小白学习Spark系列二:spark应用打包傻瓜式教程(IntelliJ+maven 和 pycharm+jar)
在做spark项目时,我们常常面临如何在本地将其打包,上传至装有spark服务器上运行的问题。下面是我在项目中尝试的两种方案,也踩了不少坑,两者相比,方案一比较简单,本博客提供的jar包适用于spark版本2.0以下的,如果jar包和版本不对应会出现找不到类或方法等错误提示信息,它主要借助于eclipse和现成的jar包进行打包应用,只能从官网上下载对应的jar包,局限很大。方案二是借助于IntelliJ + maven方式,它只要配置好pom.xml文件,在文件中写明自己的运行环境即可,通用(推荐),另外IntelliJ软件炒鸡好用,建议大家不要由于自己习惯哪款软件就先入为主。
1.准备工作
scala:在本机上装scala,下载链接 https://www.scala-lang.org/download/ ,如果是在windows下,请下载 msi 版本。

jdk:下载链接 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
如果是需要在本地打包后上传至装有spark的服务器上运行,则务必保证本地和服务器上版本保持一致,否则会导致找不到类或方法等错误。
2. 方案一:eclipse打jar包(适用于spark2.0以下)
(1)安装 eclipse和配置完java环境后,在工具栏 Help -> Install New Software,输入scala ,通过链接下载运行scala代码的插件。
