后使用EXEC命令来原子化执行这个命令系列。
- EXEC:执行事务中的所有操作命令。
- DISCARD:取消事务,放弃执行事务块中的所有命令。
- WATCH:监视一个或多个key,如果事务在执行前,这个key(或多个key)被其他命令修改,则事务被中断,不会执行事务中的任何命令。
- UNWATCH:取消WATCH对所有key的监视。
redis事务在编译错误可以回滚,而运行时错误不能回滚,简单说,redis事务不支持回滚
Redis的持久化
redis提供了两种持久化的方式,分别是RDB(Redis DataBase)和AOF(Append Only File)。
- RDB,简而言之,就是在不同的时间点,将redis存储的数据生成快照并存储到磁盘等介质上;
- AOF,则是换了一个角度来实现持久化,那就是将redis执行过的所有写指令记录下来,在下次redis重新启动时,只要把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。AOF类似MySQL的binlog
其实RDB和AOF两种方式也可以同时使用,在这种情况下,如果redis重启的话,则会优先采用AOF方式来进行数据恢复,这是因为AOF方式的数据恢复完整度更高。
如果你没有数据持久化的需求,也完全可以关闭RDB和AOF方式,这样的话,redis将变成一个纯内存数据库
1. AOF
AOF日志是一种追加式持久化方式,它记录了每个写操作命令,以追加的方式将命令写入AOF文件。通过重新执行AOF文件中的命令,可以重建出数据在内存中的状态。AOF日志提供了更精确的持久化,适用于需要更高数据安全性和实时性的场景。
优点:
- AOF日志可以实现更精确的数据持久化,每个写操作都会被记录。
- 在AOF文件中,数据可以更好地恢复,因为它保存了所有的写操作历史。
- AOF日志适用于需要实时恢复数据的场景,如秒级数据恢复要求。
缺点:
- AOF日志相对于RDB快照来说,可能会占用更多的磁盘空间,因为它是记录每个写操作的文本文件。
- AOF日志在恢复大数据集时可能会比RDB快照慢,因为需要逐条执行写操作。
根据不同的需求,可以选择RDB快照、AOF日志或两者结合使用。你可以根据数据的重要性、恢复速度要求以及磁盘空间限制来选择合适的持久化方式。有时候,也可以通过同时使用两种方式来提供更高的数据保护级别。
2. RDB
RDB快照是一种全量持久化方式,它会周期性地将内存中的数据以二进制格式保存到磁盘上的RDB文件。RDB文件是一个经过压缩的二进制文件,包含了数据库在某个时间点的数据快照。RDB快照有助于实现紧凑的数据存储,适合用于备份和恢复。
优点:
- RDB快照在恢复大数据集时速度较快,因为它是全量的数据快照。
- 由于RDB文件是压缩的二进制文件,它在磁盘上的存储空间相对较小。
- 适用于数据备份和灾难恢复。
缺点:
- RDB快照是周期性的全量持久化,可能导致某个时间点之后的数据丢失。
- 在保存快照时,Redis服务器会阻塞,可能对系统性能造成影响。
发布订阅
Redis提供了基于“发布/订阅”模式的消息机制。此种模式下,消息发布者和订阅者不进行直接通信,发布者客户端向指定的频道(channel) 发布消息,订阅该频道的每个客户端都可以收到该消息。结构如下:
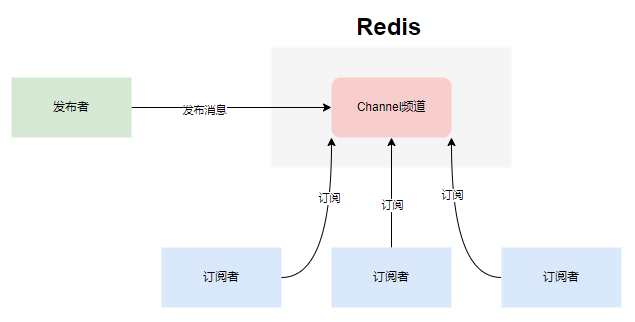
该消息通信模式可用于模块间的解耦
# 订阅消息
subscribe channel [channel ...]
# 发布消息
publish channel "hello"
# 按模式订阅频道
psubscribe pattern [pattern ...]
# 退订频道
unsubscribe pattern [pattern ...]
# 按模式退订频道
punsubscribe pattern [pattern ...]
