
【LLM】A Survey of Techniques for Maximizing LLM Performance
本文成文于11月底,openai devday之后
背景:OpenAI最近放出了Devday的闭门会视频,其中"A Survey of Techniques for Maximizing LLM Performance"(精进大型语言模型性能的各种技巧)是非常有价值的,本文对这次分享做摘要。
视频:https://www.youtube.com/watch?v=ahnGLM-RC1Y&ab_channel=OpenAI
一、LLM的优化不是线性的
-
误区:线性的尝试多种优化策略

-
优化为有两个轴线方向考虑,
- 一个是Context优化,即模型需要了解什么信息才能解决你的问题。
- 一个是LLM优化,即模型需要以何种方式行动才能解决你的问题
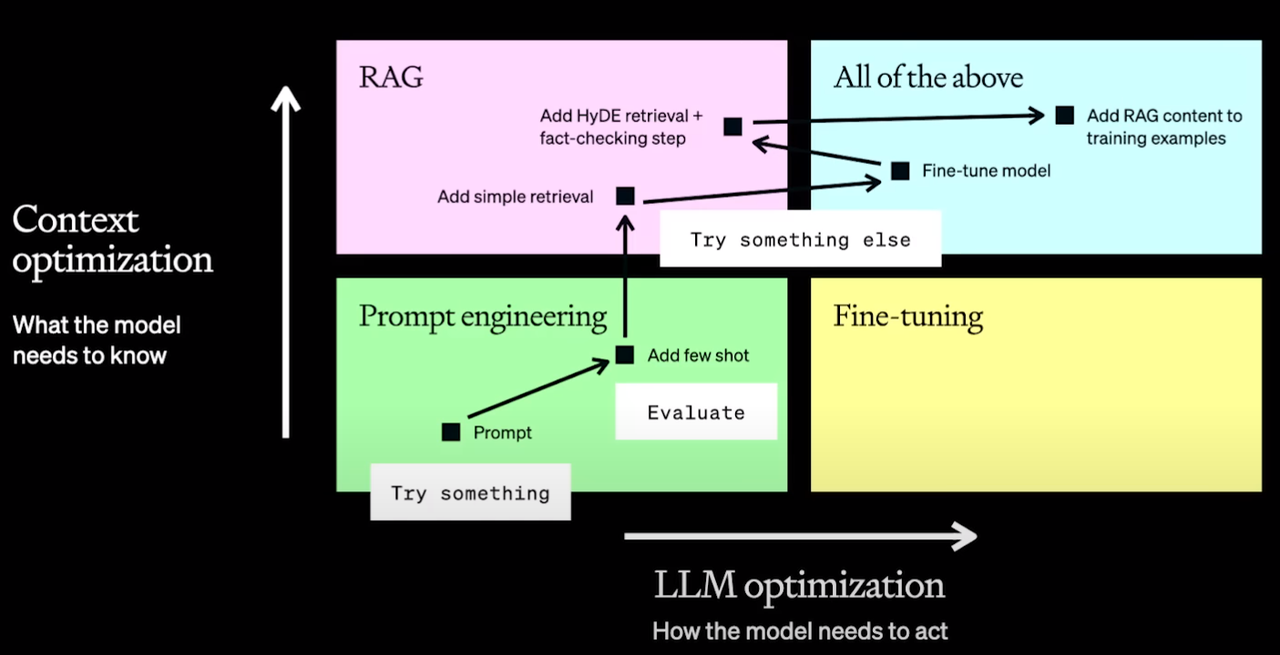
二、多种优化方法比较
| 擅长 | 不擅长 | 最佳实践 | 示例 | |
|---|---|---|---|---|
| Prompt Enginner 很好的起点,也可能是很好的终点 |
- 早期尝试,厘清需求 - 与评估相结合,提供基准线,并为进一步优化做好准备 |
- 引入新知识 - 可靠的复制复杂样式(如学习新的编程语言) - 使用较少的tokens |
详见 OpenAI tutorial - 编写清晰的指令 - 将复杂任务拆解为小任务 - 给GPT时间“思考” - Few shot - 使用外部工具…… |
 |
| RAG 如果你想让LLM掌握领域知识,用RAG |
- 向模型引入新信息,更新知识 - 通过控制内容减少幻觉 |
- 掌握对泛领域的理解 - 让模型掌握新语言、按某种格式输出 - 使用较少的tokens |