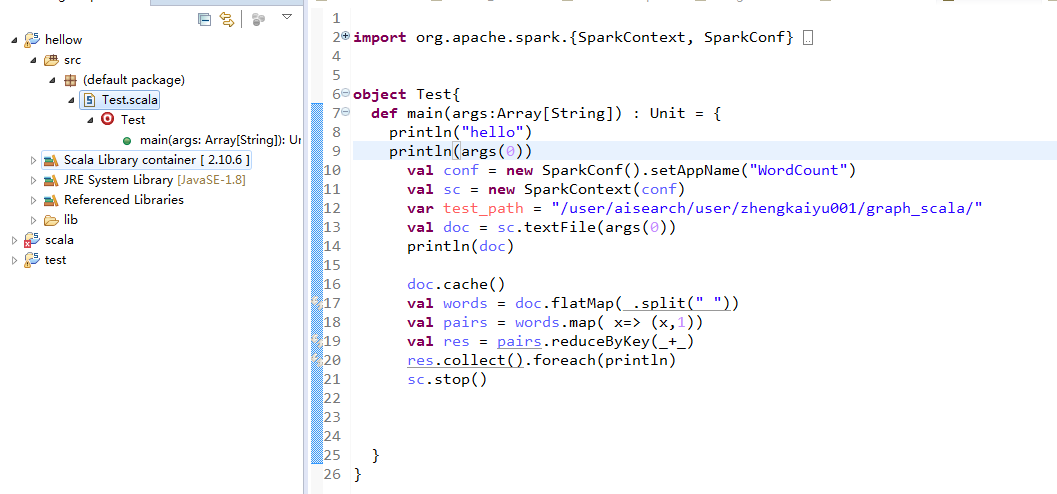
(2)下载插件后,新建一个scala工程,测试Spark程序,统计单词个数。
(3)在工程下新建目录 lib,将两个jar包(hadoop-0.20.2-CDH3B4-core.jar,spark-assembly-1.6.3-SNAPSHOT-hadoop2.5.0-cdh5.3.2.jar)拷贝到 lib 下,选中这两个jar包右击 Build Path,加到Referenced Libraries中。
jar包下载链接:https://pan.baidu.com/s/1dQjJR8vtl01wp6JLEgRp3w 密码:20hh
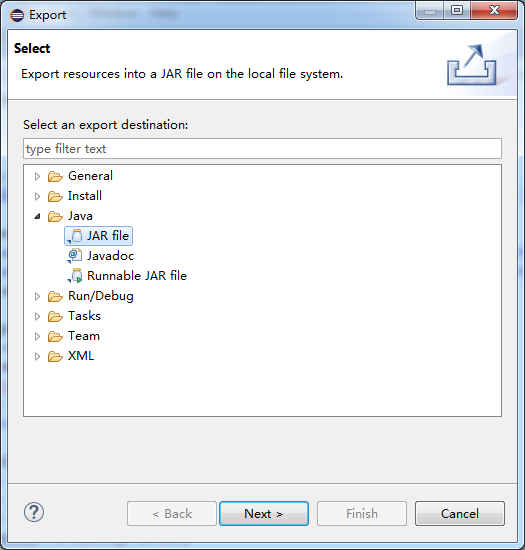
(4)选中工程,右击,选中Export,选择JAR 文件->Next,只选择src文件,填写保存位置和名字。

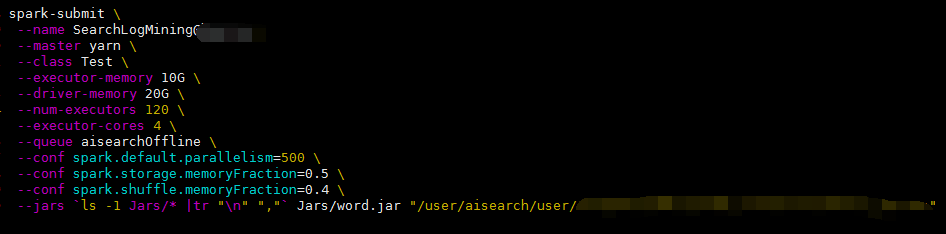
(5)把jar包传到安装有spark的服务器目录下,写好submit脚本(如下图所示),这里我新建了Jar目录,把jar包放到该目录下,后面紧接着是传递给函数的一个参数(文件路径),执行该脚本。