Redis发布订阅与消息队列的区别
- 消息队列可以支持多种消息协议,但 Redis 没有提供对这些协议的支持;
- 消息队列可以提供持久化功能,但 Redis无法对消息持久化存储,一旦消息被发送,如果没有订阅者接收,那么消息就会丢失;
- 消息队列可以提供消息传输保障,当客户端连接超时或事务回滚等情况发生时,消息会被重新发送给客户端,Redis 没有提供消息传输保障。
- 发布订阅消息量过多过频繁,也会占用redis的内存空间,挤占业务逻辑key的空间(可以通过放到不同redis解决)
Redis集群模式
redis集群主要有三种模式:主从复制,哨兵模式和Cluster
主从复制
主从复制模式中包含一个主数据库实例(master)与一个或多个从数据库实例(slave)
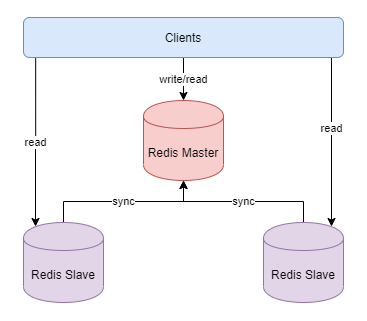
工作机制
- slave启动后,向master发送SYNC命令,master接收到SYNC命令后通过bgsave保存快照,并使用缓冲区记录保存快照这段时间内执行的写命令
- master将保存的快照文件发送给slave,并继续记录执行的写命令
- slave接收到快照文件后,加载快照文件,载入数据
- master快照发送完后开始向slave发送缓冲区的写命令,slave接收命令并执行,完成复制初始化
- master每次执行一个写命令都会同步发送给slave,保持master与slave之间数据的一致性
主从复制配置
replicaof 127.0.0.1 6379 # master的ip,port
masterauth 123456 # master的密码
replica-serve-stale-data no # 如果slave无法与master同步,设置成slave不可读,方便监控脚本发现问题
优缺点
优点:
- master能自动将数据同步到slave,可以进行读写分离,分担master的读压力
- master、slave之间的同步是以非阻塞的方式进行的,同步期间,客户端仍然可以提交查询或更新请求
缺点:
- 不具备自动容错与恢复功能,master或slave的宕机都可能导致客户端请求失败,需要等待机器重启或手动切换客户端IP才能恢复
- master宕机,如果宕机前数据没有同步完,则切换IP后会存在数据不一致的问题
- 难以支持在线扩容,Redis的容量受限于单机配置
哨兵模式
主从切换技术的方法是:当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
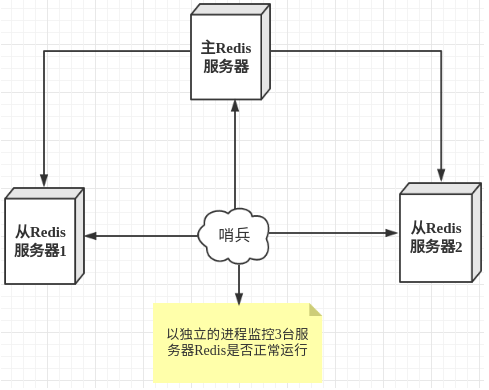
这里的哨兵有两个作用
- 通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器。
- 当哨兵监测到master宕机,会自动将slave切换成master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机。
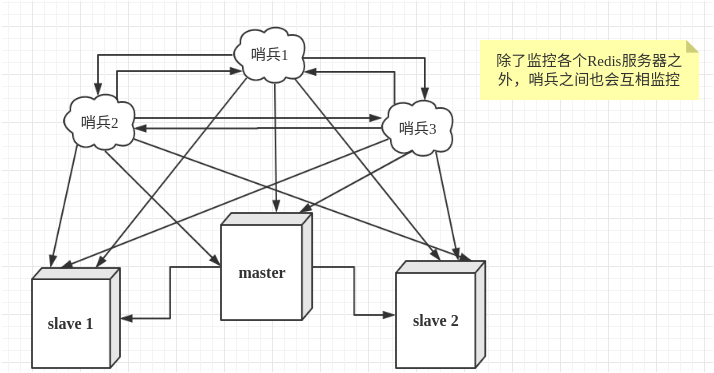
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。
哨兵配置
- 主从服务器配置
# 使得Redis服务器可以跨网络访问
bind 0.0.0.0
# 设置密码
requirepass "123456"
# 指定主服务器,注意:有关slaveof的配置只是配置从服务器,主服务器不需要配置
slaveof 192.168.11.128 6379
# 主服务器密码,注意:有关slaveof的配置只是配置从服务器,主服务器不需要配置
masterauth 123456
- 配置哨兵
在Redis安装目录下有一个sentinel.conf文件,copy一份进行修改
# 禁止保护模式
protected-mode no
# 配置监听的主服务器,这里sentinel monitor代表监控,mymaster代表服务器的名称,可以自定义,192.168.11.128代表监控的主服务器,6379代表端口,2代表只有两个或两个以上的哨兵认为主服务器不可用的时候,才会进行failover操作。
sentinel monitor mymaster 192.168.11.128 6379 2
