
强化学习入门知识与经典项目分析1.2
我们在上一篇文章中详细推导了马尔可夫奖励过程的贝尔曼公式,这一篇文章重点来推导马尔科夫决策过程的贝尔曼公式。
主要的学习资源是四个:
- B站许志钦老师的视频(主要入门理论)https://www.bilibili.com/video/BV15a4y1j7vg?spm_id_from=333.999.0.0
- 书籍《强化学习入门:从原理到实践》(叶强等著,机械工业出版社)
- github中的配套资源 https://github.com/qqiang00/Reinforce
- 书籍《强化学习精要:核心算法与TensorFlow实现》(冯超著,中国工信出版集团)
1.马尔可夫决策过程
在说到这个部分的时候,我觉得我们脑海中应该始终浮现着一个状态-行为链:
这个链条包含了两种状态转换:一种是从状态到行为的转换,是由智能体agent的策略决定的;另一种是从行为到状态的转换,是由环境决定的。这里的策略通常用字母π表示,是某一状态下基于行为集合的一个概率分布,公式定义如下:
马尔可夫决策过程(MDP)可以用<S, A, P, R, γ>五元组描述,其中:
- S是有限状态集
- A是有限行为集
- P是已知行为的状态转移概率矩阵:
- R是已知状态和行为的奖励函数:
- γ是衰减因子:γ∈[0,1]
根据上述定义,我们很明显的发现,马尔可夫决策过程相比于马尔可夫奖励过程,增加了行为选择这一部分。对于一个经典的马尔科夫奖励过程,仅仅只是状态链,上一篇文章已经证明了该贝尔曼方程:
在上式的基础上,考虑行为,就可以拓展出马尔可夫决策过程的贝尔曼方程:
如果=1,也就是说只有一种行为,,那么这时候的马尔可夫决策过程奖励实际上就和马尔可夫奖励过程一样了,二者的贝尔曼方程也一致了。换句话说,马尔可夫奖励过程就是马尔可夫决策过程的一个特例。从这个角度考虑,我觉得就很容易理解这个的拓展过程。
价值与贝尔曼方程
| 价值与贝尔曼方程 |
状态值函数
是在马尔科夫决策过程下基于策略 π 的状态价值函数,表示从状态 s开始,遵循当前策略 π 时所获得的收获的期望,也称长期回报,其公式定义为:
贝尔曼方程的证明方法一