(6)如果出现 找不到类等错误,一般就是版本出现了问题。我在eclipse中加载了hadoop和assmbly的jar包后也提示了该错误,当时没选择对scala的版本,可通过如下方式改变其版本,选中 scala library container后右击 properties,选择2.10.6版本。当然,你需要这些版本和服务器上装有的spark、scala、hadoop版本一致才可以。这种方式需要从网上找版本一致的jar包,体验很差,不推荐。

2. 方案二:IntelliJ + maven(推荐)
(1)安装IntelliJ
下载链接 https://www.jetbrains.com/idea/download/#section=windows,选用右边的Community版本就ok。
(2)安装IntelliJ中的scala插件
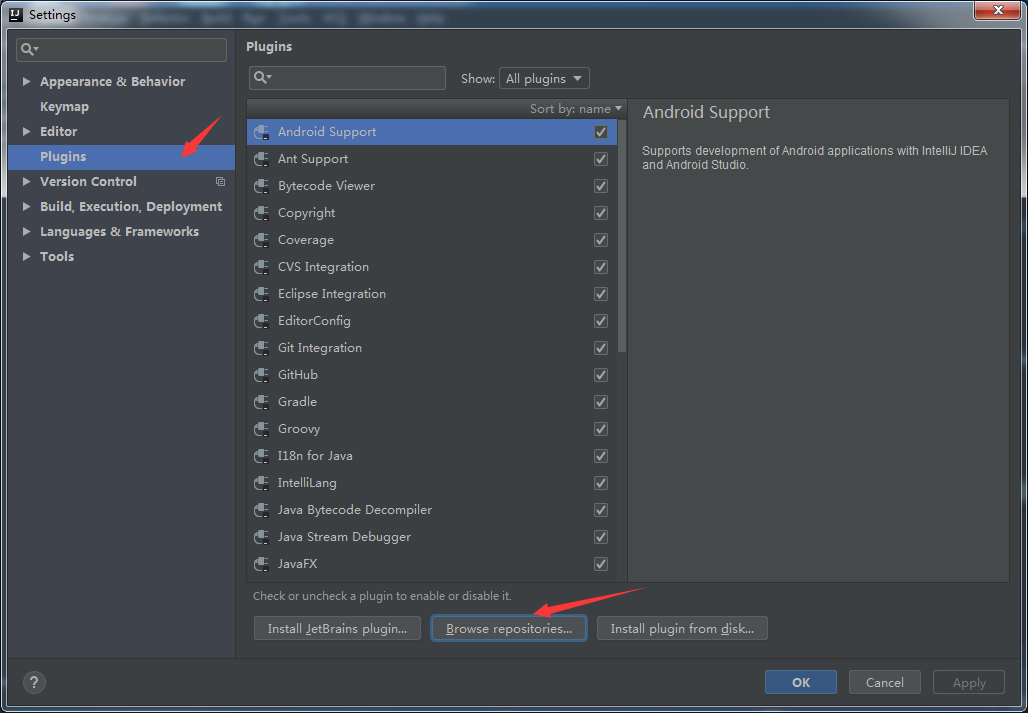
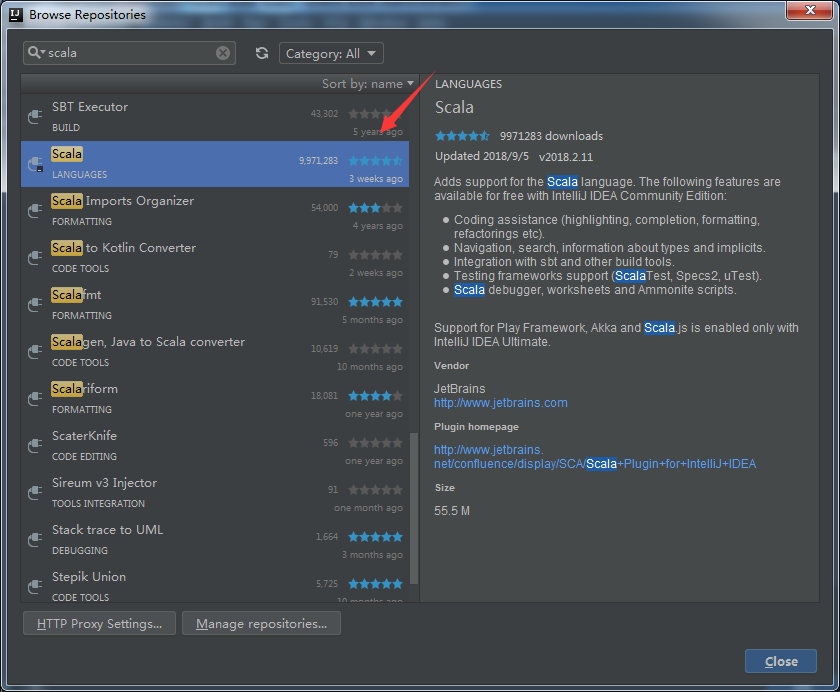
如果在主界面可通过 File -> Settings -> Plugins -> Browse respositories 的方式安装scala插件,具体如下图所示。由于这里我已经安装完毕,所以没有显示 Install 按钮。如果刚装完 IntelliJ,进入初始界面,可选择右下方的Configure -> Plugins 来安装scala插件。
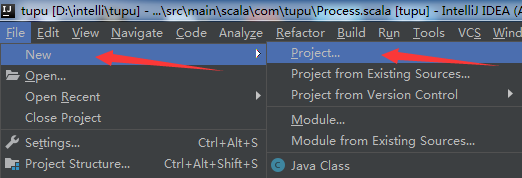
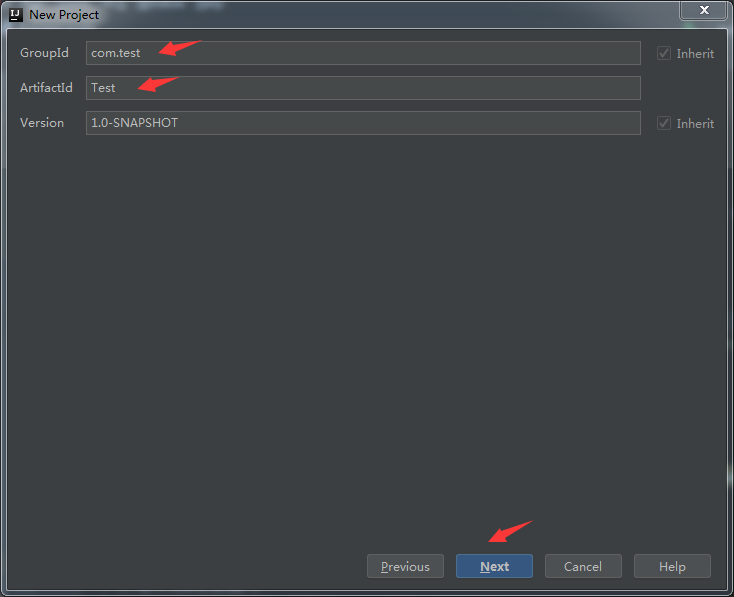
(3)新建maven项目
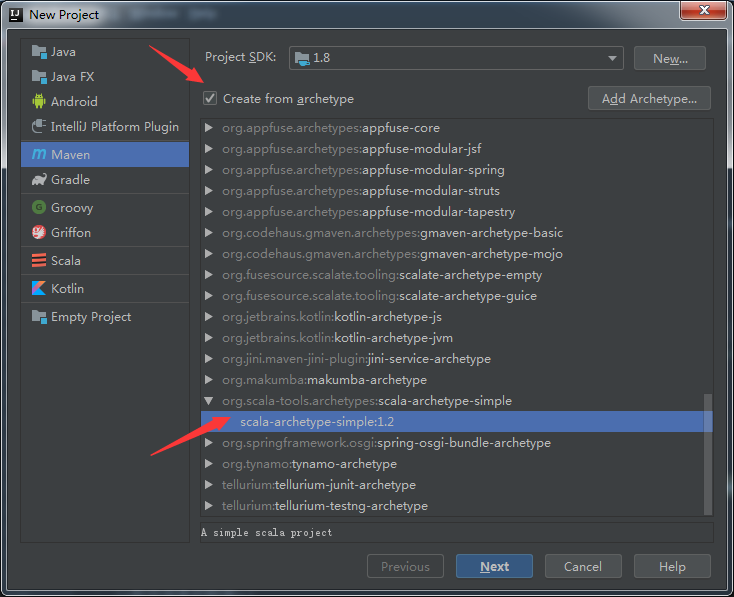