# sentinel author-pass定义服务的密码,mymaster是服务名称,123456是Redis服务器密码
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster 123456
- 启动服务器和哨兵
# 启动Redis服务器进程
./redis-server ../redis.conf
# 启动哨兵进程
./redis-sentinel ../sentinel.conf
Cluster模式
哨兵模式解决了主从复制不能自动故障转移,达不到高可用的问题,但还是存在难以在线扩容,Redis容量受限于单机配置的问题。
Cluster模式实现了Redis的分布式存储,即每台节点存储不同的内容,来解决在线扩容的问题
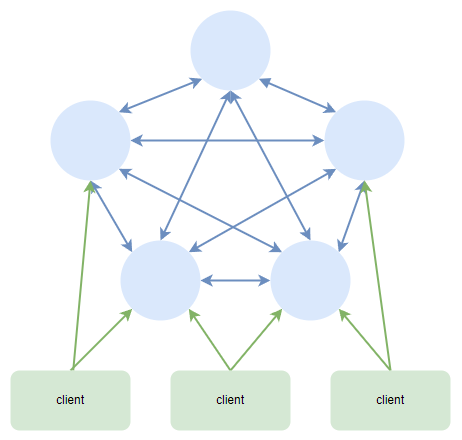
Cluster特点
- 无中心结构:所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽
- 分布式存储:Redis Cluster将数据分散存储在多个节点上,每个节点负责存储和处理其中的一部分数据。这种分布式存储方式允许集群处理更大的数据集,并提供更高的性能和可扩展性。
- 数据复制:每个主节点都有一个或多个从节点,从节点会自动复制主节点上的数据。数据复制可以提供数据的冗余备份,并在主节点故障时自动切换到从节点,以保证系统的可用性。
- 自动分片和故障转移:Redis Cluster会自动将数据分片到不同的节点上,同时提供自动化的故障检测和故障转移机制。当节点发生故障或下线时,集群会自动检测并进行相应的故障转移操作(投票机制:节点的fail是通过集群中超过半数的节点检测失效时才生效),以保持数据的可用性和一致性。
- 节点间通信:Redis Cluster中的节点之间通过内部通信协议进行交互,共同协作完成数据的分片、复制和故障转移等操作。节点间通信的协议和算法确保了数据的正确性和一致性。
工作机制
- 在Redis的每个节点上,都有一个插槽(slot),取值范围为0-16383
- 当我们存取key的时候,Redis会根据CRC16的算法得出一个结果,然后把结果对16384求余数,这样每个key都会对应一个编号在0-16383之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作
- 为了保证高可用,Cluster模式也引入主从复制模式,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点
- 当其它主节点ping一个主节点A时,如果半数以上的主节点与A通信超时,那么认为主节点A宕机了。如果主节点A和它的从节点都宕机了,那么该集群就无法再提供服务了
Cluster模式集群节点最小配置6个节点(3主3从,因为需要半数以上),其中主节点提供读写操作,从节点作为备用节点,不提供请求,只作为故障转移使用。
Cluster部署
redis.conf配置:
port 7100 # 本示例6个节点端口分别为7100,7200,7300,7400,7500,7600
daemonize yes # r后台运行
pidfile /var/run/redis_7100.pid # pidfile文件对应7100,7200,7300,7400,7500,7600
cluster-enabled yes # 开启集群模式
masterauth passw0rd # 如果设置了密码,需要指定master密码
cluster-config-file nodes_7100.conf # 集群的配置文件,同样对应7100,7200等六个节点
cluster-node-timeout 15000 # 请求超时 默认15秒,可自行设置
启动redis:
[root@dev-server-1 cluster]# redis-server redis_7100.conf
[root@dev-server-1 cluster]# redis-server redis_7200.conf
组成集群:
redis-cli --cluster create --cluster-replicas 1 127.0.0.1:7100 127.0.0.1:7200 127.0.0.1:7300 127.0.0.1:7400 127.0.0.1:7500 127.0.0.1:7600 -a passw0rd
