HDFS读写数据流程
HDFS读写数据流程
标签(空格分隔): Apache Hadoop
HDFS是hadoop重要的组件之一,对其进行数据的读写是很常见的操作,然而真的了解其读写过程吗?
前言
HDFS – Hadoop Distributed File System,是hadoop的存储层,它参照google的GFS思想实现。
它以master-slave工作。NameNode作为master daemon,工作在master node上,DataNode作为slave daemon,工作在slave node上。master 之间在 HDFS 2.X.X 版本实现HA 高可用。
一,写HDFS
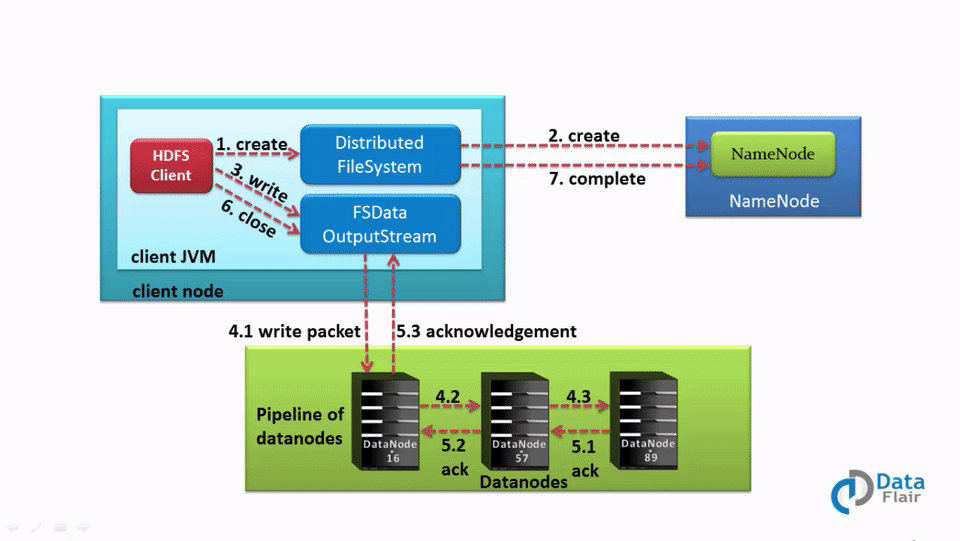
1. 流程图
2. 重要概念
HDFS一个文件由多个block构成。或者说一个文件会被切分成按照HDFS block 大小的多个块去存储。
HDFS在进行block读写的时候是以packet(默认每个packet为64K)为单位进行的。
每一个packet由若干个chunk(默认512Byte)组成。Chunk是进行数据校验的基本单位,对每一个chunk生成一个校验和(默认4Byte)并将校验和进行存储。
在写入一个block的时候,数据传输的基本单位是packet,每个packet由若干个chunk组成。
3. 过程步骤
1) HDFS client发送一个create请求给DistributedFileSystem API
2)DistributedFileSystem 使用一个RPC请求,通知NameNode在其命名空间创建一个新文件(会遇到全局锁,后续会讲到)。
此时,NameNode会进行一系列的check,如是否有权限,文件是否已经存在。 当通过check后,NameNode创建一个新的文件,状态为under construction,没有任何data block与之对应,否则,抛出一个IO异常
3)DistributedFileSystem 返回一个 FSDataOutputStream 给client,让它开始写入数据。
FSDataOutputStream的成员变量dfs类型为DFSClient,DFSClient在创建时,会构造一个DFSOutputStream。 当client开始写数据时, DFSOutputStream 会将file分割成 packets,然后把 packets都放在一个队列中,这个队列叫做data queue。 data queue会被DataStreamer消费。DataStreamer的负责就是,通过挑选一系列合适的datanode来存储副本,从而要求NameNode分配新的blocks。
4)一系列合适的datanode 表现为一个pipeline。假如此时备份级别是3,那么在pipeline中就有3个node。 DataStreamer将这些packets以流式传入pipeline中的第一个datanode。 这些packets将会存储在第一个datanode中。 然后因为第一个datanode中存放了第二个datanode的地址,所以它会在接收client传来的下一个packet时,会将自己已经收到的packet写入第二个datanode中。 以此类推,每个datanode在接收上级(client或者datanode)的写时,自己也会担负起写下级datanode的责任。 所以这样看来,packet对datanode的写,其实是并行的。
5)DFSOutputStream同时也维护了一个内部队列,叫做ack queue,它里面存放了所有要被datanodes确认的packets。 只有当一个packet被pipeline中的datanodes确认后,这个packet才会从ack queue中删除。 一旦需要的副本数量被创建,datanodes就会发送acknowledgment。
6)当client结束了写数据,它会在流上调用一个close()。