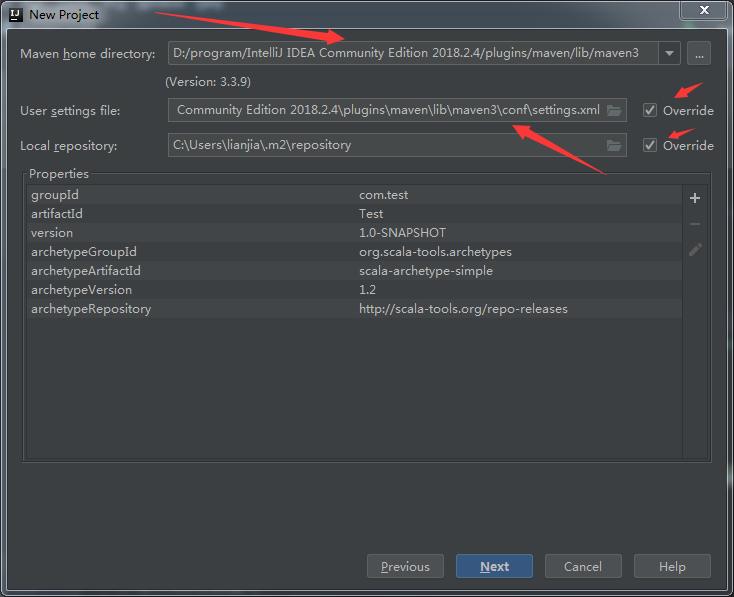
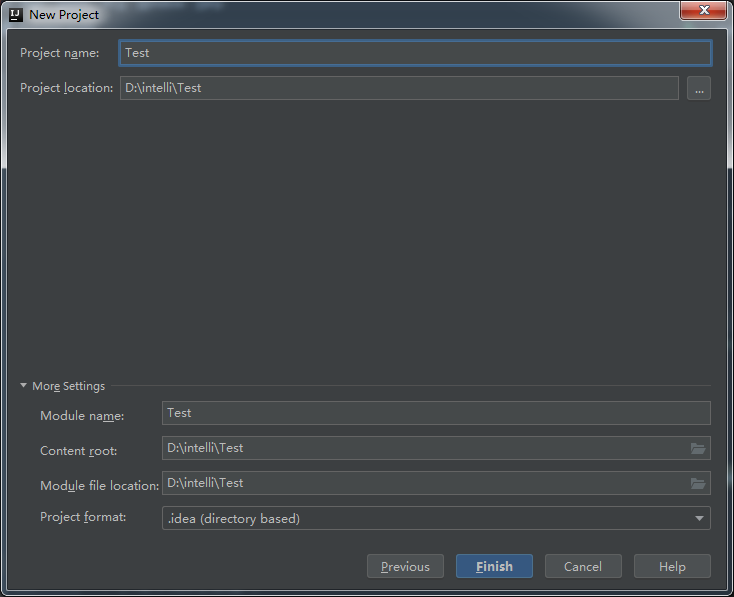
最新的IntelliJ中一般都会安装有maven,这里通过 File -> New -> Project -> Maven 新建maven项目,在配置maven页面需选中复选框,选择scala-archetype-simple:1.2 ,点击next,填写信息自己随意起名字就好,无碍。在配置maven环境这块需要勾选两个复选框,再选择合适的maven路径和setting files路径,一般是在安装IntelliJ目录下的plugins中可以找到。具体如下图所示:
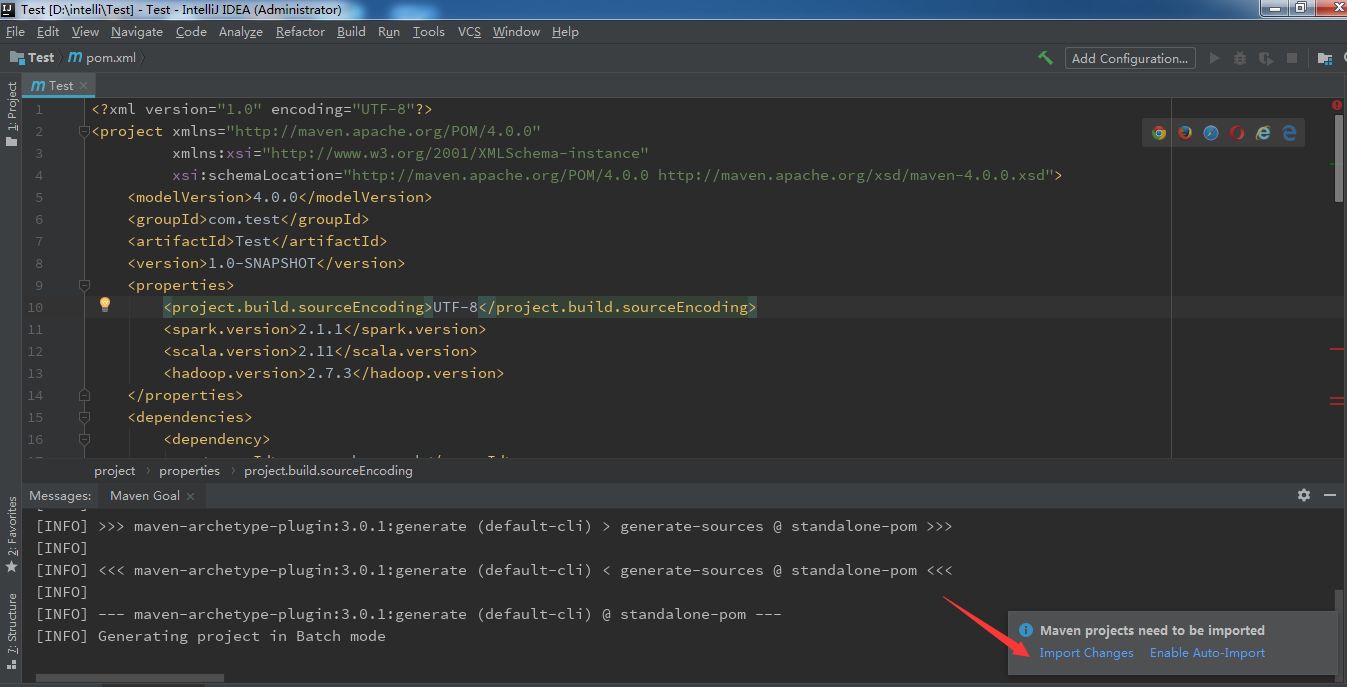
(4)配置maven项目的pom.xml文件
注意:当你配置完xml信息后,右下角这里会提示import changes,点击它,等待页面最下面Running信息加载完就可以到下一步了。否则不能及时同步xml中的配置,会导致打包失败(亲测)。配置文件信息如下,方便大家自行粘贴。我这里配置的spark版本是 2.1.1, scala版本 2.11,hadoop 版本 2.7.3,这里需要和服务器上版本一致,如果不知道服务器上spark信息,可以输入命令行 spark-shell 查看。hadoop可通过 hadoop version 查看。