如果觉得上文公式拓展的过于突兀,可以看下面这部分贝尔曼方程的具体推导
如果从状态-行为链的角度考虑,也可以定义为:
其中τ是一条的序列,一般是已知s和a采样得到的(s对应着t时刻)。表示一条τ序列的收获,表示该条τ序列的概率。
将展开代入可得到:
进一步填充省略号中的内容,采用代换消元的手法进行变换:
我们又可以得到关系式 ,因为每次离开同一个状态执行同一个动作得到的奖励都是同一个固定的值,这点和之前马尔可夫奖励过程很相似。把代入该等式就可以得到贝尔曼方程:
状态-行为价值函数
由于引入了行为,为了描述同一状态下采取不同行为的价值,定义一个基于行为价值函数,表示在遵循策略π时,对当前状态s执行某一具体行为a所能的到的收获的期望:
贝尔曼方程的证明方法二
根据定义,我们可以得到价值函数、策略、行为价值函数的关系:
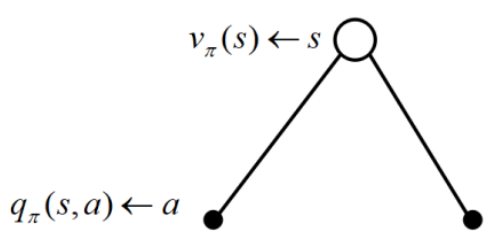
根据定义,我们也可以得到价值函数、状态转移概率、行为价值函数和奖励函数的关系:
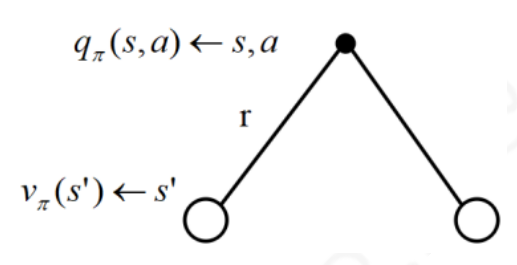
将上面两式组合就能得到:
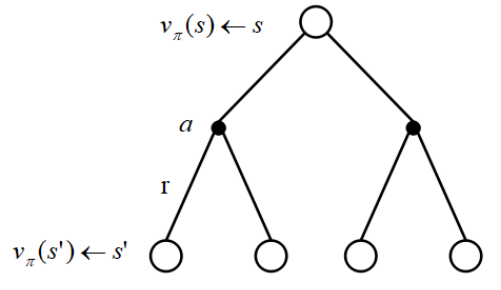
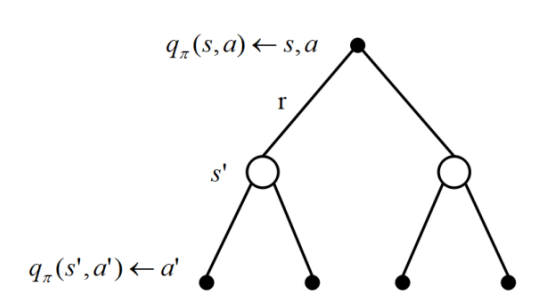
或者
马尔可夫决策过程实例
| 马尔可夫决策过程实例 |
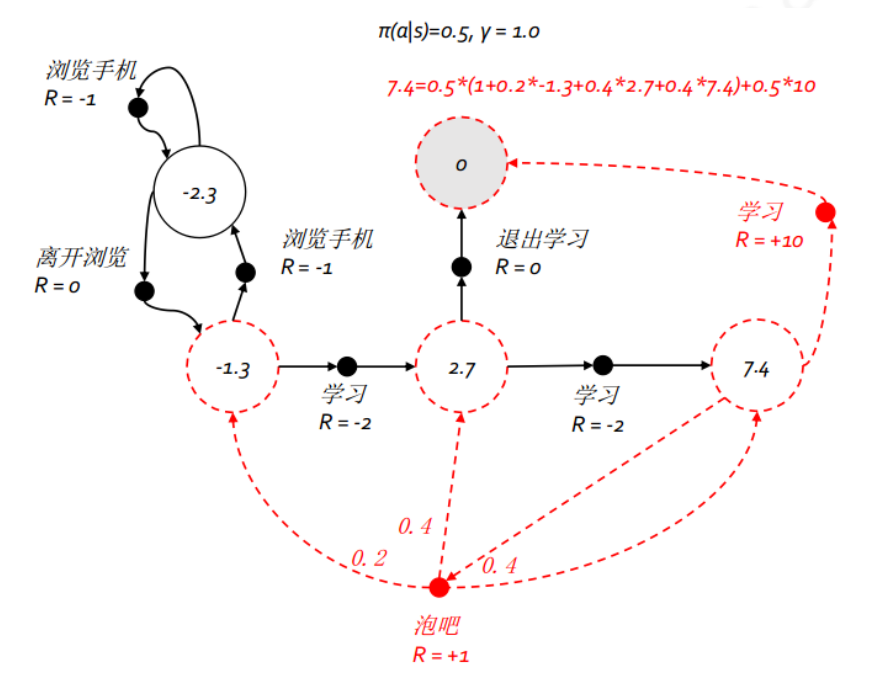
上图给出了一个给定策略下学生马尔科夫决策过程的价值函数。每一个状态下都有且仅有2 个实质可发生的行为,我们的策略是两种行为以均等 (各 0.5) 的概率被选择执行,同时衰减因子γ=1。图中状态“第三节课”在该策略下的价值为7.4,就是贝尔曼方程的运用,可以列如下方程求解:
本文来自博客园,作者:静候佳茵,转载请注明原文链接:https://www.cnblogs.com/hitwherznchjy/p/15937350.html



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步