


Java常用数据结构
1、数组
数组(Array) 是一种很常见的数据结构。它由相同类型的元素(element)组成,并且是使用一块连续的内存来存储。
我们直接可以利用元素的索引(index)可以计算出该元素对应的存储地址。
特点:长度固定,不支持动态扩容。可以随机访问元素。
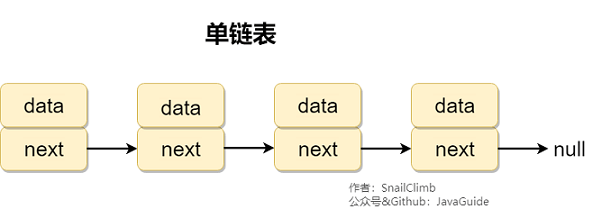
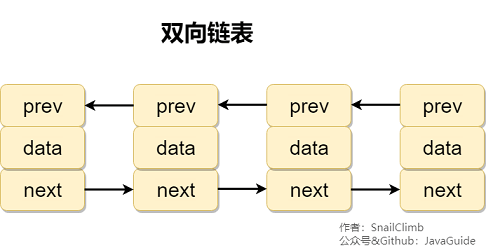
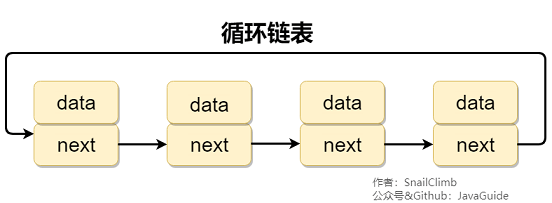
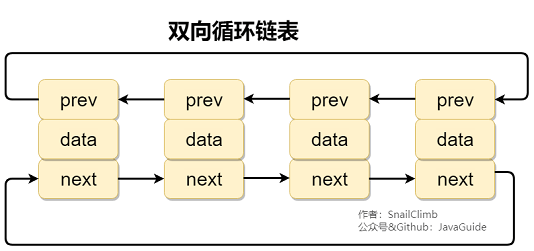
2、链表
虽然是一种线性表,但是并不会按线性的顺序存储数据,使用的不是连续的内存空间来存储数据。
链表的插入和删除操作的复杂度为 O(1) ,只需要知道目标位置元素的上一个元素即可。但是,在查找一个节点或者访问特定位置的节点的时间复杂度为 O(n) 。
特点:长度不固定,插入和删除比较简单,只需要知道目标位置的上一个原色即可。查找复杂。使用链表结构可以克服数组需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但链表不会节省空间,相比于数组会占用更多的空间,因为链表中每个节点存放的还有指向其他节点的指针。除此之外,链表不具有数组随机读取的优点。
3、数组和链表比较
数组长度固定且支持随机访问元素,链表长度不固定不支持随机访问。
如果需要的元素数量固定,且不需要经常的插入和删除,数组适合。
如果需要的元素数量不固定,且需要经常插入和删除链表更合适。
数组开辟连续的空间,链表不是开辟的连续空间。
4、栈
栈 (stack)只允许在有序的线性数据集合的一端(称为栈顶 top)进行加入数据(push)和移除数据(pop)。因而按照 后进先出(LIFO, Last In First Out) 的原理运作。在栈中,push 和 pop 的操作都发生在栈顶。
栈常用一维数组或链表来实现,用数组实现的栈叫作 顺序栈 ,用链表实现的栈叫作 链式栈 。
5、队列
队列 是 先进先出( FIFO,First In, First Out) 的线性表。在具体应用中通常用链表或者数组来实现,用数组实现的队列叫作 顺序队列 ,用链表实现的队列叫作 链式队列 。队列只允许在后端(rear)进行插入操作也就是 入队 enqueue,在前端(front)进行删除操作也就是出队 dequeue
队列的操作方式和堆栈类似,唯一的区别在于队列只允许新数据在后端进行添加。
树就是一种类似现实生活中的树的数据结构(倒置的树)。任何一颗非空树只有一个根节点。
一棵树具有以下特点:
- 一棵树中的任意两个结点有且仅有唯一的一条路径连通。
- 一棵树如果有 n 个结点,那么它一定恰好有 n-1 条边。
- 一棵树不包含回路。
- 节点 :树中的每个元素都可以统称为节点。
- 根节点 :顶层节点或者说没有父节点的节点。上图中 A 节点就是根节点。
- 父节点 :若一个节点含有子节点,则这个节点称为其子节点的父节点。上图中的 B 节点是 D 节点、E 节点的父节点。
- 子节点 :一个节点含有的子树的根节点称为该节点的子节点。上图中 D 节点、E 节点是 B 节点的子节点。
- 兄弟节点 :具有相同父节点的节点互称为兄弟节点。上图中 D 节点、E 节点的共同父节点是 B 节点,故 D 和 E 为兄弟节点。
- 叶子节点 :没有子节点的节点。上图中的 D、F、H、I 都是叶子节点。
- 节点的高度 :该节点到叶子节点的最长路径所包含的边数。
- 节点的深度 :根节点到该节点的路径所包含的边数
- 节点的层数 :节点的深度+1。
- 树的高度 :根节点的高度。
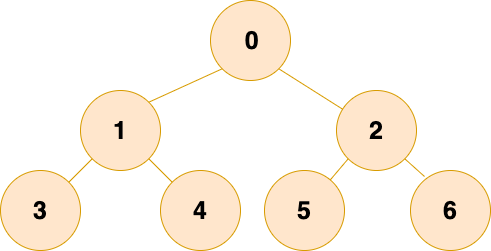
完全二叉树:除最后一层外,若其余层都是满的,并且最后一层或者是满的,或者是在右边缺少连续若干节点,则这个二叉树就是 完全二叉树 。
平衡二叉树:是一棵二叉排序树,且具有以下性质:
- 可以是一棵空树
- 如果不是空树,它的左右两个子树的高度差的绝对值不超过 1,并且左右两个子树都是一棵平衡二叉树。
二叉树的遍历
先序遍历:二叉树的先序遍历,就是先输出根结点,再遍历左子树,最后遍历右子树,遍历左子树和右子树的时候,同样遵循先序遍历的规则,也就是说,我们可以递归实现先序遍历。
中序遍历:二叉树的中序遍历,就是先递归中序遍历左子树,再输出根结点的值,再递归中序遍历右子树,大家可以想象成一巴掌把树压扁,父结点被拍到了左子节点和右子节点的中间,如下图所示:
后序遍历:二叉树的后序遍历,就是先递归后序遍历左子树,再递归后序遍历右子树,最后输出根结点的值。
7、红黑树
- 每个节点非红即黑;
- 根节点总是黑色的;
- 每个叶子节点都是黑色的空节点(NIL节点);
- 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
- 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)