【论文阅读】An Empirical Study of Architectural Decay in Open-Source Software
2020-06-19这篇文章是我学习 软件架构与中间件 课程时分享的论文。可以说,这篇文章塑造了我基本的科研观,也养成了我如今看论文的习惯。感谢老师们,也感谢恒恒对我的帮助。
一、 对问题的概述
1.1. 基本概念
架构腐化(architectural decay)是指软件架构性能随着时间和版本的迭代而逐渐恶化或可维护性递减的现象。软件系统在生命周期内被修改或引入新的决策时,往往产生架构腐化。如图1所示,即为开源项目Chukwa的软件体系结构图,在版本更迭时引入大量依赖,造成架构腐化。
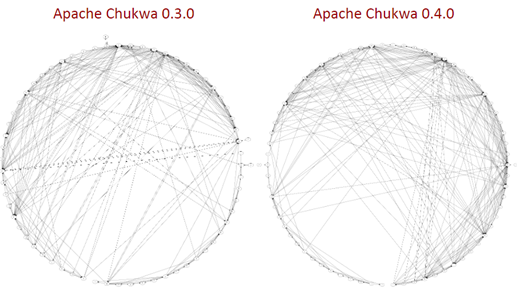
图 1 架构腐化常在版本更迭时产生
架构异味(architectural smells)则是架构腐化的具体表现,其指的是在架构层次上不良设计决策的实例。其源于对软件架构及抽象(如组件、接口等)的不恰当使用,如表1所示,架构异味可分为如下17个类别。
架构异味的产生将会对系统的可理解性、可测试性和可复用性产生负面的影响,而之前的相关研究多依靠个人经验,缺乏对其影响的实例验证,而本文就将对这一问题进行讨论。
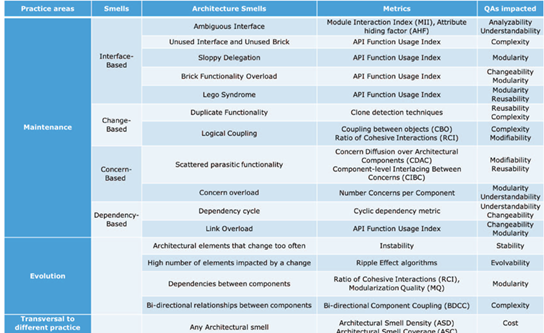
表1 架构异味的分类
1.2. 写作动机
1.2.1. 前人工作的缺陷
整体来看,前人的工作主要依赖于个人经验和小范围案例的研究,结论不具有普遍性。而就其研究方式而言,前人往往着力于用代码异味来表示架构层的问题,但代码异味与架构异味在定义和功能上都有较大的差距,架构异味也不能视为代码架构的抽象,实验中的效果表现不够良好。
学者随即提出设计异味(design smells)来表示一组代码异味,这样的做法有一定的指导性意义,但其往往会指出一些非架构问题,表现效果不够准确。
1.2.2. 本文工作
本文的工作重点主要在以下几个方面:
- 选择具有代表性的架构异味,实现了自动检测异味的算法;
- 引入了问题库(issue repositories),通过发掘架构异味与问题之间的关系,衡量异味对系统的影响;
- 利用ARCADE模型和大量实例证明了架构异味对系统是有害的。
二、对模型的理解
2.1. ARCADE模型概述
如图 2 所示,本文设计了一种用于架构恢复、修改、腐化评价器的模型,其中包括多种软件架构恢复技术和用于测量架构变化不同方面的一组度量。
按照功能可将其分为如下模块:软件架构还原(Architecture Recovery)、气味识别(Smell Detector)、问题跟踪系统(Issue Tracking Systems)和主实验分析模块。
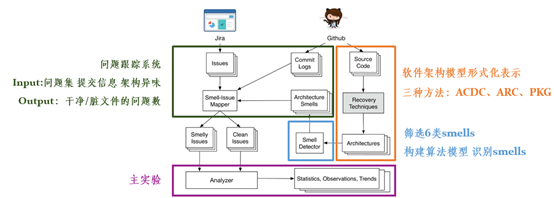
图 2 ARCADE模型示意图
从Github中获取的源文件交由软件架构还原模块进行处理,生成软件架构的形式化表示(Architecture),接下来交由气味识别模块进行异味识别。形成的架构异味信息配合从Github中获取的版本提交记录和Jira提供的问题库,作为输入提交给问题跟踪系统,最终将最终交由分析模块进行验证分析,得到最终的正确结果。
2.2. 软件架构还原
软件架构恢复指的是从实现构件中恢复系统体系结构的过程,而常见的实现架构包括源代码、可执行文件和.class文件等。我们用图表示软件体系结构、用结点表示组件、用边表示依赖关系和逻辑耦合,而对于每一个节点C,还可以用实体E来构成。
