

01.机器学习概述、特征工程、学习算法
机器学习是从数据中自动分析获是规律(模型),并利用规律对未知数据进行预测。
利用好现成的框架技术。
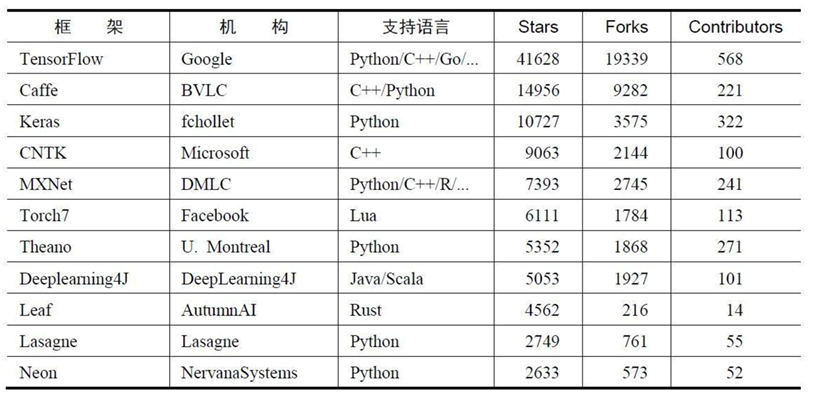
常使用TensorFlow框架
推荐阅读以下书籍。



机器学习
首先最基础的要有”数据“。
数据类型
离散型数据:由记录不同类别个体的数目所得到的数据,又称计数据,所有这些数据全部都是整数,且不可再细分,也不能进一步提高他们的精确度。
连续型数据:变量可以在某个范围内取任一数,即变量的取值可以是连续的,比如:长度,时间,质量值等,这类数据通常是非整数,含有小数部分。只要记住一点,离散型区间内不可分,连续型是区间内可分。数据的类型是机器学习模型不同问题不同处理的依据,是重点。

