【华为昇腾】DB_ResNet精度调优 Siammask性能调优 模型众筹项目复盘
本系列博客内容均进行了脱敏处理,对于典型问题的相关处理经验可供其他开发者参考
项目背景介绍
为了满足当今飞速发展的深度神经网络对芯片算力的需求,华为公司于2018年推出了昇腾系列AI处理器,这一系列芯片的算力担当是使用达芬奇架构的AI Core,它能够对INT8 INT4 FP16进行高性能的计算。
下图就具体刻画了昇腾处理器中AI Core的结构和主要组成部分,其中主要包括计算单元、存储系统和控制单元的三部分。因硬件结构不是本文的重点,故不展开介绍,详情可参见昇腾官方文档。
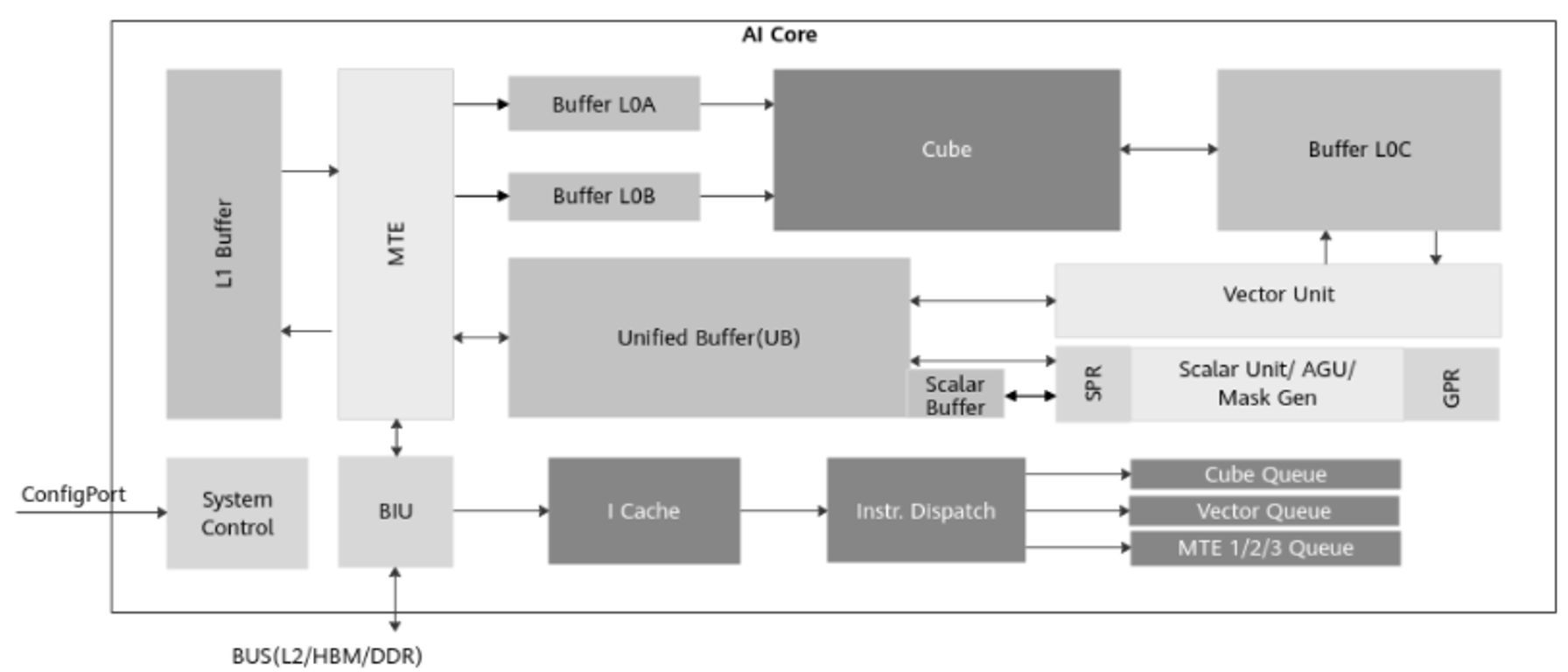
而为使昇腾AI处理器发挥出极佳的性能,华为公司还设计了一套完善的软件解决方案——CANN(异构计算架构),包含了计算资源、性能调优的运行框架以及功能多样的配套工具,下图就具体展示了昇腾AI处理器的软件架构(该图适用于我使用的CANN 3.x版本)。据我了解,在后续的版本中,CANN被重新架构为昇腾计算语言接口、昇腾计算服务层、昇腾计算编译层、昇腾计算执行层、昇腾计算基础层;如有时间,我将会额外写博文进行介绍。

依托这样的昇腾AI处理器和昇腾AI异构计算架构CANN,华为构建了昇腾生态并丰富了上层应用。而我们就对接从软件使能层到上层应用层的中间环节,针对复杂场景文本检测模型DB_ResNet和视频目标跟踪模型Siammask,完成代码的迁移、在基于昇腾AI处理器的Atlas800 服务器上进行训练、调优,并在Atlas300上进行推理和测试,最终产出两个适配于昇腾平台的模型。在这一过程中,遇到了一些具体的问题,在此进行介绍。
DB_ResNet的精度坑
DB_ResNet在项目的早期就完成了开源代码的调试和tensorflow版本代码的开发,在GPU上训练出了与预期相符的模型。但迁移到NPU平台后,出现了训练不收敛,loss明显波动的现象;在去除随机性并对齐双方参数配置后,仍出现如下图的问题。如图1展示的是使用tensorboard绘制的NPU上训练过程,图2展示的是在相同配置下,GPU上的训练过程,相关讨论详见如下链接

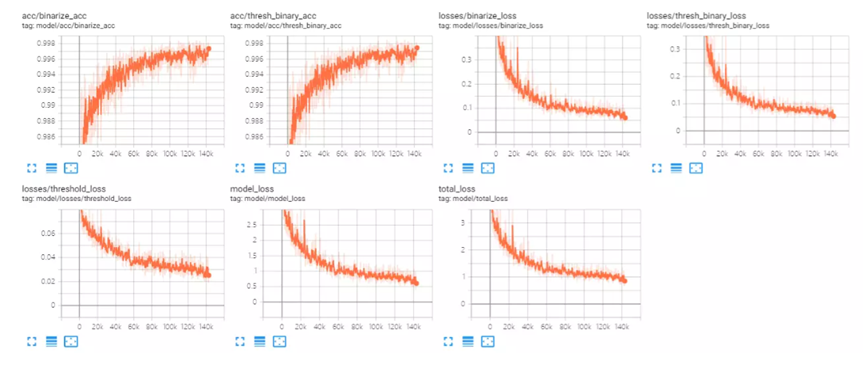
我们可以明显的看到迁移后的模型表现与预期不符,未能很好的收敛,我们在后续的项目进程中持续的就此问题进行探索。
探索一:排除动态算子topk的影响