如下图所示,即表示架构A由组件C1和组件C2构成,组件由多个实体构成,1和4、3和5之间存在依赖关系,2和3之间存在逻辑耦合。
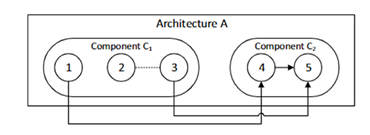
图 3 软件体系结构实例
在本文中共采用三种架构恢复方法,第一种为理解驱动的聚类算法(ACDC),第二种为利用关注点的架构恢复方法(ARC),第三种为包结构的恢复方法(PKG),三者分别着力于组件、关注点和包级结构进行架构还原。三种技术独立开发,且在前人的工作中被证明有效,利用多种恢复技术也保证了架构视图的准确性。
在将软件架构转化为示意图后,系统还将模型用形式化的语言进行表示,具体看来满足如表2所示的规则。值得注意的是,实体e由接口I、连接关系L和耦合关系Cp共同构成,而L和Cp均由源src和目的dst构成。在Java中实体e可以视作类,接口I可以视作公开方法。
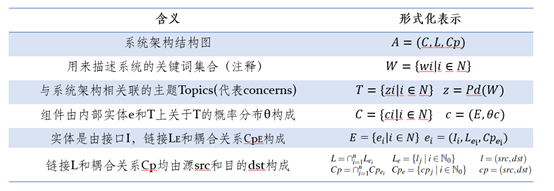
表2 结构化表示规则
2.3. 异味检测
如上文所说,根据前人的研究,共有17种常见的架构异味,但在本实验中,我们依据不重复、不主动引入认为因素、不考虑连接器、满足软件架构基本点的原则进行筛选,选出以下六种作为实验中检测的异味,他们分别为:关注过载(Concern Overload)、循环依赖(Dependency Cycle)、链接过载(Link Overload)、未使用接口(Unused Interfaces)、草率委托(Sloppy Delegation)、共变耦合(Co-change Coupling)。接下来我们就需要设计算法识别上述六种异味,在算法实现中,我们使用四点分距法判断阈值。
【dectCO】在识别关注过载异味时,我们先判断每个组件实现了多少关注点,再判断实现多少关注点是过载的。借助四点分距算法,我们能够识别出哪些组件实现了过多的关注点。
【dectDC】循环依赖违反了模块化的原则,我们可以使用判断强连通图的经典方法来判断是否存在循环依赖
【dectLO】连接过载的判别方法类似于关注过载,只是要转为确定组件的出度和入度,然后用四点分距判断连接过度的组件/
【dectUI】无用接口增加了不必要的复杂度,不利于系统的维护。在算法实现过程中,我们只需要遍历每一个实体的接口I,如果其没有被调用,则为无用接口。
【dectSD】草率委派将关注点不合时宜的拆分,增加了数据流和控制流的复杂度。在算法实现的过程中,如果一个实体被调用的次数过低且不调用其他实体,则我们认为存在草率委派。
【dectCC】耦合有时候是必要的,但过度的耦合关系就会破坏原有的架构结构。本算法就是为了找出耦合度过高的实体,先计算组建的耦合度,再判断耦合度高于阈值的组件,完成判断。
以上六种算法共同作用,形成了异味检测模块,能够自动识别软件架构文件中的臭文件并将其返回。
2.4. 问题跟踪系统
Jira是一个问题管理系统,他保存了开源软件在生命周期内被提出的所有问题。本实验选用的开源软件均使用Jira作为管理工具,本实验中也利用Jira提供的问题库(issue repositories)进行识别和判定。
Jira系统除了使用问题库作为输入外,还利用了从GitHub中获得的提交记录和上文中得到的架构异味信息。通过分析问题与异味之间的关系,若问题和异味均影响同一版本且问题的解决影响了臭文件,则称两者相关。而这一模块就时识别出问题与异味之间的关系并将相关信息返回。
