【论文阅读】OrigamiNet:Weakly-Supervised, Segmentation-Free, One-Step, Full Page Text Recognition by learning to unfold
Introduction
- 任务特点:篇章文本识别,文本识别与文本分割相耦合
- 相关工作:
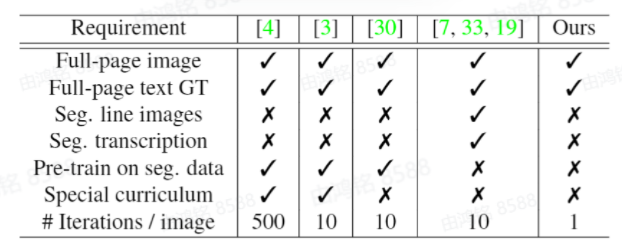
- 基于分割/无需分割方法,学界研究重心从seg-base变为seg-free,追求端到端识别
- 前人工作大多需要较多的GT
- 本文工作:
- 概述:OrigamiNet可以增强任何基于CTC的全卷积单行文本识别器,给予足够的空间容量就可以将其转换为多行版本,实现将2D输入信号折叠为1D并不损失信息。
- 本文特点:
- 基于CTC:CTC算法详解_Michael’s Blog-CSDN博客_ctc
- 弱监督:无需分割的标签和相关GroundTruth
- 不基于分割:端到端一阶段模型
- 全卷积:网络模型中只有卷积、池化、reshape(非线性插值)
- 多行文本识别:无需单行文本作为预训练
Methodology
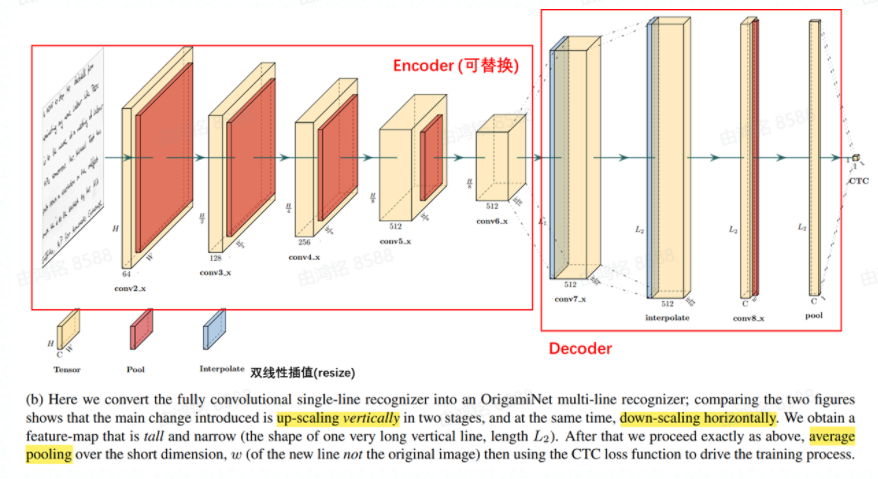
- 编码器可以换为其他的卷积网络(ResNet VGG)
- 编码器提取特征之后,[非线性插值 + 卷积] * 2, [卷积 + 平均池化] -> CTC loss
- L2的长度 > 单页的总字数,L1的设置可大约设置为L2的一半
- 最后一层平均池化之前,w的数值不能太大,宽度<32的效果较好
- 在第一层和最后一层后加layer-normalization
Discussion
- 对于难切分的样本识别效果好
- 可解释性分析:(字符的注意力区域)

E-mail:hithongming@163.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号