kettle增量抽取数据--高效抽取方式
加入了一个数据汇聚分析展示的项目,其中数据抽取是一个很重要的环节,我接手之后发现kettle抽取速度越来越慢,不知道是服务器不给力还是数据库压力太大什么原因,在线搜索了很多优化方案:
1.调整JVM大小进行性能优化,修改Kettle定时任务中的Kitchen或Pan或Spoon脚本(选中kettle图标-->右键-->编辑,修改参数设置);
2、 调整提交(Commit)记录数大小进行优化;
如修改“表输出”组件中的“提交记录数量”参数进行优化,Kettle默认Commit数量为:1000,可以根据数据量大小来设置Commitsize:1000~50000;
3、 调整记录集合里的记录数;
4、尽量使用数据库连接池;
5、可以使用sql来做的一些操作尽量用sql;
Group , merge , stream lookup,split field这些操作都是比较慢的,想办法避免他们.,能用sql就用sql;
6、插入大量数据的时候尽量把索引删掉;
7、尽量避免使用update , delete操作,尤其是update,如果可以把update变成先delete, 后insert;
这些都做了,发现依然没有很大的改善,后来发现是我没有注意第“5”条,下面就来说说具体的操作方式(主要是主键对比去增量抽取):
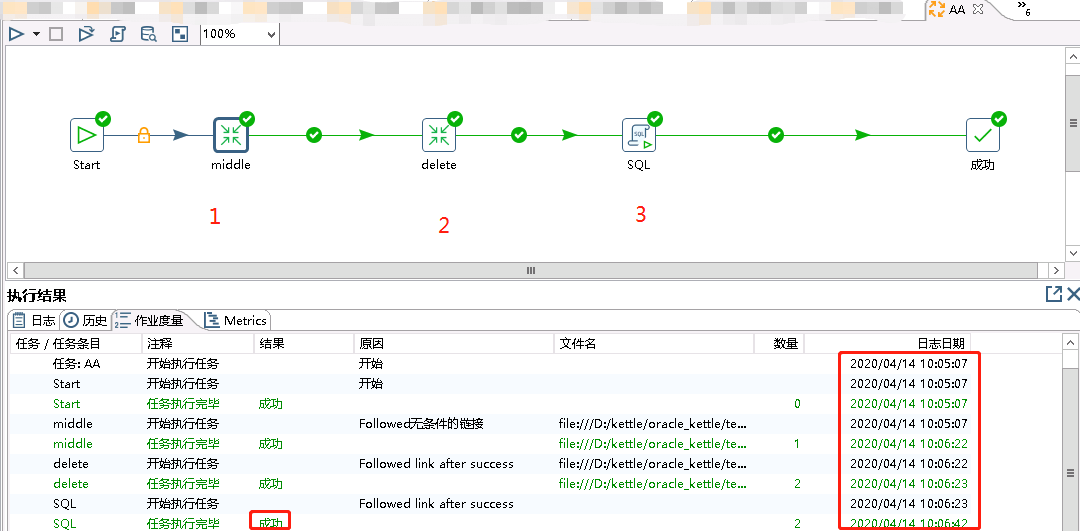
可以看到日志日期里面完成整个过程只需要95秒,我这张目标表有大概65万的数据库,表中有一百二十多个字段项,大小有五百多兆,这个速度相比之前还是很快的;
创建一个作业:
第一个步骤就是先将源表全量抽取到目标库中的中间表;
第二个步骤就是删除操作:对比中间表和本地表,删除需要删除的数据(这个不多说,大家应该都会的吧)
第三个步骤就是在左侧核心对象中找到脚本-->SQL,这个是在所连接数据库上执行所写SQL

merge INTO KETTLE.AA_CDPF_CITIZEN t1 using KETTLE.A_CDPF_CITIZEN t2 ON ( t1.uuid = t2.uuid )
WHEN matched THEN
UPDATE
SET t1.birthdate = t2.birthdate,
t1.business_id = t2.business_id,
WHEN NOT MATCHED THEN
INSERT (
t1.uuid,
t1.birthdate,
t2.business_id
)
VALUES
(
t2.uuid,
t2.birthdate,
t2.business_id
)
这里将SQL贴出来(只列了部分字段供参考),注意目标表和中间表的顺序,一定不要写错了,不然会报:>ORA-00904:标识符无效;这个SQL可以根据比对,如果存在且不匹配则修改,如果不存在则添加;修改和添加SQL后面可以根据需求添加条件;具体merge的用法,大家可以自行查询,oracle真的是个很强大的数据库,只要程序员实际需要的,都有相应的方法函数!
希望对大家有帮助,谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号