在我们开发该版本代码时,平台暂不支持动态shape。而我们的模型使用BCELoss解决样本不均衡问题,在区分正负样本时使用了tf.math.topk这一算子。从代码流程的角度上看,假设每一批次中的正样本点有k个,则模型需要根据前向的输出筛选出得分最高的3k个负样本参与后续计算。而这就代表着,topk算子的输入k需要根据每一批次数据的情况进行动态的调整。这碰到了算子不支持的问题。
我们在早期的迁移中,为了减少开发周期,使用了一个较为简单的方案规避。即预先统计所有样本中正样本点数量的平均值,在模型计算中,都筛选3*avg_count数量的负样本点进行计算。在早期的讨论中,就怀疑过是由于这样粗略的规避方案,引发了模型的性能问题。因此我们实现了更优的规避方案,即在数据预处理阶段通过计算正样本的比率,并引入mask变量表明正样本数量;再把topk这个函数换为tf.sort,通过mask*sort的返回值实现topk的功能。

该方案有效地规避了动态算子的问题,并贡献在issue中供其他开发人员参考,但并未能解决收敛性问题。除了怀疑topk算子代码迁移的问题,我们还要考虑的似乎有更多。
探索二:使用data dump寻找出现下溢的算子
其实在早期的讨论中,我们就与华为方达成了一些共识,我们都认为AI Core算子以fp16的精度计算,模型中存在的类型转换可能引发了下溢的问题,造成了模型的不收敛。
在我们团队内部,也对模型计算出的梯度进行了可视化的展现,如图4所示,从整体来看,npu计算出的梯度分布相似于gpu上的分布,但仍有一定数量的较小值和0值。囿于时间限制,我们没有进行更深入的探究,而是做了一些其它尝试,最终得到了loss_scale + 截断的训练策略,使得模型得到了一定程度上的收敛,但最终的F值只有0.75,与GPU训练出的0.82有一定的差距。

鉴于华为内部团队的开发经验,类似的精度问题或收敛问题往往是由于某一算子的底层实现漏洞或错误使用造成的。因此我们在接下来大量的时间内,都在使用tfdbg配合data dump工具进行分析,试图找出出现下溢的算子。我们使用了修改融合规则、替换算子文件等手段,进行了如issue[3][4]的讨论,先后怀疑了batchnorm、adam、relu等的问题,但最后都无功而返,我们的怀疑往往因为考虑不够全面而被打回。与此同时,我们分阶段的测试前向和后向的过程,发现前向传播的全流程输出基本符合预期,而关于loss计算部分,我们借助data dump却未找到明显的漏洞。那个产生下溢的算子,似乎已经很难找到了。
探索三:放弃经验主义 探究loss scale
基于经验难以找到溢出算子,我们不妨回归loss scale的方案,为什么使用这样的方法就能够使得不收敛的模型产生一定的收敛效果呢?
