
Activation Functions
Sigmoid
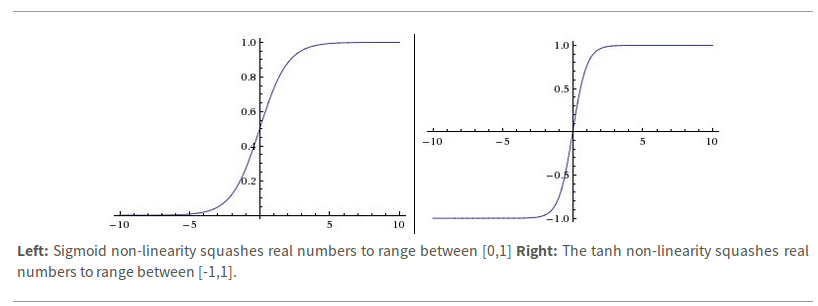
Sigmoids saturate and kill gradients.
Sigmoid outputs are not zero-centered.
Exponential function is a little computational expensive.
Tanh
Kill gradients when saturated.
It's zero-centered! : )
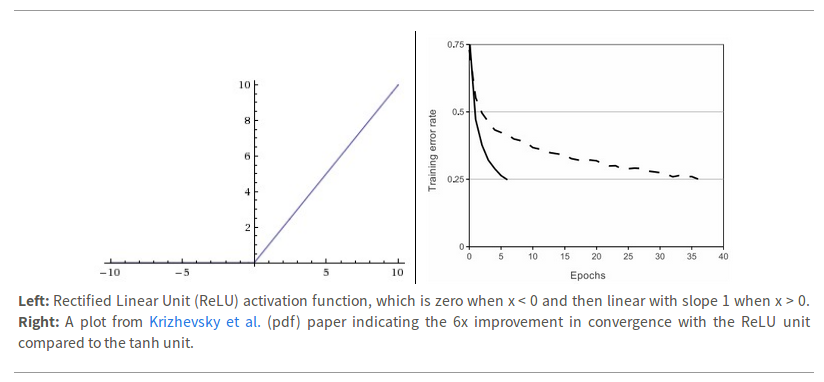
ReLU
Does not saturate. ( in positive region)
Very computational efficient.
Converges much faster than sigmoid/tanh in practice. (6 times)
Seems more biologically plausible than sigmoid.
BUT!
Not zero-centered.
No gradient when x<0.
Take care of learning rate when using ReLU.
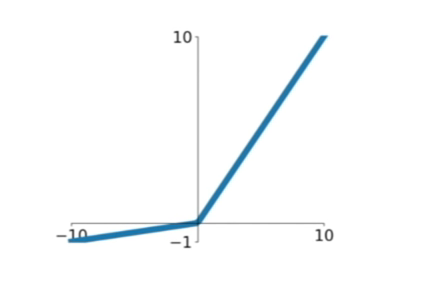
Leakly ReLU
Does not saturate.
Very computational efficient.
Converges much faster than sigmoid/tanh in practice. (6 times)
will not "die"
Parametric ReLU
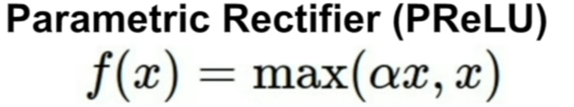
Exponential Linear Unit