客户场景:多个domain的知识 - ✅ 余弦相似度计算 - ❎ HyDE 检索 - ❎ Finetune Embedding - ✅ 优化chunk策略 - ✅ re-ranking - ✅ classification (工程化) - ✅ tool use - ✅ query explanation |
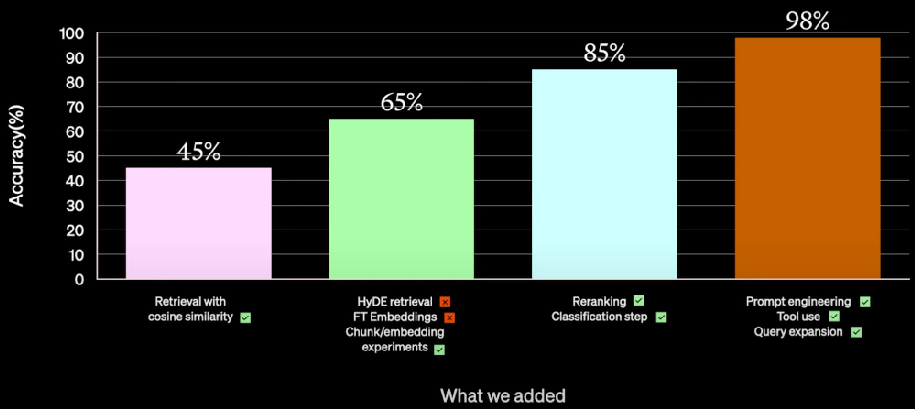 |
| Fine-Tuning 如果Prompt不起作用,finetune大概率也不行 |
- 激发模型中已有的知识,强化其在bad case上表现 - 定制输出的语气或结构 - 教模型认识一个复杂指令 - 提高正在特定任务上的表现、减少tokens消耗 |
- Base model中注入知识 - 快速在新领域尝试 |
客户场景:类NL2JSON - 数据准备(买 人标 大模型标) - 训练(要进一步理解loss func,代码训练可能不能使用交叉熵) - evalution (rank多个模型表现) - inference (部署优化) |
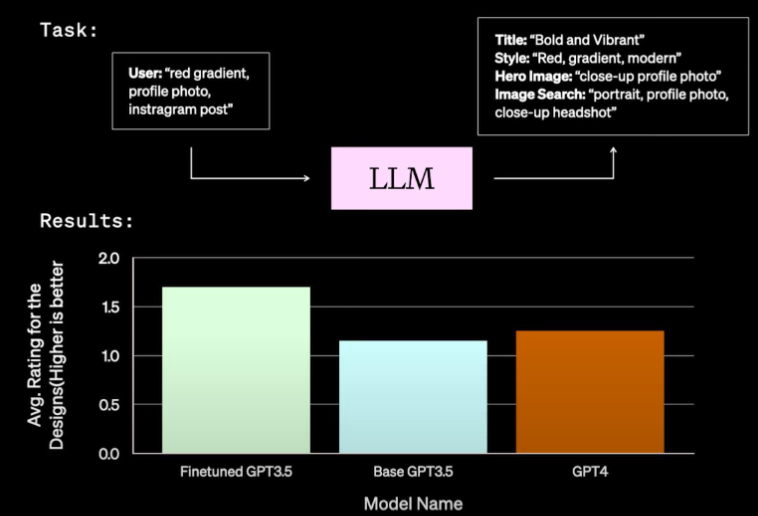 |
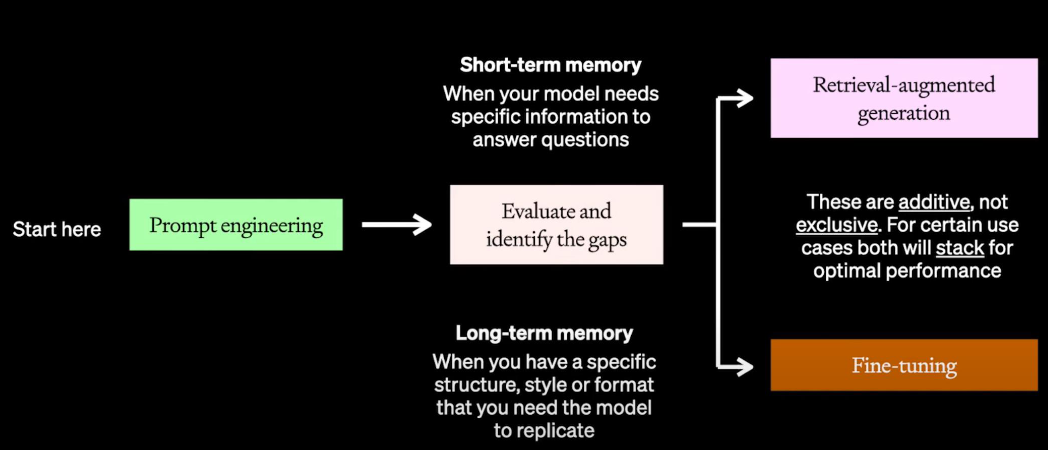
| All of all | - 微调模型来认识复杂指令 - 减少tokens消耗 - 使用RAG来注入知识 |
1. 先从Prompt优化开始 (使用低成本快速验证用户场景) 2. 获取baseline(确保有一个性能baseline来衡量微调后的模型) 3. 小步快跑、关注评测(先使用少量高质量数据) |
补充
- RAG的评测框架非常重要:ragas
| Generation | Retrival |
|---|---|
| Faithfulness 生成答案的准确率如何 |
上下文精确度 检索文档中的噪声比例 |
| Answer relevancy 生成答案跟问题的相关度如何 |
上下文召回率 问题相关的文档是否全部找到了 |
E-mail:hithongming@163.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号