
python代码利用梯度下降法实现简单的线性回归
本案例演示梯度下降如何求线性方程的解。
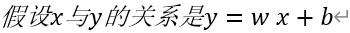
求出w和b值,即找到了x与y的关系,即能通过x预测y值。
思路:
第1步:生成训练数据x,y_true。
训练数据x为一组按正态分布随机的数据
训练数据y,按y_true=0.7x+0.8 (假设实际w值=0.7,b=0.8)
第2步:定义预测的权重w,偏置b值和预测值y_predict。
因为权重w和偏置b值在算法训练过程中是不断变化的,故在定义其tensor时,要指令是随机变量的范围. weight是一组按正态分布随机(一维一行[1,1])的随机变量。Bias是一组变更,其初始值=0.0,将根据训练过程不断自动累加。
weight=tf.Variable(tf.compat.v1.random_normal([1,1],mean=0.0,stddev=1.0,name='w'))
bias=tf.Variable(0.0,name='b')
第3点: 建立损失函数,损失函数样本与实际值的减值平方,即均方误差。(第2点预测值-实际值)
loss=tf.math.reduce_mean(tf.math.square(y_true-y_predict))
第4点:利于“均方误差最小值”的梯度下降训练
train_op=tf.compat.v1.train.GradientDescentOptimizer(learning_rate=0.1).minimize(loss)
第5点:运行第4点生成的训练张量,并得到训练后的权重和偏置值.这里循环的次数代表训练的次数
for i in range(100):
sess.run(train_op)
print('参数权重为:%f,偏置为%f' % (weight.eval(), bias.eval()))
具体代码如下 :
1 def myregression(): 2 #由于在tensofflow2.0以上的版本,eager execution 是默认开启的。如果不加此语句,直接运行程序将会报错 3 tf.compat.v1.disable_eager_execution() 4 ''' 5 自实现一个线性回归预测 6 :return: 7 ''' 8 #1.准备数据,x特征值[100,1],y目标值[100] 9 x=tf.compat.v1.random_normal([100,1],mean=1.75,stddev=0.5,name='x_data') 10 #假设y的真实值为y=0.7x+0.8,a的值随机给为0.7,b偏置的值随机给0.8 11 #矩阵相系必须是二维的,故[[0.7]] y_true为训练集数据 12 y_true=tf.matmul(x,[[0.7]])+0.8 13 14 #第二步:建立线性回归模型。确认了只有一个特征,故只有一个权重,一个偏置 y= w x+b 15 #随机给一个权重和偏置的值,让他去计算损失,然后当前状态下优化 16 #因为权重训练的过程中,不断变化,故初始化用的是variable.mean和stddev随机给为0.0,1.0 17 weight=tf.Variable(tf.compat.v1.random_normal([1,1],mean=0.0,stddev=1.0,name='w')) 18 #偏置初始值为0.0,后面下降时不断+1 19 bias=tf.Variable(0.0,name='b') 20 #预测的结果=x * weight +bias 21 y_predict=tf.matmul(x,weight)+bias 22 23 #3、建立损失波函数,均方误差.--先求每个样本的误差的平方,然后将误差平方进行求和之后求平均值。 即全部相减求平方之后再相加的总数再除以样本数 24 #最后返回其损失 25 loss=tf.math.reduce_mean(tf.math.square(y_true-y_predict)) 26 27 #4、梯度下降优化损失 learning_rate随机指定.最小化损失.返回op 28 train_op=tf.compat.v1.train.GradientDescentOptimizer(learning_rate=0.1).minimize(loss) 29 30 #定义一个初始化变量的op 31 init_op=tf.compat.v1.global_variables_initializer() 32 #通过会话运行程序 33 with tf.compat.v1.Session() as sess: 34 #初始化变量 35 sess.run(init_op) 36 #打印随机最先初始化的权重和偏置 37 print('随机初始化的参数权重为:%f,偏置为%f'%(weight.eval(),bias.eval()))#因为weigth和bias都为op,不能直接调出数值 38 39 #运行优化,由于不是一次性能优化,故要循环,假设训练100次 40 #循环1000次后,发现已经靠近w--0.7,b==0.8 41 for i in range(1010): 42 sess.run(train_op) 43 print('参数权重为:%f,偏置为%f' % (weight.eval(), bias.eval())) # 因为weigth和bias都为op,不能直接调出数值 44 return None

 浙公网安备 33010602011771号
浙公网安备 33010602011771号