学习《c++_primer》之第六章
6.1 节练习
练习 6.1
形参出现在函数定义的地方,形参列表可以包含 0 个、1 个或多个形参,多个形参之间以逗号分隔。形参规定了一个函数所接受数据的类型和数量。
实参出现在函数调用的地方,实参的数量与形参一样多。实参的主要作用是初
始化形参,并且这种初始化过程是一一对应的,即第一个实参初始化第一个形参、第二个实参初始化第二个形参,以此类推。实参的类型必须与对应的形参类型匹配。
练习 6.2
首先,函数的三要素(函数名、返回值、参数)必不可少;其次,函数的主体内容必须放在一对花括号内;最后,函数体内返回的结果必须与函数的返回值类型相同。
(a)是错误的,因为函数体返回的结果类型是 string,而函数的返回值类型是int,二者不一致且不能自动转换。
修改后的程序是:
string f() {
string s;
// . . .
return s;
}
(b)是错误的,因为函数缺少返回值类型。如果该函数确实不需要返回任何值,则程序应该修改为:
void f2(int i) { /* . . . */ }
(c)是错误的,同一个函数如果含有多个形参,则这些形参的名字不能重复;另外,函数体左侧的花括号丢失了。
修改后的程序应该是:
int calc(int v1, int v2) {/* . . . */ }
(d)是错误的,因为函数体必须放在一对花括号内。修改后的程序是:
double square(double x) {return x * x;}
练习 6.3
int fact(int val)
{
if (val < 0)
return -1;
int ret = 1;
// 从 1 连乘到 val
for (int i = 1; i != val + 1; ++i)
ret *= i;
return ret;
}
练习 6.4
#include <iostream>
using namespace std;
int fact(int val)
{
if (val < 0)
return -1;
int ret = 1;
// 从 1 连乘到 val
for (int i = 1; i != val + 1; ++i)
ret *= i;
return ret;
}
int main()
{
int num;
cout << "请输入一个整数:";
cin >> num;
cout << num << "的阶乘是:" << fact(num) << endl;
return 0;
}
输出如下:

练习 6.5
根据参数类型的不同,我们可以分别求整数的绝对值和浮点数的绝对值。因为
本题主要考查的知识点是编写和使用函数,因此参数的类型不是关键。从通用性的角度出发,我们不妨设定参数类型是双精度浮点数 double。
#include <iostream>
#include <cmath>
using namespace std;
// 第一个函数通过 if-else 语句计算绝对值
double myABS(double val)
{
if (val < 0)
return val * -1;
else
return val;
}
// 第二个函数调用 cmath 头文件的 abs 函数计算绝对值
double myABS2(double val)
{
return abs(val);
}
int main()
{
double num;
cout << "请输入一个数:";
cin >> num;
cout << num << "的绝对值是:" << myABS(num) << endl;
cout << num << "的绝对值是:" << myABS2(num) << endl;
return 0;
}
输出如下:

练习 6.6
形参和定义在函数体内部的变量统称为局部变量,它们对函数而言是局部的,
仅在函数的作用域内可见。
函数体内的局部变量又分为普通局部变量和静态局部变量,对于形参和普通局部变量来说,当函数的控制路径经过变量定义语句时创建该对象,当到达定义所在的块末尾时销毁它。
我们把只存在于块执行期间的对象称为自动对象。
这几个概念的区别是:
-
形参是一种自动对象,函数开始时为形参申请内存空间,我们用调用函数时提供的实参初始化形参对应的自动对象。
-
普通变量对应的自动对象也容易理解,我们在定义该变量的语句处创建自动对象,如果定义语句提供了初始值,则用该值初始化;否则,执行默认初始
化。当该变量所在的块结束后,变量失效。 -
局部静态变量比较特殊,它的生命周期贯穿函数调用及之后的时间。局部静态变量对应的对象称为局部静态对象,它的生命周期从定义语句处开始,直到程序结束才终止。
下面的程序同时使用了形参、普通局部变量和静态局部变量:
#include <iostream>
using namespace std;
// 该函数同时使用了形参、普通局部变量和静态局部变量
double myADD(double val1, double val2) // val1 和 val2 是形参
{
double result = val1 + val2; // result 是普通局部变量
static unsigned iCnt = 0; // iCnt 是静态局部变量
++iCnt;
cout << "该函数已经累计执行了" << iCnt << "次" << endl;
return result;
}
int main()
{
double num1, num2;
cout << "请输入两个数:";
while (cin >> num1 >> num2)
{
cout << num1 << "与" << num2 << "的求和结果是:"
<< myADD(num1, num2) << endl;
}
return 0;
}
输出如下:

练习 6.7
#include <iostream>
using namespace std;
// 该函数仅用于统计执行的次数
unsigned myCnt() // 完成该函数的任务不需要任何参数
{
static unsigned iCnt = -1; // iCnt 是静态局部变量
++iCnt;
return iCnt;
}
int main()
{
cout << "请输入任意字符后按回车键继续" << endl;
char ch;
while (cin >> ch)
{
cout << "函数 myCnt()的执行次数是:" << myCnt() << endl;
}
return 0;
}
输出如下:

