13.Pandas分层索引Multiindex
同样以股票数据为例
Series单层索引
ser=stocks.grougby('公司').['收盘'].mean()
返回以公司为维度作为索引的平均值。(ser值的含义:A公司的股票收盘平均值,B公司的股票收盘平均值,...X公司的股票收盘平均值)
Series的分层索引Mulitindex
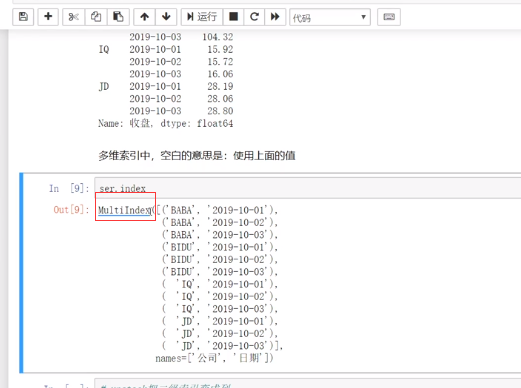
ser=stocks.groupby(['公司','日期'])['收盘'].mean()。注意这里传入的是一个列表['公司','日期']。(ser值的含义:A公司的在某个日期其股票收盘平均值,B公司的在某个日期其股票收盘平均值,。..X公司的在某个日期其股票收盘平均值),加上了日期维度。
此时执行ser.index,则返回的类型为MuliIndex
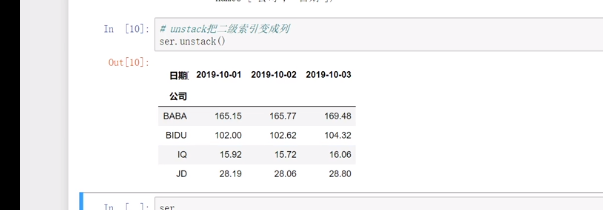
将二级索引变成列
ser.unstack()
执行ser

再执行ser.re_index()

如果Series有多层索引MultiIndex怎样筛选数据?
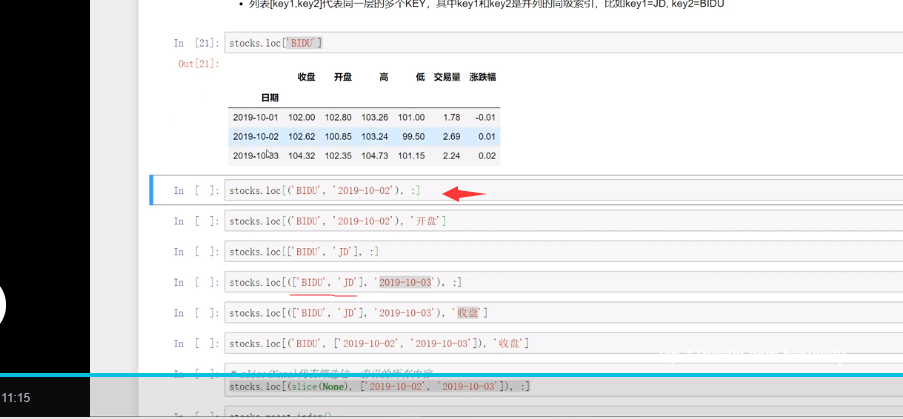
ser.loc['BIDU']
ser.loc[('BIDU','2019-10-12')],传入元组的形式筛选,多层索引。
即跨列,用元组显示传入;不跨列,仅跨行,则列表的显示传入。