Kaggle网址:https://www.kaggle.com/datasets
UCI数据集网址: http://archive.ics.uci.edu/ml/
scikit-learn网址:http://scikit-learn.org/stable/datasets/index.html#datasets
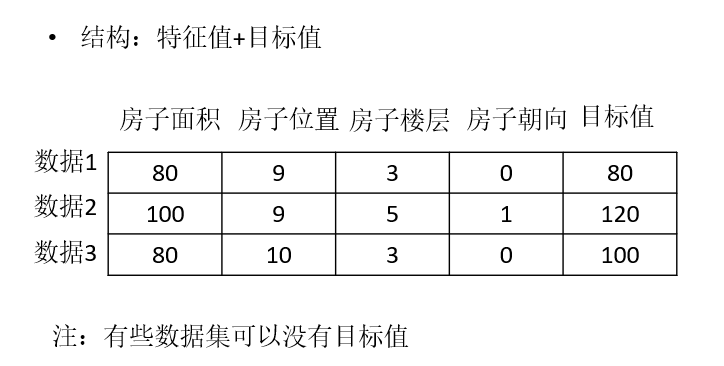
常用数据集数据的结构组成
特征工程
特征工程是将原始数据转换成更好代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的模型准确性。
举例说明特征工程的重要性。从网站PK某个学习算法时,不同团队得分有所差距。在相同的算法、计算能力情况下,其分值差距通常由不同的”特征工程”处理导致的。故特征处理是极为重要。它将直接影响到算法的准确性。
特征的抽取
1、对字典数据进行特征化---sklearn.feature_extraction.DictVectorizer。为每个类别生成一个布尔列,这些列中只有一列可以为每个样本取值1。术语称之为one-hot编码。
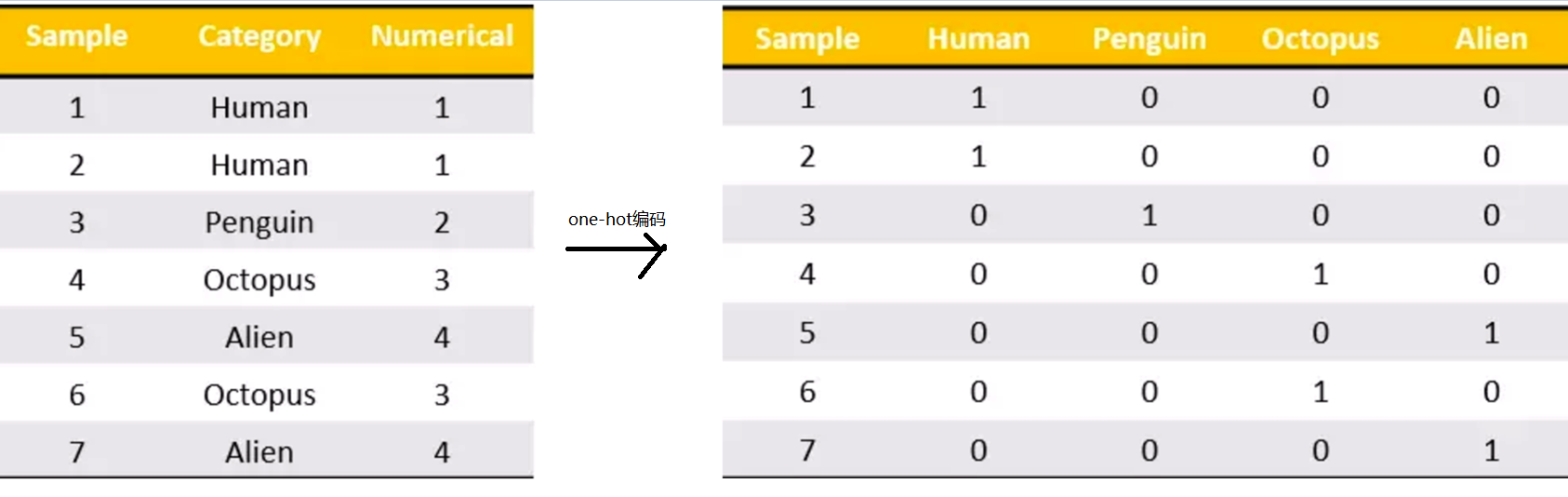
2、文本特征抽取--sklearn.feature.extraction.text.CountVectorizer.返回词频矩阵。只是单纯的词语出现的次数。其缺点是对于常用的词语,比如:我们,他,她等之类的词语会干扰判断。
故引出另一种文本特征抽取的办法TF-IDF。
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。sklearn.feature.extraction.text.TfidfVectorizer

特征处理
通过特定的统计方法(数学方法)将数据转换成算法要求的数据。
上面的特征抽取将各特征值转换了数据,但这些数据并不能直接为“算法”所要求,故需要对特征数据进行预处理。
常见的预处理方法:1、归一化 2、标准化 3、缺失值 类别型数据one-hot编码 时间类型:时间的切分
归一化
通过对原始数据进行变换把数据映射到(默认为[0,1])之间---sklearn.preprocessing.MinMaxScaler
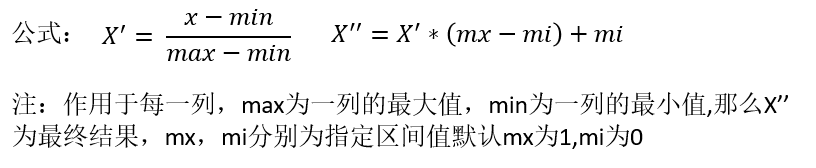
如果样本数据中的异常数据较多,归一化方法处理的特征数据,将会导致算法不准确现象。故通常此方法不常使用。仅适合传统精确小数据场景。
标准化
为了避免异常数据问题,提出了标准化方法。即通过对原始数据进行变换,把数据变换到均值为0,方差为1范围内。--sklearn.preprocessing.StandardScaler

方差可以通俗的理解为每个样本离均值的差距的平均值。假设,方差等于零,则意味着每个样本值都等于平均值 ,即所有的样本固定在一个点了。这样的样本数据是一样的,在特征选择时,该样本没有算法意义。


适合在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号