--cluster-replicas:表示副本数量,也就是从服务器数量,因为我们一共6个服务器,这里设置1个副本,那么Redis会收到消息,一个主服务器有一个副本从服务器,那么会计算得出:三主三从。
Cluster注意点
- 数据分片和哈希槽:Redis Cluster 使用数据分片和哈希槽来实现数据的分布式存储。每个节点负责一部分哈希槽,确保数据在集群中均匀分布。在设计应用程序时,需要考虑数据的分片规则和哈希槽的分配,以便正确地将数据路由到相应的节点。
- 节点的故障和扩展:Redis Cluster 具有高可用性和可伸缩性。当节点发生故障或需要扩展集群时,需要正确处理节点的添加和删除。故障节点会被自动检测和替换,而添加节点需要进行集群重新分片的操作。
- 客户端的重定向:Redis Cluster 在处理键的读写操作时可能会返回重定向错误(MOVED 或 ASK)。应用程序需要正确处理这些错误,根据重定向信息更新路由表,并将操作重定向到正确的节点上。
- 数据一致性的保证:由于 Redis Cluster 使用异步复制进行数据同步,所以在节点故障和网络分区恢复期间,可能会发生数据不一致的情况。应用程序需要考虑数据一致性的问题,并根据具体业务需求采取适当的措施。
- 客户端连接的负载均衡:在连接 Redis Cluster 时,应该使用适当的负载均衡策略,将请求均匀地分布到集群中的各个节点上,以避免单个节点过载或出现热点访问。
- 事务和原子性操作:Redis Cluster 中的事务操作只能在单个节点上执行,无法跨越多个节点。如果需要执行跨节点的原子性操作,可以使用 Lua 脚本来实现。
- 集群监控和管理:对 Redis Cluster 进行监控和管理是很重要的。可以使用 Redis 自带的命令行工具或第三方监控工具来监控集群的状态、性能指标和节点健康状况,以及执行管理操作,如节点添加、删除和重新分片等。

Redis常见问题
当使用redis作为数据库的缓存层时,会经常遇见这几种问题,以下是这些问题的描述以及对应的解决方案
缓存穿透
概念:请求过来之后,访问不存在的数据,redis中查询不到,则穿透到数据库进行查询
现象:大量穿透访问造成redis命中率下降,数据库压力飙升
解决方案:
- 空值缓存:如果一个查询的数据返回空,仍然把这个结果缓存到redis,以缓解数据库的查询压力
- 布隆过滤器:布隆过滤器由一个很长的二进制数组结合n个hash算法计算出n个数组下标,将这些数据下标置为1。在查找数据时,再次通过n个hash算法计算出数组下标,如果这些下标的值为1,表示该值可能存在(存在hash冲突的原因),如果为0,则表示该值一定不存在。因此,布隆过滤器中存在,数据不一定存在,但若布隆过滤器中不存在,则数据一定不存在,依靠此特性可以过滤掉一定的空值数据
缓存击穿
概念:请求访问的key对应的数据存在,但key在redis中已过期,则访问击穿到数据库
现象:若大批请求中访问的key均过期,那么redis正常运行,但数据库的瞬时并发压力会飙升
解决方案:
- 热点数据永不过期:热点数据可以一直在redis中请求到,不会过期,则不会出现缓存击穿现象
- 使用互斥锁:当访问redis的key过期之后,在请求数据库重新加载数据之前,先获取互斥锁(单进程可以synchronized,分布式使用分布式锁),获取到锁的请求加载数据并放进缓存,没有获取到锁的请求可以进行重试,重试之后便能重新获取到redis中的数据
缓存雪崩
概念:同一时间大批量key同时过期,造成瞬时对这些key的请求全部击穿到数据库;或redis服务不可用(宕机)
缓存雪崩与缓存击穿的区别在于:缓存击穿是单个热点数据过期,而缓存雪崩是大批量热点数据过期
现象:大量热点数据的查询请求会增加数据库瞬时压力
解决方案:
- 设置随机过期时间:避免大量key的过期时间过于集中,可以通过随机算法均匀分布key的过期时间点
- 热点数据永不过期:可以和缓存击穿一样让热点数据不过期
- 搭建高可用redis服务:针对redis服务不可用,可以对redis进行分布式部署,并实现故障转移(如redis哨兵模式)
- 控制系统负载:实现熔断限流或服务降级,让系统负载在可控范围内
大key问题