<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.test</groupId> <artifactId>Test</artifactId> <version>1.0-SNAPSHOT</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <spark.version>2.1.1</spark.version> <scala.version>2.11</scala.version> <hadoop.version>2.7.3</hadoop.version> </properties> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.3</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> </build> </project>
![]()
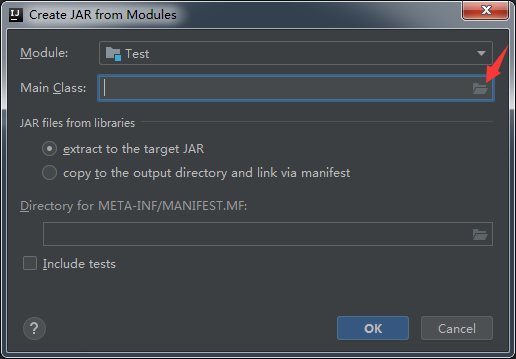
(5)在test目录下右键选择scala script新建scala类,如果没有scala script,则新建一个空白文件,名字和文件中的类名需一致,这里随意起个名字WordCount,用 .scala 作为后缀名。然后会提示没有Scala SDK,按照提示点击Setup Scala SDK安装即可。scala文件内容如下。
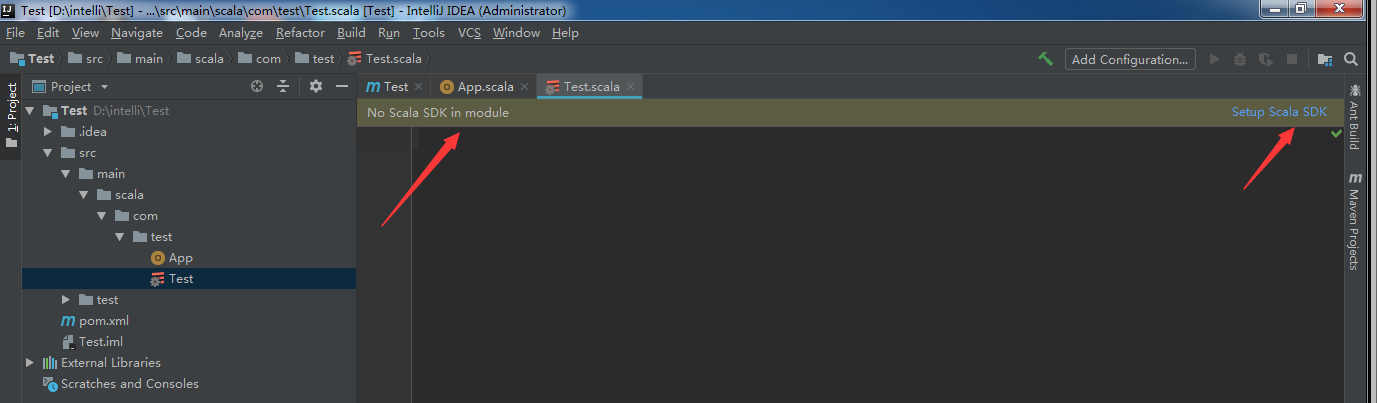
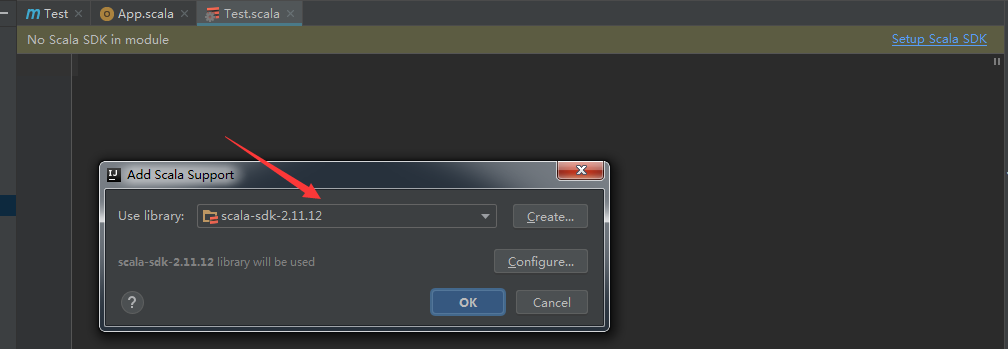