练习 6.8
#ifndef CHAPTER6_H_INCLUDED
#define CHAPTER6_H_INCLUDED
int fact(int);
double myABS(double);
double myABS2(double);
#endif // CHAPTER6_H_INCLUDED
附上书上一段话:

练习 6.9
fact.cpp
#include "Chapter6.h"
using namespace std;
int fact(int val)
{
if (val < 0)
return -1;
int ret = 1;
for (int i = 1; i != val + 1; ++i)
ret *= i;
return ret;
}
factMain.cpp
#include <iostream>
#include "Chapter6.h"
using namespace std;
int main()
{
int num;
cout << "请输入一个整数:";
cin >> num;
cout << num << "的阶乘是:" << fact(num) << endl;
return 0;
}
输出如下:

6.2 节练习
练习 6.10
使用指针作为参数时,在函数内部交换指针的值只改变局部变量,不会影响实
参原本的值,无法满足题目要求。我们应该在函数内部通过解引用操作改变指针所指的内容。
#include <iostream>
using namespace std;
// 在函数体内部通过解引用操作改变指针所指的内容
void mySWAP(int *p, int *q)
{
int tmp = *p; // tmp 是一个整数
*p = *q;
*q = tmp;
}
int main()
{
int a = 5, b = 10;
int *r = &a, *s = &b;
cout << "交换前:a = " << a << ",b = " << b << endl;
mySWAP(r, s);
cout << "交换后:a = " << a << ",b = " << b << endl;
return 0;
}
输出如下:

请特别注意,下面这个程序无法满足题目的要求:
#include <iostream>
using namespace std;
// 在函数体内部交换了两个形参指针本身的值,未能影响实参
void mySWAP(int* p, int* q)
{
int* tmp = p; // tmp 是一个指针
p = q;
q = tmp;
}
int main()
{
int a = 5, b = 10;
int *r = &a, *s = &b;
cout << "交换前:a = " << a << ",b = " << b << endl;
mySWAP(r, s);
cout << "交换后:a = " << a << ",b = " << b << endl;
return 0;
}
练习 6.11
#include <iostream>
using namespace std;
void reset(int& i)
{
i = 0;
}
int main()
{
int num = 10;
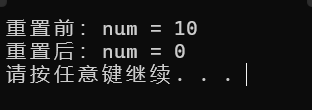
cout << "重置前:num = " << num << endl;
reset(num);
cout << "重置后:num = " << num << endl;
return 0;
}
输出如下:
练习 6.12
#include <iostream>
using namespace std;
void mySWAP(int& i, int& j)
{
int tmp = i;
i = j;
j = tmp;
}
int main()
{
int a = 5, b = 10;
cout << "交换前:a = " << a << ",b = " << b << endl;
mySWAP(a, b);
cout << "交换后:a = " << a << ",b = " << b << endl;
return 0;
}
输出如下:

与使用指针相比,使用引用交换变量的内容从形式上看更简单一些,并且无须额外声明指针变量,也避免了拷贝指针的值。
练习 6.13
void f(T)的形参采用的是传值方式,也就是说,实参的值被拷贝给形参,形参和实参是两个相互独立的变量,在函数 f 内部对形参所做的任何改动都不会影响实参的值。
void f(T&)的形参采用的是传引用方式,此时形参是对应的实参的别名,形参绑定到初始化它的对象。如果我们改变了形参的值,也就是改变了对应实参的值。
下面这个程序可以说明两个函数声明的区别:
#include <iostream>
using namespace std;
void a(int); // 传值参数
void b(int&); // 传引用参数
int main()
{
int s = 0, t = 10;
a(s);
cout << s << endl;
b(t);
cout << t << endl;
return 0;
}
void a(int i)
{
++i;
cout << i << endl;
}
void b(int& j)
{
++j;
cout << j << endl;
}
输出如下:

练习 6.14
与值传递相比,引用传递的优势主要体现在三个方面:
一是可以直接操作引用形参所引的对象;
二是使用引用形参可以避免拷贝大的类类型对象或容器类型对象;
三是使用引用形参可以帮助我们从函数中返回多个值。
基于对引用传递优势的分析,我们可以举出几个适合使用引用类型形参的例子:
第一,当函数的目的是交换两个参数的内容时应该使用引用类型的形参;
第二,当参数是 string 对象时,为了避免拷贝很长的字符串,应该使用引用类型。
在其他情况下可以使用值传递的方式,而无须使用引用传递,例如求整数的绝
对值或者阶乘的程序。
练习 6.15
find_char 函数的三个参数的类型设定与该函数的处理逻辑密切相关,原因分别如下:
-
对于待查找的字符串 s 来说,为了避免拷贝长字符串,使用引用类型;同时我们只执行查找操作,无须改变字符串的内容,所以将其声明为常量引用。
-
对于待查找的字符 c 来说,它的类型是 char,只占 1 字节,拷贝的代价很低,而且我们无须操作实参在内存中实际存储的内容,只把它的值拷贝给形参即可,所以不需要使用引用类型。
-
对于字符出现的次数 occurs 来说,因为需要把函数内对实参值的更改反映在函数外部,所以必须将其定义成引用类型;但是不能把它定义成常量引用,
练习 6.16
本题的程序把参数类型设为非常量引用,这样做有几个缺陷:一是容易给使用
者一种误导,即程序允许修改变量 s 的内容;二是限制了该函数所能接受的实参类型,我们无法把 const 对象、字面值常量或者需要进行类型转换的对象传递给普通的引用形参。
根据上述分析,该函数应该修改为:
bool is_empty(const string& s) { return s.empty(); }
练习 6.17
第一个函数的任务是判断 string 对象中是否含有大写字母,无须修改参数的内容,因此将其设为常量引用类型。
第二个函数需要修改参数的内容,所以应该将其设定为非常量引用类型。
#include <iostream>
#include <string>
using namespace std;
bool HasUpper(const string& str) // 判断字符串是否含有大写字母
{
for (auto c : str)
if (isupper(c))
return true;
return false;
}
void ChangeToLower(string& str) // 把字符串中的所有大写字母转成小写
{
for (auto& c : str)
c = tolower(c);
}
int main()
{
cout << "请输入一个字符串:" << endl;
string str;
cin >> str;
if (HasUpper(str))
{
ChangeToLower(str);
cout << "转换后的字符串是:" << str << endl;
}
else
cout << "该字符串不含大写字母,无须转换" << endl;
return 0;
}
输出如下:

练习 6.18
(a)的函数声明是:
bool compare( const matrix&, const matrix& )
(b)的函数声明是:
vector<int>::iterator change_val( int, vector<int>::iterator )
练习 6.19
(a)是非法的,函数的声明只包含一个参数,而函数的调用提供了两个参数,因此无法编译通过。
(b)是合法的,字面值常量可以作为常量引用形参的值,字符'a'作为 char 类型形参的值也是可以的。
(c)是合法的,66 虽然是 int 类型,但是在调用函数时自动转换为 double 类型。
(d) 是合法的, vec.begin() 和 vec.end() 的类型都是形参所需的
vector<int>::iterator,第三个实参 3.8 可以自动转换为形参所需的 int 类型。
练习 6.20
当函数对参数所做的操作不同时,应该选择适当的参数类型。
如果需要修改参数的内容,则将其设置为普通引用类型;否则,如果不需要对参数内容做任何更改,最好设为常量引用类型。
就像前面几个练习题展示的那样,如果把一个本来应该是常量引用的形参设成
了普通引用类型,有可能遇到几个问题:一是容易给使用者一种误导,即程序允许修改实参的内容;二是限制了该函数所能接受的实参类型,无法把 const 对象、字面值常量或者需要类型转换的对象传递给普通的引用形参。
附上书上原话:

练习 6.21
第一个参数的实际值毫无疑问是 int 类型,第二个参数是 int 指针,实际上有可能表示的是一个 int 数组,该指针指向了数组的首元素。
通过分析题意我们知道,函数实际上比较的是第一个实参的值和第二个实参所
指数组首元素的值。因为两个参数的内容都不会被修改,所以指针的类型应该是const int*。
#include <iostream>
#include <string>
#include <ctime>
#include <cstdlib>
using namespace std;
int myCompare(const int val, const int* p)
{
return (val > *p) ? val : *p;
}
int main()
{
srand((unsigned)time(NULL));
int a[10];
for (auto& i : a)
i = rand() % 100;
cout << "请输入一个数:";
int j;
cin >> j;
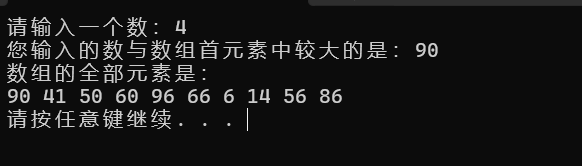
cout << "您输入的数与数组首元素中较大的是:" << myCompare(j, a) << endl;
cout << "数组的全部元素是:" << endl;
for (auto i : a)
cout << i << " ";
cout << endl;
return 0;
}
输出如下:
练习 6.22
对于题目的要求有两种理解,一种是交换指针本身的值,即指针所指的内存地址;另一种是交换指针所指的内容。
为了全面性考虑,我们在程序中实现了三个不同版本的函数。
第一个函数以值传递的方式使用指针,所有改变都局限于函数内部,当函数执行完毕后既不会改变指针本身的值,也不会改变指针所指的内容。
第二个函数同样以值传递的方式使用指针,但是在函数内部通过解引用的方式直接访问内存并修改了指针所指的内容。
第三个函数的参数形式是 int *&,其含义是,该参数是一个引用,引用的对象是内存中的一个 int 指针,使用这种方式可以把指针当成对象,交换指针本身的值。需要注意的是,最后一个函数既然交换了指针,当然解引用该指针所得的结果也会相应发生改变。
#include <iostream>
using namespace std;
// 该函数既不交换指针,也不交换指针所指的内容
void SwapPointer1(int* p, int* q)
{
int* temp = p;
p = q;
q = temp;
}
// 该函数交换指针所指的内容
void SwapPointer2(int* p, int* q)
{
int temp = *p;
*p = *q;
*q = temp;
}
// 该函数交换指针本身的值,即交换指针所指的内存地址
void SwapPointer3(int*& p, int*& q)
{
int* temp = p;
p = q;
q = temp;
}
int main()
{
int a = 5, b = 10;
int* p = &a, * q = &b;
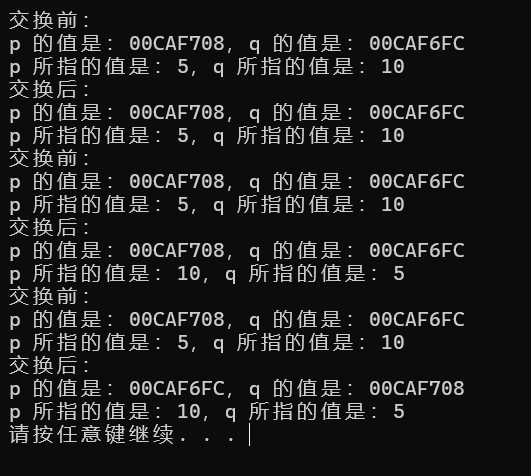
cout << "交换前:" << endl;
cout << "p 的值是:" << p << ",q 的值是:" << q << endl;
cout << "p 所指的值是:" << *p << ",q 所指的值是:" << *q << endl;
SwapPointer1(p, q);
cout << "交换后:" << endl;
cout << "p 的值是:" << p << ",q 的值是:" << q << endl;
cout << "p 所指的值是:" << *p << ",q 所指的值是:" << *q << endl;
a = 5, b = 10;
p = &a, q = &b;
cout << "交换前:" << endl;
cout << "p 的值是:" << p << ",q 的值是:" << q << endl;
cout << "p 所指的值是:" << *p << ",q 所指的值是:" << *q << endl;
SwapPointer2(p, q);
cout << "交换后:" << endl;
cout << "p 的值是:" << p << ",q 的值是:" << q << endl;
cout << "p 所指的值是:" << *p << ",q 所指的值是:" << *q << endl;
a = 5, b = 10;
p = &a, q = &b;
cout << "交换前:" << endl;
cout << "p 的值是:" << p << ",q 的值是:" << q << endl;
cout << "p 所指的值是:" << *p << ",q 所指的值是:" << *q << endl;
SwapPointer3(p, q);
cout << "交换后:" << endl;
cout << "p 的值是:" << p << ",q 的值是:" << q << endl;
cout << "p 所指的值是:" << *p << ",q 所指的值是:" << *q << endl;
return 0;
}
输出如下:
练习 6.23
根据参数的不同,为 print 函数设计几个版本。版本的区别主要体现在对指针参数的管理方式不同。
实现了三个版本的 print 函数,第一个版本不控制指针的边界,第二个版本由调用者指定数组的维度,第三个版本使用 C++11 新规定的 begin 和 end 函数限定数组边界。满足题意的程序如下所示:
#include <iostream>
using namespace std;
// 参数是常量整型指针
void print1(const int* p)
{
cout << *p << endl;
}
// 参数有两个,分别是常量整型指针和数组的容量
void print2(const int* p, const int sz)
{
int i = 0;
while (i != sz)
{
cout << *p++ << endl;
++i;
}
}
// 参数有两个,分别是数组的首尾边界
void print3(const int* b, const int* e)
{
for (auto q = b; q != e; ++q)
cout << *q << endl;
}
int main()
{
int i = 0, j[2] = { 0, 1 };
print1(&i);
print1(j);
print2(&i, 1);
// 计算得到数组 j 的容量
print2(j, sizeof(j) / sizeof(*j));
auto b = begin(j);
auto e = end(j);
print3(b, e);
return 0;
}
输出如下:

练习 6.24
当我们想把数组作为函数的形参时,有三种可供选择的方式:
一是声明为指针,
二是声明为不限维度的数组,
三是声明为维度确定的数组。
实际上,因为数组传入函数时实参自动转换成指向数组首元素的指针,所以这三种方式是等价的。
由之前的分析可知,print 函数的参数实际上等同于一个常量整型指针 const int*,形参 ia 的维度 10 只是我们期望的数组维度,实际上不一定。即使实参数组的真实维度不是 10,也可以正常调用 print 函数。
上述 print 函数的定义存在一个潜在风险,即虽然我们期望传入的数组维度是10,但实际上任意维度的数组都可以传入。如果传入的数组维度较大,print 函数输出数组的前 10 个元素,不至于引发错误;相反如果传入的数组维度不足 10,则print 函数将强行输出一些未定义的值。
修改后的程序是:
void print(const int ia[], const int sz)
{
for (size_t i = 0; i != sz; ++i)
cout << ia[i] << endl;
}
附上书上原话:

练习 6.25
#include <iostream>
using namespace std;
int main(int argc, char** argv)
{
string str;
for (int i = 0; i != argc; ++i)
str += argv[i];
cout << str << endl;
return 0;
}
输入命令参数:
输出如下:

练习 6.26
#include <iostream>
using namespace std;
int main(int argc, char** argv)
{
for (int i = 0; i != argc; ++i)
{
cout << "argv[" << i << "]: " << argv[i] << endl;
}
return 0;
}
输入命令参数:
输出如下:
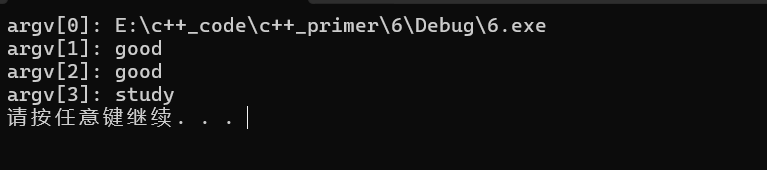
练习 6.27
满足题意的程序如下所示,注意 iCount 的参数是 initializer_list 对象,在调用该函数时,我们使用了列表初始化的方式生成实参。
#include <iostream>
using namespace std;
int iCount(initializer_list<int> il)
{
int count = 0;
// 遍历 il 的每一个元素
for (auto val : il)
count += val;
return count;
}
int main()
{
// 使用列表初始化的方式构建 initializer_list<int>对象
// 然后把它作为实参传递给函数 iCount
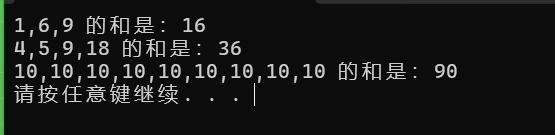
cout << "1,6,9 的和是:" << iCount({ 1, 6, 9 }) << endl;
cout << "4,5,9,18 的和是:" << iCount({ 4, 5, 9, 18 }) << endl;
cout << "10,10,10,10,10,10,10,10,10 的和是:"
<< iCount({ 10, 10, 10, 10, 10, 10, 10, 10, 10 }) << endl;
return 0;
}
输出如下:
练习 6.28
initializer_list<string>的所有元素类型都是 string,因此 const auto &elem : il 推断得到的 elem 的类型是 const string&。使用引用是为了避免拷贝长字符串,把它定义为常量的原因是我们只需读取字符串的内容,不需要修改它。
练习 6.29
引用类型的优势主要是可以直接操作所引用的对象以及避免拷贝较为复杂的类
类型对象和容器对象。因为 initializer_list 对象的元素永远是常量值,所以我们不可能通过设定引用类型来更改循环控制变量的内容。只有当
initializer_list 对象的元素类型是类类型(比如 string)或容器类型时,才有必要把范围 for 循环的循环控制变量设为引用类型。
6.3 节练习
练习 6.30
附上书上原话


练习 6.31
如果引用所引的是函数开始之前就已经存在的对象,则返回该引用是有效的;如果引用所引的是函数的局部变量,则随着函数结束局部变量也失效了,此时返回的引用无效。
当不希望返回的对象被修改时,返回对常量的引用。
练习 6.32
该函数是合法的。get 函数接受一个整型指针,该指针实际指向一个整型数组的首元素,另外还接受一个整数表示数组中某个元素的索引值。它的返回值类型是整型引用,引用的对象是 arry 数组的某个元素。当 get 函数执行完毕后,调用者得到实参数组 arry 中索引为 index 的元素的引用。
在 main 函数中,首先创建一个包含 10 个整数的数组,名字是 ia。请注意,由于 ia 定义在 main 函数的内部,所以 ia 不会执行默认初始化操作,如果此时我们直接输出 ia 每个元素的值,则这些值都是未定义的。接下来进入循环,每次循环使用 get 函数得到数组 ia 中第 i 个元素的引用,为该引用赋值 i,也就是说,为第 i 个元素赋值 i。循环结束时,ia 的元素依次被赋值为 0~9。
练习 6.33
#include <iostream>
#include <vector>
using namespace std;
// 递归函数输出 vector<int>的内容
void print(vector<int> vInt, unsigned index)
{
unsigned sz = vInt.size();
if (!vInt.empty() && index < sz)
{
cout << vInt[index] << endl;
print(vInt, index + 1);
}
}
int main()
{
vector<int> v = { 1,3,5,7,9,11,13,15 };
print(v, 0);
return 0;
}
输出如下:

练习 6.34
因为原文中递归函数的参数类型是 int,所以理论上用户传入 factorial 函数的参数可以是负数。按照原程序的逻辑,参数为负数时函数的返回值是 1。如果修改递归函数的停止条件,则当参数的值为负时,会依次递归下去,执行连续乘法操作直至溢出。因此,不能把 if 语句的条件改成上述形式。
练习 6.35
如果把 val-1 改成 val--,则出现一种我们不期望看到的情况,即变量的递减操作与读取变量值的操作共存于同一条表达式中,这时有可能产生未定义的值。
练习 6.36
要想使函数返回数组的引用并且该数组包含 10 个 string 对象,可以按照如下所示的形式声明函数:
string (&func( ))[10];
上述声明的含义是:func()表示调用 func 函数无须任何实参,(&func( ))表示函数的返回结果是一个引用,(&func( ))[10]表示引用的对象是一个维度为 10 的数组,string (&func( ))[10]表示数组的元素是 string 对象。
练习 6.37
使用类型别名:
typedef string arr[10];
arr& func( );
使用尾置返回类型:
auto func( ) -> string(&) [10];
使用 decltype 关键字:
string str[10];
decltype(str) &func( );
练习 6.38
满足题意的 arrPtr 函数是:
int odd[] = { 1,3,5,7,9 };
int even[] = { 0,2,4,6,8 };
// 返回一个引用,该引用所引的对象是一个含有 5 个整数的数组。
decltype(odd)& arrPtr(int i)
{
return (i % 2) ? odd : even; // 返回数组的引用。
}
6.4 节练习
练习 6.39
(a)的第二个声明是非法的。它的意图是声明另外一个函数,该函数只接受整型常量作为实参,但是因为顶层 const 不影响传入函数的对象,所以一个拥有顶层const 的形参无法与另一个没有顶层 const 的形参区分开来。
(b)的第二个声明是非法的。它的意图是通过函数的返回值区分两个同名的函数,但是这不可行,因为 C++规定重载函数必须在形参数量或形参类型上有所区别。如果两个同名函数的形参数量和类型都一样,那么即使返回类型不同也不行。
(c)的两个函数是重载关系,它们的形参类型有区别。
6.5 节练习
练习 6.40
在上面的两个声明中,(a)是正确的而(b)是错误的。它们都用到了默认实参,但是C++规定一旦某个形参被赋予了默认实参,则它后面的所有形参都必须有默认实参。这一规定是为了防范可能出现的二义性,显然(b)违反了这一规定。
练习 6.41
(a)是非法的,该函数有两个默认实参,但是总计有三个形参,其中第一个形参并未设定默认实参,所以要想调用该函数,至少需要提供一个实参。
(b)是合法的,本次调用提供了两个实参,第一个实参对应第一个形参 ht,第二个实参对应第二个形参 wd,其中 wd 的默认实参没有用到,第三个形参 bckgrnd 使用它的默认实参。
(c)在语法上是合法的,但是与程序的原意不符。从语法上来说,第一个实参对应第一个形参 ht,第二个实参的类型虽然是 char,但是它可以自动转换为第二个形参 wd 所需的 int 类型,所以编译时可以通过,但这显然违背了程序的原意,正常情况下,字符'*'应该被用来构成背景。
练习 6.42
对于英语单词来说,大多数名词的复数是在单词末尾加's'得到的,也有一部分名词在单数转变为复数时需要在末尾加'es'。我们可以把's'作为默认实参,大多数情况下不必考虑这个参数,只有在遇到末尾是'es'的单词时才专门处理。
#include <iostream>
#include <string>
using namespace std;
// 最后一个形参赋予了默认实参
string make_plural(size_t ctr, const string& word, const string& ending= "s")
{
return (ctr > 1) ? word + ending : word;
}
int main()
{
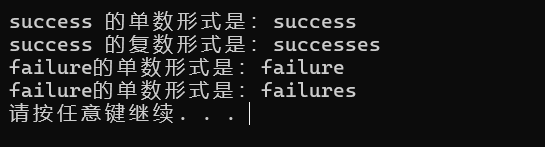
cout << "success 的单数形式是:" << make_plural(1, "success", "es")
<< endl;
cout << "success 的复数形式是:" << make_plural(2, "success", "es")
<< endl;
// 一般情况下调用该函数只需要两个实参
cout << "failure的单数形式是:" << make_plural(1, "failure") << endl;
cout << "failure的单数形式是:" << make_plural(2, "failure") << endl;
return 0;
}
输出如下:
练习 6.43
(a)应该放在头文件中。因为内联函数的定义对编译器而言必须是可见的,以便编译器能够在调用点内联展开该函数的代码,所以仅有函数的原型不够。并且,与一般函数不同,内联函数有可能在程序中定义不止一次,此时必须保证在所有源文件中定义完全相同,把内联函数的定义放在头文件中可以确保这一点。
(b)是函数声明,应该放在头文件中。
练习 6.44
改写后的内联函数是:
inline bool isShorter(const string &s1, const string &s2)
{
return s1.size() < s2.size();
}
练习 6.45
决定一个函数是否应该是内联函数有很多评判的依据。一般来说,内联机制适用于规模较小、流程直接、频繁调用的函数。一旦函数被定义成内联的,则在编译阶段就展开该函数,以消除运行时产生的额外开销。如果函数的规模很大(比如上百行)不利于展开或者函数只被调用了一两次,那么这样的函数没必要也不应该是内联的。
练习 6.46
constexpr 函数是指能用于常量表达式的函数,constexpr 函数的返回类型和所有形参的类型都得是字面值类型,而且函数体中必须有且只有一条 return 语句。
显然 isShorter 函数不符合 constexpr 函数的要求,它虽然只有一条return语句,但是返回的结果调用了标准库string类的size()函数和<比较符,无法构成字面值类型,因此不能改写成 constexpr 函数。
练习 6.47
#include <iostream>
#include <vector>
using namespace std;
// 递归函数输出 vector<int>的内容
void print(vector<int> vInt, unsigned index)
{
unsigned sz = vInt.size();
// 设置在此处输出调试信息
#ifndef NDEBUG
cout << "vector 对象的大小是:" << sz << endl;
#endif // NDEBUG
if (!vInt.empty() && index < sz)
{
cout << vInt[index] << endl;
print(vInt, index + 1);
}
}
int main()
{
vector<int> v = { 1,3,5,7,9,11,13,15 };
print(v, 0);
return 0;
}
输出如下:
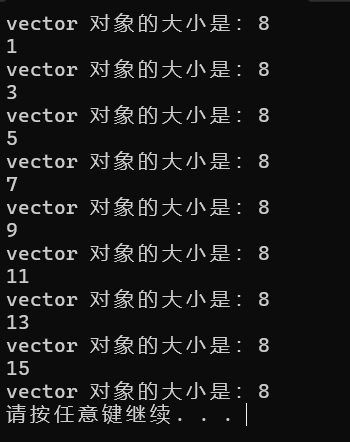
打开调试器时,每次递归调用 print 函数都会输出“vector 对象的大小是:8”;关闭调试器时,程序只输出 vector 对象的内容,不再输出其大小。
练习 6.48
该程序对 assert 的使用有不合理之处。在调试器打开的情况下,当用户输入字符串 s 并且 s 的内容与 sought 不相等时,执行循环体,否则继续执行assert(cin);语句。换句话说,程序执行到 assert 的原因可能有两个,一是用户终止了输入,二是用户输入的内容正好与 sought 的内容一样。如果用户尝试终止输入(事实上用户总有停止输入结束程序的时候),则 assert 的条件为假,输出错误信息,这与程序的原意是不相符的。当调试器关闭时,assert 什么也不做。
附上书上原话:

6.6 节练习
练习 6.49
当程序中存在多个同名的重载函数时,编译器需要判断调用的是其中哪个函数,这时就有了候选函数和可行函数两个概念。
函数匹配的第一步是选定本次调用对应的重载函数集,集合中的函数称为候选函数。候选函数具备两个典型特征:一是与被调用的函数同名,二是其声明在调用点可见。
函数匹配的第二步是考查本次调用提供的实参,然后从候选函数中选出能被这组实参调用的函数,这些新选出的函数称为可行函数。可行函数也有两个特征:一是其形参数量与本次调用提供的实参数量相等,二是每个实参的类型与对应的形参类型相同或者能转换成形参的类型。
练习 6.50
可行函数是指形参数量与本次调用提供的实参数量相等且每个实参的类型都与对应的形参类型相同或者能转换成形参类型的函数。
最佳匹配是指该函数每个实参的匹配都不劣于其他可行函数需要的匹配且至少有一个实参的匹配优于其他可行函数提供的匹配。
根据上述分析,我们可以推断出:
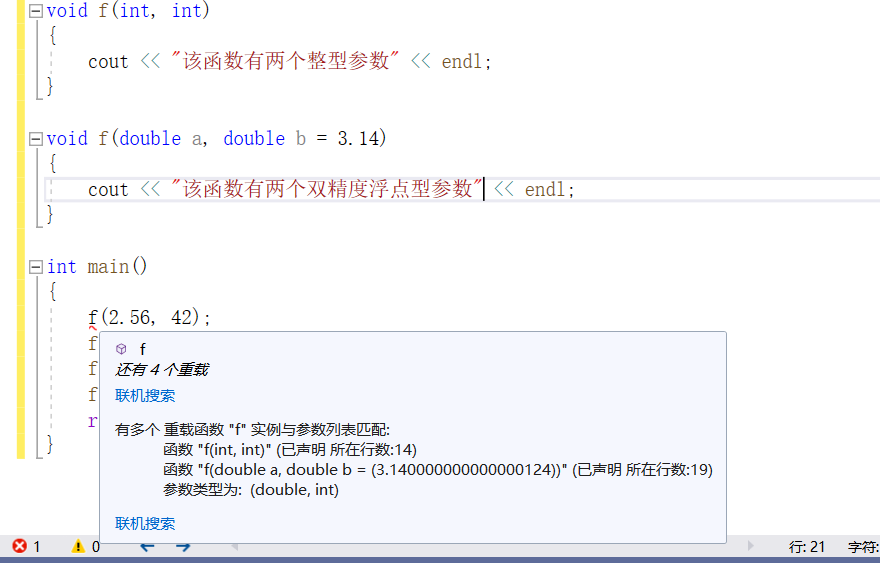
f(2.56, 42)的可行函数是 void f(int, int)和 void f(double, double = 3.14)。但是最佳匹配不存在,因为这两个可行函数各有所长。对于这次调用来说,如果只考虑第一个实参 2.56,我们发现,void f(double, double = 3.14)能够精确匹配,但是要想匹配第二个参数,int 类型的实参 42 必须转换成 double类型。如果考虑第二个实参 42,我们发现,void f(int, int)能够精确匹配,但是要想调用 void f(int, int)就必须把第一个 double 类型的实参 2.56 转换成 int 类型。最终的结果是这两个可行函数各自在一个实参上实现了更好的匹配,
但是把它们比较起来无从判断孰优孰劣,因此编译器将因为这个调用具有二义性而拒绝其请求。
f(42)的可行函数是 void f(int)和 void f(double, double = 3.14),其中最佳匹配是 void f(int),因为参数无须做任何类型转换。
f(42, 0)的可行函数是 void f(int, int)和 void f(double, double
= 3.14),其中最佳匹配是 void f(int, int),因为参数无须做任何类型转换。
f(2.56, 3.14) 的可行函数是 void f(int, int)和 void f(double,
double = 3.14),其中最佳匹配是 void f(double, double = 3.14),因为参数无须做任何类型转换。
练习 6.51
#include <iostream>
using namespace std;
void f()
{
cout << "该函数无须参数" << endl;
}
void f(int)
{
cout << "该函数有一个整型参数" << endl;
}
void f(int, int)
{
cout << "该函数有两个整型参数" << endl;
}
void f(double a, double b = 3.14)
{
cout << "该函数有两个双精度浮点型参数" << endl;
}
int main()
{
f(2.56, 42);
f(42);
f(42, 0);
f(2.56, 3.14);
return 0;
}
还未编译运行,Visual Studio自动显示出来错误:
练习 6.52
(a)发生的参数类型转换是类型提升,字符型实参自动提升成整型。
(b)发生的参数类型转换是算术类型转换,双精度浮点型自动转换成整型。
附上书上原话:

练习 6.53
(a)是合法的,两个函数的区别是它们的引用类型的形参是否引用了常量,属于底层 const,可以把两个函数区分开来。
(b)是合法的,两个函数的区别是它们的指针类型的形参是否指向了常量,属于底层 const,可以把两个函数区分开来。
(c)是非法的,两个函数的区别是它们的指针类型的形参本身是否是常量,属于顶层 const,根据本节介绍的匹配规则可知,向实参添加顶层 const 或者从实参中删除顶层 const 属于精确匹配,无法区分两个函数。
6.7 节练习
练习 6.54
满足题意的函数如下所示:
int func(int, int);
满足题意的 vector 对象如下所示:
vector<decltype(func)* > vF;
练习 6.55
#include <iostream>
#include <vector>
using namespace std;
// 加法
int func1(int a, int b)
{
return a + b;
}
// 减法
int func2(int a, int b)
{
return a - b;
}
// 乘法
int func3(int a, int b)
{
return a * b;
}
// 除法
int func4(int a, int b)
{
return a / b;
}
int main()
{
decltype(func1)* p1 = func1, * p2 = func2, * p3 = func3, * p4 = func4;
vector<decltype(func1)* > vF = { p1, p2, p3, p4 };
return 0;
}
练习 6.56
#include <iostream>
#include <vector>
using namespace std;
// 加法
int func1(int a, int b)
{
return a + b;
}
// 减法
int func2(int a, int b)
{
return a - b;
}
// 乘法
int func3(int a, int b)
{
return a * b;
}
// 除法
int func4(int a, int b)
{
return a / b;
}
void Compute(int a, int b, int (*p)(int, int))
{
cout << p(a, b) << endl;
}
int main()
{
int i = 5, j = 10;
decltype(func1)* p1 = func1, * p2 = func2, * p3 = func3, * p4 = func4;
vector<decltype(func1)* > vF = { p1, p2, p3, p4 };
for (auto p : vF) // 遍历 vector 中的每个元素,依次调用四则运算函数
{
Compute(i, j, p);
}
return 0;
}
输出如下:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!