

pandas 关键操作
1. 利用loc、iloc提取行数据

import numpy as np import pandas as pd #创建一个Dataframe data=pd.DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('ABCD')) In[1]: data Out[1]: A B C D a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 d 12 13 14 15 #取索引为'a'的行 In[2]: data.loc['a'] Out[2]: A 0 B 1 C 2 D 3 #取第一行数据,索引为'a'的行就是第一行,所以结果相同 In[3]: data.iloc[0] Out[3]: A 0 B 1 C 2 D 3
2. 利用loc、iloc提取指定行、指定列数据
In[6]:data.loc[['a','b'],['A','B']] #提取index为'a','b',列名为'A','B'中的数据 Out[6]: A B a 0 1 b 4 5 In[7]:data.iloc[[0,1],[0,1]] #提取第0、1行,第0、1列中的数据 Out[7]: A B a 0 1 b 4 5
3. 选择C列大于6的行
index_C_big_2 = data.loc[data['C']>6] print(index_C_big_2)
4.
利用loc函数的时候,当index相同时,会将相同的Index全部提取出来,优点是:如果index是人名,数据框为所有人的数据,那么我可以将某个人的多条数据提取出来分析;
缺点是:如果index不具有特定意义,而且重复,那么提取的数据需要进一步处理,可用.reset_index()函数重置index
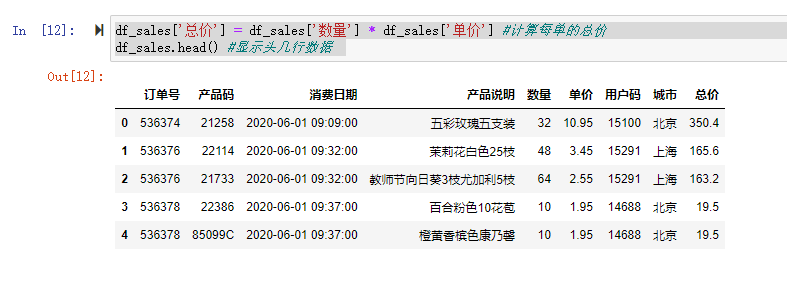
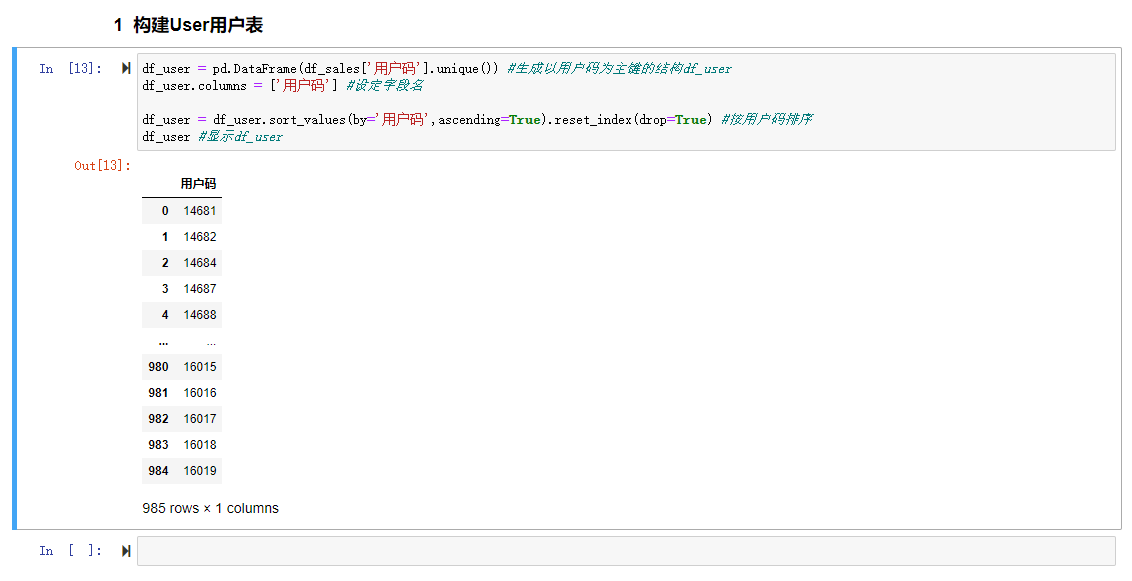
df_user = pd.DataFrame(df_sales['用户码'].unique()) #生成以用户码为主键的结构df_user df_user.columns = ['用户码'] #设定字段名 df_user = df_user.sort_values(by='用户码',ascending=True).reset_index(drop=True) #按用户码排序 df_user #显示df_user
————————————————
原文链接:https://blog.csdn.net/W_weiying/article/details/81411257
用一个例子来演示会更加清晰
分类:
python


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统
· 【译】Visual Studio 中新的强大生产力特性
· 2025年我用 Compose 写了一个 Todo App
2021-03-13 mysql技术点 + MySQL5 版本的组件架构示意图
2019-03-13 linux 修改内核参数 如何生效?
2018-03-13 haproxy + lvs异同(优点-缺点)