7) 这个close的动作,会flush所有剩余的packets到datanodes pipeline中,然后等待datanodes的acknowledgments,最后给namenode发信号说文件已完成。 namenode已经知道了文件是由哪些block组成的,所以在返回成功之前,它只需要等待那些块被最小的备份就可以了。
4. 容错过程
这部分 是大部分人比较忽视的。
当在向 datanode 写入数据失败时,将执行以下操作,这些操作对于写入数据的客户端是透明的。
首先,关闭管道,并将ack队列中的任何数据包添加到数据队列的前面,以便故障节点下游的数据节点不会丢失任何数据包。
当前块的 datanode 如果是良好的话,这个块会被赋予一个新的标识,该标识被传送到 namenode,以便如果稍后恢复失败的 datanode 时,可以将失败的 datanode 上的失败块删除。
datanode 失败的话,它将从管道中删除,然后块的其余数据将写入管道中的两个良好数据节点。
namenode 注意到该块未被复制,并且它安排在另一个节点上创建另一个副本,然后它将后续块视为正常。
客户端写入块时,多个数据节点失败是可能的, 只要它写入dfs.replication.min(默认为1),写入就会成功,并且该块将在群集中异步复制,直到达到目标复制因子(dfs.replication,默认为3)。异步复制线程会在namenode 5min 启动一次。将需要复制的块添加到复制队列。
二,读HDFS
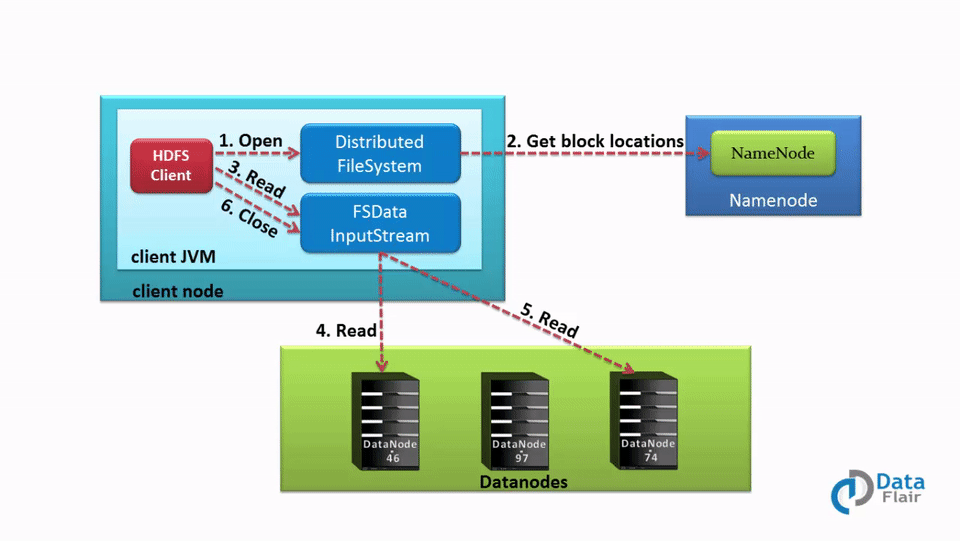
1. 流程图
2. 过程步骤
1) client 读取目标文件,是通过一个FileSystem对象的open()方法。这个FileSystem对象,对HDFS来讲,就是一个DistributedFileSystem。
2)DistributedFileSystem 使用一个RPC请求,询问NameNode文件前几个block的位置。
对于每个block,namenode会根据就近原则,返回那些离client较近(根据friendly 去计算块的距离远近),而且也存储了该block的datanode地址。
3)DistributedFileSystem 返回一个 FSDataInputStream给client,让client通过它来读取文件。
FSDataOutputStream包裹了一个DFSInputStream。DFSInputStream会来管理与datanode和namenode的I/O。 client在流上调用read()。已经存储了datanode地址的DFSInputStream,接着就会连接存储文件第一个block的、且距离最近的datanode。
4)数据会以流式传回client,因此client可以在流上重复调用read。 当这个block结束后,DFSInputStream会关闭和datanode的连接,然后找到对下个block而言最好的datanode。
5)如果DFSInputStream在和datanode交流时,发生了错误,它就会尝试下一个离它最近的datanode。 DFSInputStream会记下那些失败的datanodes,以免之后的block们对它们不必要的请求。 DFSInputStream同时会对从datanode传回的数据进行验证。如果它发现了损坏的block,它想namenode报告这个情况,然后再去请求词block的下一个备份的datanode。
6)当client结束了读数据,它会在流上调用一个close()。
参考链接
Hadoop HDFS Data Read and Write Operations: https://data-flair.training/blogs/hadoop-hdfs-data-read-and-write-operations/
HDFS读写文件流程: https://blog.csdn.net/qq_20641565/article/details/53328279
HDFS dfsclient写文件过程 源码分析: http://www.cnblogs.com/ggjucheng/archive/2013/02/19/2917020.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号