我们使用了最朴素的做法,将关键步骤的中间结果全部打印出来。我们发现,由于整网中流动的数字都较小,尤其在经过log(1+x) 函数之后,模型中流淌较多的超过fp16表征范围的数字,这就引起了fp32向fp16转换时的下溢。这一现象在data dump过程中也有一定的表现,但当时认为参数的方差差距较小,对模型的影响较小,从而忽视了相关问题,这也是需要在SOP中改进的。
使用loss scale是解决这一问题的有效办法。我们之前根据调优经验,设定全局loss scale为212,但这个值其实是可以在训练的各个阶段进行调整的。经过华为老师们的不断努力,我们通过手动调优的方式,最终得到了最优模型F值为0.76,照初始精度有了一定的提升。在平台提供的工具中,也有自动化动态调整loss scale的接口,但在项目开发周期内,由于该功能在处理MaxPoolGrad 算子时存在溢出而无法使用。因此可以后续跟进研发进程,进行更多的测试。
小结
总的来说,在训练过程中产生 精度劣化的原因主要有算子融合、算子精度不足、常量折叠、fp16精度不足、网络中存在“放大器结构”等等。使用tfdbg进行data dump,配合华为提供的比对工具可以较为有效的找到出现问题的算子。但造成精度问题的原因不全是算子问题,当前比对的维度包括余弦相似度、最大绝对误差、累积相对误差、欧氏相对距离、KLD散度、标准差几个维度。仅通过这几个维度能否很好的描绘出各种场景的精度损失原因,这是值得思考和讨论的问题。华为也在不断地更新精度分析工具,甚至推出了 一键比对工具 点个赞!
Siammask的速度坑
该模型作为针对视频场景下的复杂网络,训练所需的成本极高;其需要的总数据集达数百G,在GPU的训练总时长也达5天之久;而我们在迁移到NPU平台上训练后,遇到了较为明显的速度问题。具体来看,在训练过程中每50个step就会发生阻塞,停下来报tf_adapter/kernels/geop_npu.cc,训练50个step的时间是2s左右,但是停下来报信息的时间可能超过20分钟,整网单步的平均训练时间达50s之久!GPU和NPU二者之间有60余倍的速度差异!相关讨论详见issue
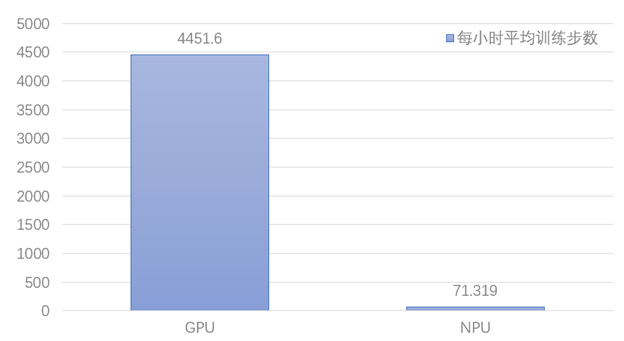
而我们也就针对上述的现象进行了长久的尝试,最终速度达到了与V100上平齐的水平,在下文中,我们将对各阶段的尝试进行更具体的介绍。而在该模型复现的过程中,我们也发现开源代码与论文刊登不匹配的问题,我们也将把一些佐证材料在本节中进行具体的展示。
探索一:排除不支持算子extract_image_patches的影响
在我们开发的版本中,tf.image. extract_image_patches在算子编译过程中报错,该算子可以视作卷积的一部分,用滑动窗口取patch,但没有filter,也没有将patch和filter作卷积的操作。在我们的开发版本中,由于泛化性的问题无法使用,而我们也针对这样的情况进行了替代性开发。
我们提出了三种实现方式,一是使用卷积的方式进行替代;二是使用py_func的方式进行实现,三是使用内循环的方式实现功能。我们也将这三个方案的代码分享到了issue中,供其他团队参考使用。