package com.test
import org.apache.spark.{SparkContext, SparkConf}
object WordCount {
def main(args: Array[String]) {
/**
* SparkContext 的初始化需要一个SparkConf对象
* SparkConf包含了Spark集群的配置的各种参数
*/
val conf = new SparkConf().setAppName("testRdd")//设置本程序名称
//.setMaster("local") 设置单线程模式
//Spark程序的编写都是从SparkContext开始的
val sc = new SparkContext(conf)
val data = sc.textFile("hdfs:///user/aisearch/user/zhengkaiyu001/graph_scala/conf/entity_params")//读取本地文件
data.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)//循环打印
}
}
这里注意下目录结构,com和test是上下级目录,这样在下面打包过程中会出现些问题,同时我会说下是怎么解决的。
(6)开始打包
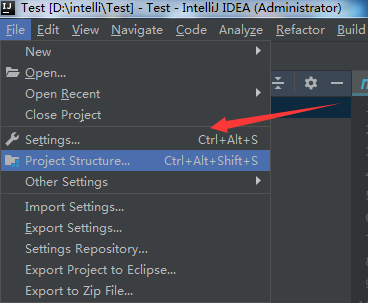
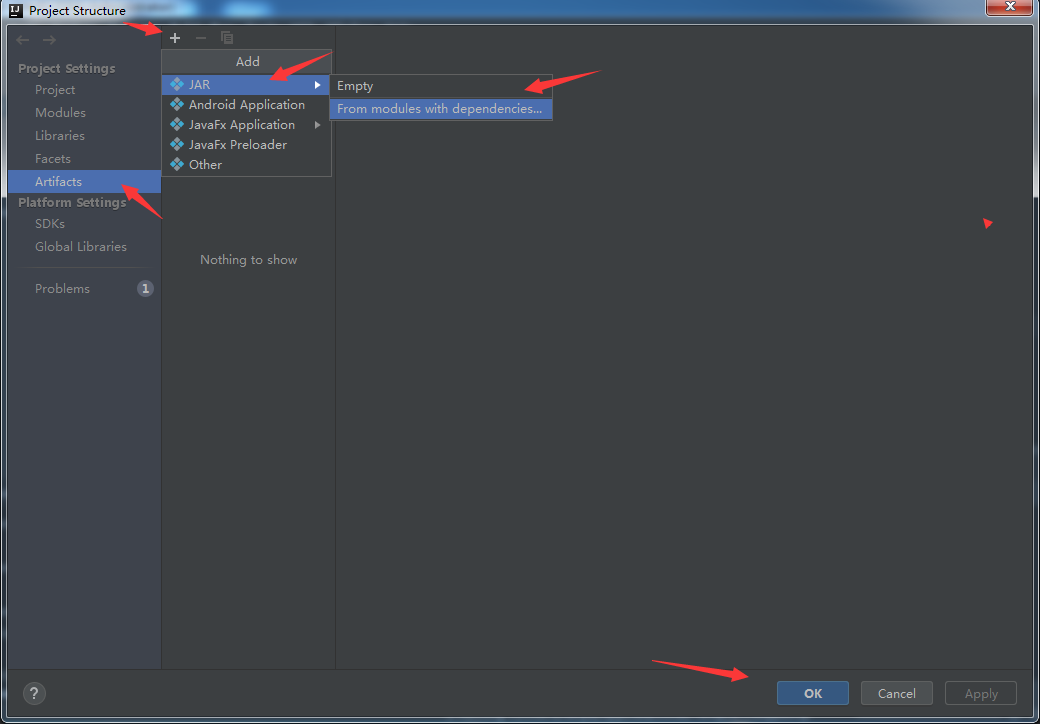