三、 对实验过程和实验结果的理解
3.1. 数据集设置
任务采用了如表3所示的8个开源系统的421个版本,共计376M行代码,累计获取了4万余个相关问题。所有开源项目均使用Apache开发,其具有维护良好的数据库、发行说明和bug追踪器,便于后续的研究;所有开源项目也均使用Jira作为问题管理系统,便于追踪问题和修复提交。
任务也利用了3种不同的架构还原方法,形成了1263个结构模型,识别出了6种共17余万个架构异味。
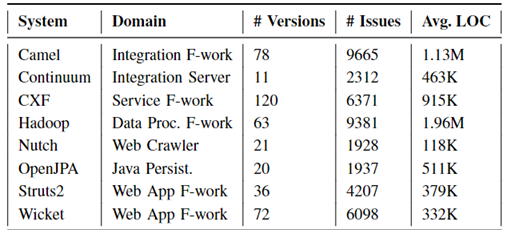
表3 采用的开源项目一览表
3.2. 实验结果
3.2.1. 主实验
为了探究架构异味对系统的影响是如何显现出来的,作者做了两个假设。
假设一:臭文件比干净的文件更可能出问题;
假设二:臭文件比干净的文件更有可能发生改变;
在主实验环节,作者就利用了上述的ARCADE模型进行了分析,得到如表4和表5的结果。在表4中统计出了每个文件平均的问题数/修改提交数,也用2-sample t-test方法验证了结果非偶然误差导致。
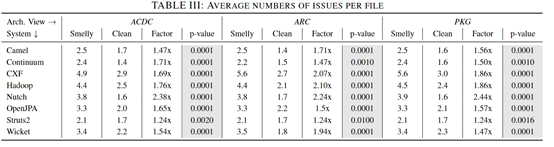
表4 验证H1
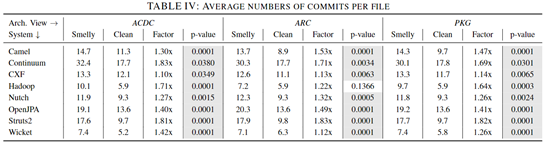
表5 验证H2
实验结果显示,在95%的置信度下,臭文件比干净文件的错误率提高24%-110%,修改率增加10%-83%,两个假设都得到了证明。
实验中亦有一个反例出现,猜测是smells类型不同造成影响,仍需后续研究证明。
3.2.2. 辅助实验
论文中还分析了Camel系统的78个版本在ACDC方法下的文件特点。
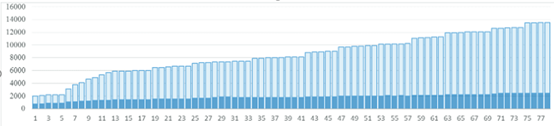
图 4 不同版本中的臭文件
如图4 所示,我们可以发现,臭文件在第一个版本就产生,且架构腐化的问题真实存在。
论文中还分析了文件长度与异味之间的关系,横坐标为文件大小,纵坐标为臭(或干净)文件在该长度中占的比例,不同于以往的研究,本论文发现,架构衰退与文件大小无关。
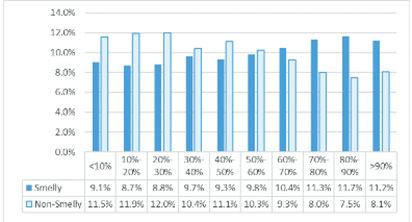
图 5 架构异味与文件大小之间的关系
四、Contribution
4.1. 创新与贡献
本文的创新点主要有以下几项:
- 验证思路创新:不再通过研究code smells来分析架构问题,而是直接基于架构恢复技术,利用ARCADE进行分析验证
- 实验设计创新:前人的工作针对的训练集较小,且没有依赖架构异味作为架构腐化的实例进行分析,而本文针对更多开源系统的更多版本、多种架构恢复方法进行实例研究
本文同时对该方向研究产生了以下贡献:
- 在多个数据集上使用ARCADE验证猜想,证明架构异味对系统有害。
4.2. 有效性分析
ARCADE的有效性来自于以下几个方面:
- 使用了三种体系结构恢复技术保证架构视图的准确性;
- 使用被证明有效的架构异味类型,并使用常见的阈值法筛选。
- 使用被证明有效的 架构异味类型,并使用常见的阈值法筛选。
4.3. 后续研究
在未来研究中,本文希望集中于以下优化方向:
- 在分析模型中考虑改变的代码行数,这一影响因素。
- 利用ARCADE模型预测架构腐化和潜在的问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号