经过测试之后,我们决定使用自实现的方案二作为替代手段训练,我们在GPU上测试未发现明显的性能损失,迁移到NPU后也成功打通了整网。但我们通过profiling工具分析后发现,仅这一步操作在NPU上就有22s的耗时,而这大概率和CPU与NPU之间频繁的信息交互相关,针对不支持算子的替代性方案引入了很大的速度损耗。此外通过profiling,我们也发现resize_bilinear算子的支持度不够,耗时较长。
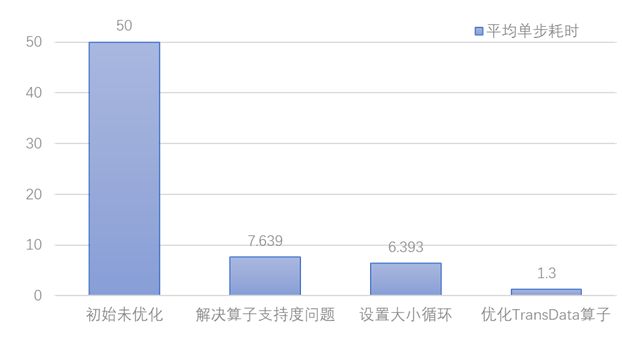
在明确了问题源之后,我们的项目主管老师推动工程师团队对该算子进行了泛化能力的开发,使其能够处理我们模型中相应规格的数据。产出新版本算子后,我们替换算子文件重新训练,每步的平均执行时间从50s降至7.639s,有了很大的提升。
探索二:设置大小循环,进一步加快模型速度
在等待工程师团队开发出新版本的同时,我们也针对耗时较长的resize_bilinear单算子在AICore上尝试使用大小循环的方式进行训练,通过减少Host和Device之间的通信,更加充分的发挥NPU的计算性能;如issue中讨论的内容所示,我们设置每1000轮进行一次CPU与NPU的通信,且不适用TDT的方式运行。我们发现在单算子的测试场景下,每步的平均耗时从设置前的34s下降至设置后的21.9s;虽仍与GPU上的运行速度有较大的差异,但证明大小循环的方式对于性能提升是有效的。
而当新版本算子文件替换之后,我们也将上述的经验应用于实践中,使得端到端的平均单步训练时间从7.639s下降至6.393s,模型性能进一步提高。
探索三:优化TranData、Five2Four算子,模型速度符合预期
项目主管老师后续继续跟进模型性能问题,在CANN 3.2.0版本上替换或增加了five_2_four.py, trans_data_negative_target_tc.py, trans_data_common_func.py等三个算子文件后,SiamMask网络在NPU上训练了5000step,每step耗时下降到约1.2~1.6秒之间,与竞品耗时相当;而整网的耗时问题也得到了闭环解决,如图所示,通过一步步的调优,模型速度最终符合预期。
小结
总的来看,CANN软件栈还是很大程度上的激发了昇腾AI处理器的计算能力,最后的性能比V100还要好。但为了适配AI Core的计算需求,CANN会在网络中插入TransData、trans_Cast等等算子,部分插入的算子会引入很大的性能问题。且在实际运行中还偶有AICore和AICPU之间的频繁交互,这都可能造成性能劣化。虽如此,但还是要给华为的技术支持老师们点个赞!能够对我们提出的问题很快的响应,也能针对我们的需求进行适配开发。相信随着CANN在越来越多的模型上得到应用,潜在的问题会被一个个解决,能够适配应用到越来越多的场景中。
回顾与反思
1. 作为PM不能太执拗于过往经验,要更多的结合实际场景进行分析;
2. 混合精度计算本就是一个复杂问题,尤其在复杂网络中。如无必要,勿增实体;在之后的项目中,要提前审视技术实现难度(但混合精度的确速度有提升,在业务代码未很好优化的前提下,还比V100的速度快);
3. 尽量不使用官方已经不维护的内容,无论是tf.slim还是tfdbg;
4. 要学习华为技术支持的响应速度,遇到算子精度和性能相关的问题, 在modelzoo上提issue,响应速度很快!官方修复后会更新在社区版本中,然后就可以进行验证了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号