- File -> Project Structure -> Artifacts -> + -> JRE -> From modules with dependencies -> ok ,具体信息如下图所示。
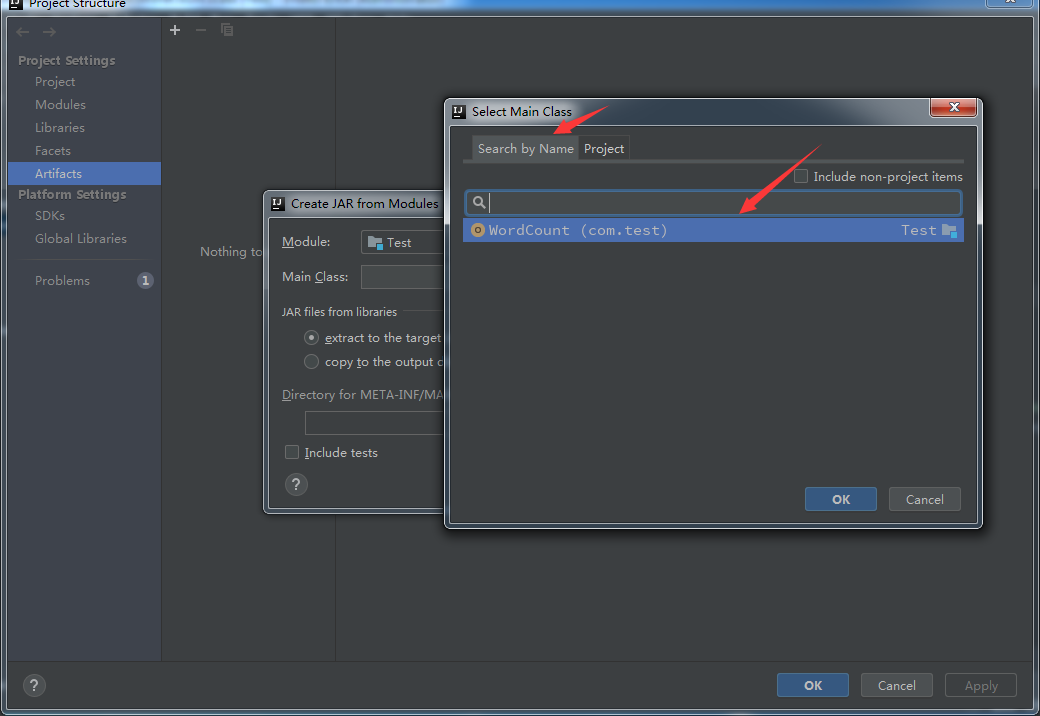
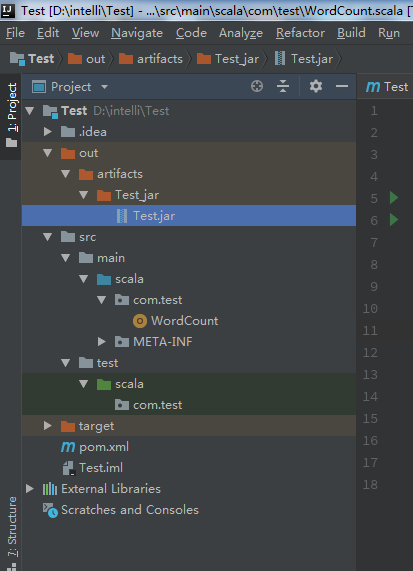
- 在通过Search by Name选择主类的时候,会自动提供出项目中是主类的可选项,但是如果上一步骤中的目录结构是上下级时,就没有自动提示信息,打包会失败。那该如何解决呢?原因其实没有根据 pom.xml 配置文件及时更新,所以打开配置文件可以选择删除一行,右下方出现 import changes 后点击,等待加载完毕后再把那行粘贴上(也可以调出maven project (file->setting->appearance->show tool windows bar)->clean 后,再选中项目右击->maven->Reimport)。这样目录就变为com.test。再重复打包过程就会有自动提示主类的信息,选择主类后点击ok。
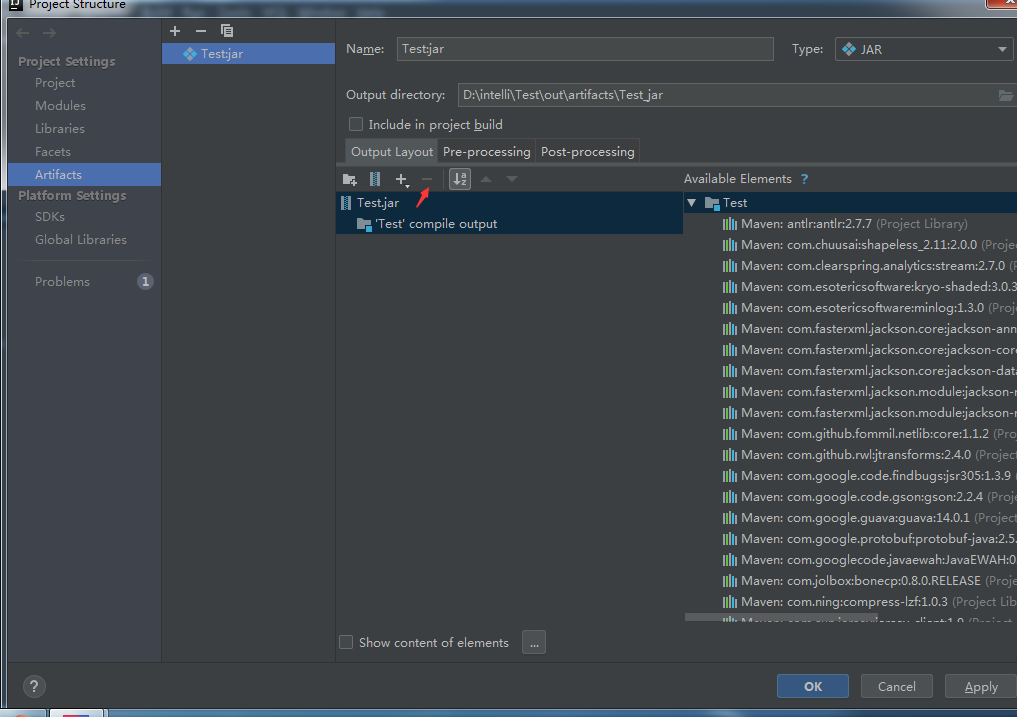
- 在进行打包设置时,只留下'Test' compile output 和Test.jar包,将其他jar包都删除,output directory是jar包的输出路径。
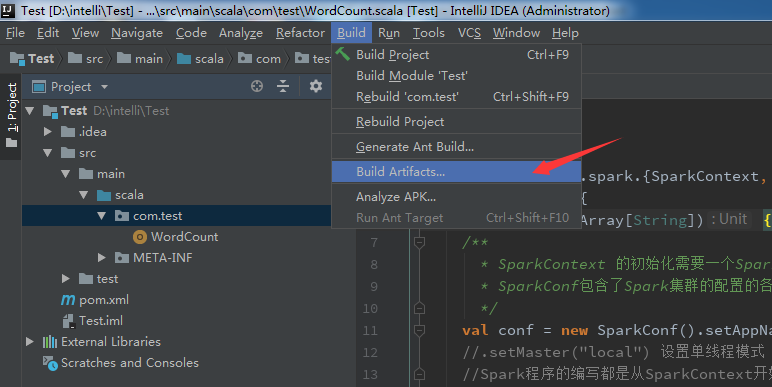
