
grafana的metric的计算语句 - promql -irate + Histogram类型的监控指标 - 直方图 柱状图
1.磁盘使用率
1.other:((node_filesystem_size_bytes{fstype=~"xfs|ext4",instance="server2"} - node_filesystem_free_bytes{fstype=~"xfs|ext4",instance="server2"}) / node_filesystem_size_bytes{fstype=~"xfs|ext4",instance="server2"}) * 100 3.my: ((node_filesystem_size_bytes{fstype=~"xfs"} - node_filesystem_free_bytes{fstype=~"xfs"}) / node_filesystem_size_bytes{fstype=~"xfs"}) * 100
2.server1的内存使用率(单位为percent)
(1 - (node_memory_MemAvailable_bytes{} / (node_memory_MemTotal_bytes{})))* 100
3.CPU使用率(单位为percent)
1 - avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)
4.网络流出量(单位为bytes/sec)
irate(node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])*8
legend format:{{instance}}_{{device}}_out upload
5.网络流入量(单位为bytes/sec)
irate(node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])*8
legend format: {{instance}}_{{device}}_in download
参考:http://ju.outofmemory.cn/entry/373653
--------------------------------复习--------------------------------
1.Prometheus的配置
- job_name: 'node_111' static_configs:
- targets: ['10.0.0.111:9100']
labels:
instance: 11_9100
- targets: ['10.0.0.134:9100']
labels:
instance: 134_9100
2.promql - 主机CPU负载
(1 - avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance)) * 100
3.irate的理解 -- <prometheus监控实战> -- 【4.5Node Exporter和cAdviser指标】

https://yunlzheng.gitbook.io/prometheus-book/parti-prometheus-ji-chu/promql/prometheus-promql-operators-v2
6. Histogram类型的监控指标
Histogram的分位数计算需要通过histogram_quantile(φ float, b instant-vector)函数进行计算。其中φ(0<φ<1)表示需要计算的分位数,如果需要计算中位数φ取值为0.5,以此类推即可。
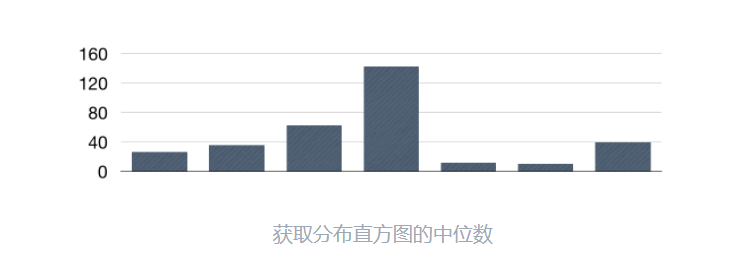
用一个例子来演示会更加清晰

 浙公网安备 33010602011771号
浙公网安备 33010602011771号