概念:redis中存在占用内存空间较多的key,其中包含多种情况,如string类型的value值过大,hash类型的所有成员总值过大,zset的成员数量过大等。大key的具体值的界定,要根据实际业务情况判断。
现象:大key对业务会产生多方面的影响:
- redis内存占用过高:大key可能导致内存空间不足,从而触发redis的内存淘汰策略。
- 阻塞其他操作:对某些大key操作可能导致redis实例阻塞,例如使用Del命令删除key等。
- 网络拥塞:大key在网络传输中更消耗带宽,可能造成机器内部网络带宽打满。
- 主从同步延迟:大key在redis进行主从同步时也更容易导致同步延迟,影响数据一致性。
原因:
- 业务设计不合理:在业务设计上,没有考虑大数据量问题,导致一个key存储了大量的数据
- 未定期清理数据:没有合适的删除机制或过期机制,造成value不断增加
- 业务逻辑问题:业务逻辑bug导致key的value只增不减
排查:
- SCAN命令:通过redis的scan命令逐步遍历数据库中的所有key,通过比较大小,站到占用内存较多的大key
- bigkeys参数:使用redis-cli命令客户端,连接Redis服务的时候,加上 —bigkeys 参数,可以扫描每种数据类型数量最大的key。
redis-cli -h 127.0.0.1 -p 6379 —bigkeys
- Redis RDB Tools工具:使用开源工具Redis RDB Tools,分析RDB文件,扫描出Redis大key。
例如:输出占用内存大于1kb,排名前3的keys。
rdb —commond memory —bytes 1024 —largest 3 dump.rbd
- Redis云商提供的工具:现在基本使用云商提供的redis实例,其本身也提供一定的方法能快速定位大key
解决方案:
- 大key拆分:可以根据实际业务场景,拆分多个小key,确保value大小在合理范围内
- 大key清理:redis4.0之后可以使用unlink命令以非阻塞方式安全的删除大key
- 合理设置过期时间:设置过期时间可以让数据自动失效清理,一定程度避免大key的长时间存在。
- 合理设置淘汰策略:redis中使用合适的淘汰策略,能在redis内存不足时,淘汰数据,防止大key长时间占用内存
- 数据压缩:使用string类型,可以对value通过压缩算法进行压缩。可以用gzip,bzip2等常用算法压缩和解压。需要注意的是,这种方法会增加CPU的开销以及处理的响应延迟,同时也增加逻辑代码的复杂性
热key问题
概念:redis中某个key的访问次数比较多且明显多于其他key,则这个key被定义为热key
现象:
- Redis的CPU占用过高,效率降低,影响其他业务
- 若热key请求超出redis处理能力,会造成redis宕机,请求击穿到数据库,影响数据库性能
原因:某个热点数据访问量暴增,如重大的热搜事件、参与秒杀的商品
排查:
- hotkeys参数:Redis 4.0.3 版本中新增了
hotkeys参数,该参数能够返回所有 key 的被访问次数(使用前提:redis淘汰策略设置为lfu)
# redis-cli -p 6379 --hotkeys
- MONITOR命令:
MONITOR命令是 Redis 提供的一种实时查看 Redis 的所有操作的方式,可以用于临时监控 Redis 实例的操作情况,包括读写、删除等操作。该命令对 Redis 性能的影响比较大,因此禁止长时间开启 MONITOR(生产环境中建议谨慎使用该命令) - 根据业务情况分析:根据实际业务场景分析,可以提前预估可能出现的热key现象,比如秒杀活动的商品数据等
- 云商redis工具:云服务一般会提供redis的热key分析工具,合理利用,发现热key
解决方案:
- 热key拆分:设计一定的规则,给热key增加后缀,变成多个key,结合Redis Cluster模式,能分散到不同的节点。会带来业务复杂度,以及可能产生数据一致性问题
- 二级缓存:在应用和redis中间再引入一层缓存层,如本地缓存,来缓解redis压力
- 热key单独集群部署:针对热key单独做集群部署,和其他业务key进行隔离
更多技术干货,欢迎关注我!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号