- Build:这里注意是 Build Artifacts,选择build 或者 rebuild,其实rebuild的作用是当你变动了代码,可直接rebuild重新打包,无须重新配置打包环境。
- 打包过程中会提示错误信息,把多余的文件test目录下的和main目录下的App删除即可。
,
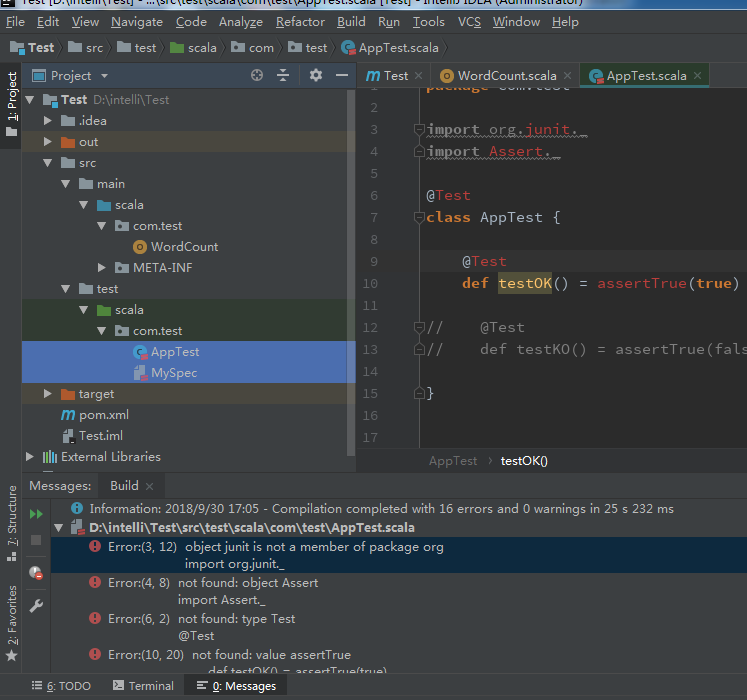
(7)运行
把输出的jar包上传至装有spark的服务器,这里我是新建了个目录,把jar包传到Jars目录下,运行命令见如下所示的脚本文件:
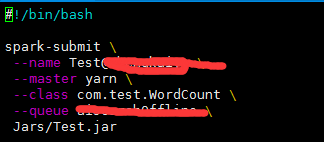
注意踩坑:
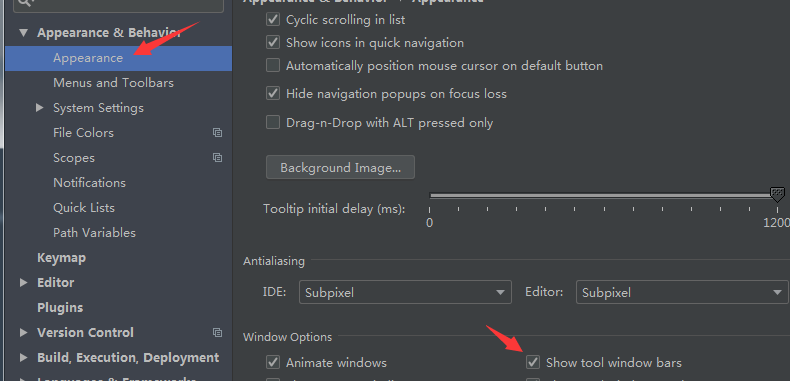
- 当配置pom.xml后一定要import changes(在打包过程中才会默认有选择的主类),如果应用没有及时import changes,你可以调出maven project (file->setting->appearance->show tool windows bar)->clean 后,再选中项目右击->maven->Reimport
- pom.xml文件中的版本号需要和服务器上的各版本一一对应
参考博客:
https://blog.csdn.net/xingyx1990/article/details/80752041

 浙公网安备 33010602011771号
浙公网安备 33010602011771号