ranger部署文档(记)
目录
概览... 2
1. ranger-admin. 2
2. ranger-user-sync. 2
3. ranger-*-plugins. 2
安装... 3
1. ranger-admin: 3
2. ranger-user-sync: 4
3. ranger-hdfs-plugin: 5
4. ranger-hive-plugin: 6
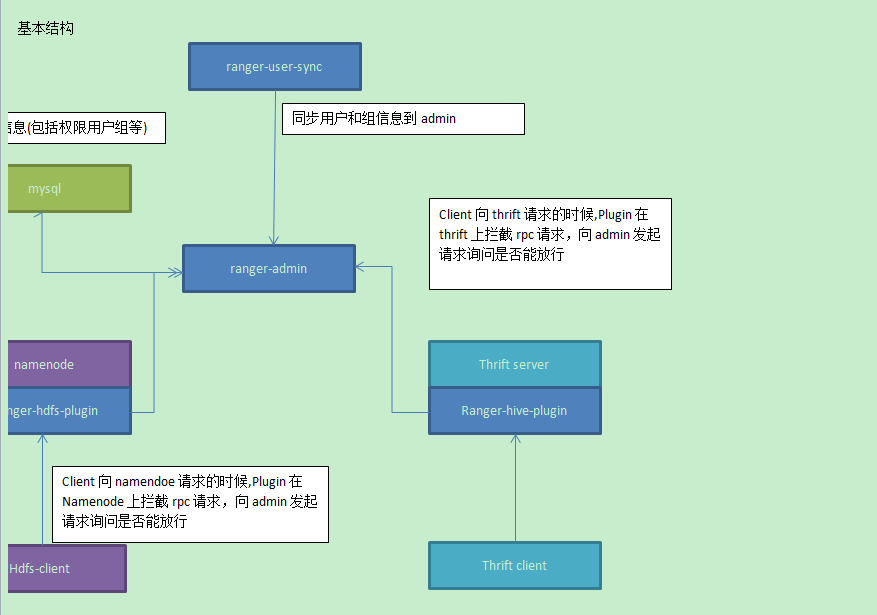
概览
1. ranger-admin
ranger的中心节点,所有鉴权访问都必须经过这个节点.
(可load balancer,请求是走HTTP协议的)
2. ranger-user-sync
同步user/group等信息到admin节点.
比如有些用户和组并不在admin节点的机器上存在的.
但在各个权限控制plugin中又有定义的,是通过这个服务同步.
3. ranger-*-plugins
各个实际的鉴权组件的hook点实现.
存在在各个服务(如HDFS)等的进程内.
安装
1. ranger-admin:
- 安装mysql,用于存放ranger的各种鉴权定义的存放等.
- 解压缩ranger-0.7.1-admin.tar.gz
- 准备solr audit(ranger会将audit log写入这个solr)
1) . cd ./contrib/solr_for_audit_setup
2) 修改install.property
# 所使用的solr的程序安装目录
SOLR_INSTALL_FOLDER=
# ranger对应的solr配置等(只需建立起空目录即可,后面自带脚本会做准备)
SOLR_RANGER_HOME=
# ranger对应的solr的数据存放位置(只需建立起空目录即可,后面自带脚本会做准备)
SOLR_RANGER_DATA_FOLDER=
# ranger audit在solr上的collection名字,默认为ranger_audits
SOLR_RANGER_COLLECTION=
3) 执行./contrib/solr_for_audit_setup/setup.sh
4) 启动(root):
${SOLR_RANGER_HOME}/scripts/start_solr.sh
停止(root):
${SOLR_RANGER_HOME}/scripts/stop_solr.sh
- 配置admin.
1) 修改install.property
# 配置所使用的mysql的root用户连接信息(需自行保证mysql这方面的权限).
db_root_user=
db_root_password=
db_host=
# ranger所使用的mysql的数据库和用户信息(后面会有自带脚本创建维护,不需手工建立)
db_name=
db_user=
db_pasword=
# 使用solr存储audit
audit_store=solr
# ranger使用的solr collection地址.
# 如果slor的设置使用默认SOLR_RANGER_COLLECTION即ranger_audit的话.
# 为http://${solr_host}:6083/solr/ranger_audits
audit_solr_urls=
# mysql JDBC的jar包路径
SQL_CONNECTOR_JAR=
2) 执行setup.sh(root)
如果执行过程中出现错误,则可以先在mysql 中建立ranger库,及其配置文件中的库对应用户及库所有权限
。
这个脚本会建立mysql上的库信息
并会放置各个脚本到标准目录(类RPM包install动作)
3) 启动(root):
ranger-admin start
停止(root):
ranger-admin stop
4) 访问:
http://${host}:6080
默认口令admin:admin
2. ranger-user-sync:
- 解压缩ranger-0.7.1-usersync.tar
- 修改install.property
# 即ranger admin的地址
# 如http://${host}:6080
POLICY_MGR_URL=
- 执行setup.sh(root)
放置各个脚本到标准目录(类RPM包install动作)
- 启动(root)
ranger-usersync start
停止(root):
ranger-usersync stop
3. ranger-hdfs-plugin:
- 在各个namenode上解压缩ranger-0.7.1-hdfs-plugin.tar.gz
- 修改install.property
# 即ranger admin的地址
# 如http://${host}:6080
POLICY_MGR_URL=
# 配置slor audit log
XAAUDIT.SOLR.ENABLE=true
# ranger使用的solr collection地址.
# 如果slor的设置使用默认SOLR_RANGER_COLLECTION即ranger_audit的话.
# 为http://${solr_host}:6083/solr/ranger_audits
XAAUDIT.SOLR.URL=
# ranger上hdfs的policy ID/名字
# 如hadoopdev
REPOSITORY_NAME=
- namenode上的调整.
1) 确保存在HADOOP_HOME环境变量
2) 确保${HADOOP_HOME}/conf存在并指向实际使用的conf目录.
3) 执行./enable-hdfs-plugin.sh(root)
copy ${HADOOP_HOME}/lib下的ranger相关jar和目录到${HADOOP_HOME}/share/hadoop/hdfs/lib
trouble shooting:
这个是保证namenode进程的classpath能找到ranger的jar包.
原理是ranger重新实现了dfs.namenode.inode.attributes.provider.class,hook了namenode上的RPC请求.
所以前面需要知道conf的目录便于重新生成hdfs-site.xml
4) 重新启动namenode和zkfc即可.
5) 验证:
hdfs mkdir等读写操作一下应该可以在admin server的web ui看到相关audit信息
4. ranger-hive-plugin:
- 在hive thrift server上解压缩ranger-0.7.1-hive-plugin.tar.gz
- 修改install.property
# 即ranger admin的地址
# 如http://${host}:6080
POLICY_MGR_URL=
# 配置slor audit log
XAAUDIT.SOLR.ENABLE=true
# ranger使用的solr collection地址.
# 如果slor的设置使用默认SOLR_RANGER_COLLECTION即ranger_audit的话.
# 为http://${solr_host}:6083/solr/ranger_audits
XAAUDIT.SOLR.URL=
# ranger上hive的policy ID/名字.如hivedev
REPOSITORY_NAME=
- 修改hive-site.xml
添加:
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
<description>
在thrift server上关闭doAS.
开启的话,一个访问需要同时控制hdfs和hive的访问权限,坏处在于不容易维护.
关闭的话,只需要维护hive的访问权限即可,坏处是所有查询在鉴权后都是以hive用户跑.
</description>
</property>
- 执行./enable-hive-plugin.sh(root)
原理类似ranger-hdfs-plugin
- 重新启动hive thrift server即可.
- 验证:
通过beeline访问thrift做查询读写应该就能在web ui看到相关audit信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号