11. 使用MySQL之使用数据处理函数
1. 函数
与其他大多数计算机语言一样,SQL支持利用函数来处理数据。
函数一般是在数据上执行的,它给数据的转换和处理提供了方便。
在前一章中用来去掉串尾空格的RTrim()就是一个函数的例子。
补充:
函数没有SQL的可移植性强
能运行在多个系统上的代码称为可移植的(portable)。
相对来说,多数SQL语句是可移植的,在SQL实现之间有差异时,这些差异通常不那么难处理。而函数的可移植性却不强。几乎每种主要的DBMS的实现都支持其他实现不支持的函数,而且有时差异还很大。
为了代码的可移植,许多SQL程序员不赞成使用特殊实现的功能。虽然这样做很有好处,但不总是利于应用程序的性能。如果不使用这些函数,编写某些应用程序代码会很艰难。必须利用其他方法来实现DBMS非常有效地完成的工作。
如果你决定使用函数,应该保证做好代码注释,以便以后你(或其他人)能确切地知道所编写SQL代码的含义。
2. 使用函数
大多数SQL实现支持以下类型的函数。
-
用于处理文本串(如删除或填充值,转换值为大写或小写)的文本函数。
-
用于在数值数据上进行算术操作(如返回绝对值,进行代数运算)的数值函数。
-
用于处理日期和时间值并从这些值中提取特定成分(例如,返回两个日期之差,检查日期有效性等)的日期和时间函数。
-
返回DBMS正使用的特殊信息(如返回用户登录信息,检查版本细节)的系统函数。
2.1 文本处理函数
上一章中我们已经看过一个文本处理函数的例子,其中使用 RTrim()函数来去除列值右边的空格。
下面是另一个例子,这次使用 Upper() 函数:
select vend_name, upper(vend_name) as vend_name_upcase
from vendors
order by vend_name;
输出如下:
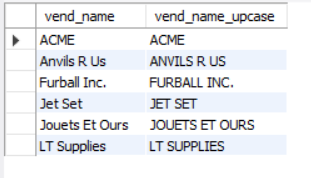
Upper()将文本转换为大写,因此本例子中每个供应商都列出两次,第一次为vendors表中存储的值,第二次作为列vend_name_upcase转换为大写。
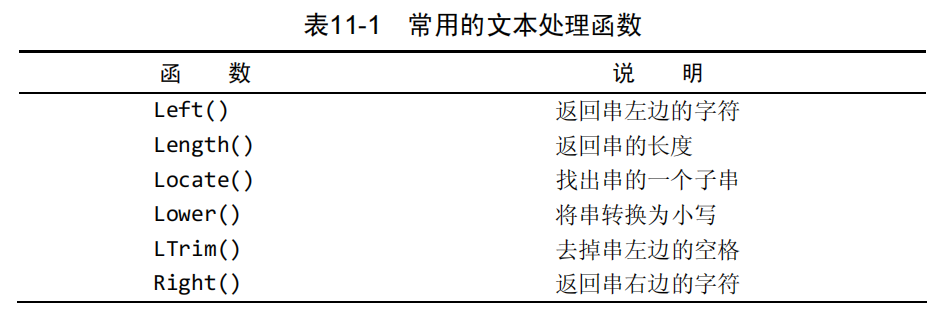
下面列出了某些常用的文本处理函数。

-
对
SOUNDEX做进一步的解释:SOUNDEX是一个将任何文本串转换为描述其语音表示的字母数字模式的算法。SOUNDEX考虑了类似的发音字符和音节,使得能对串进行发音比较而不是字母比较。虽然
SOUNDEX不是SQL概念,但MySQL(就像多数DBMS一样)都提供对SOUNDEX的支持。下面给出一个使用Soundex()函数的例子。
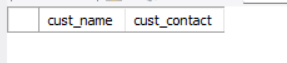
customers表中有一个顾客Coyote Inc.,其联系名为Y Lee。但如果这是输入错误,此联系名实际应该是Y Lie,怎么办?显然,按正确的联系名搜索不会返回数据,如下所示:
select cust_name, cust_contact from customers where cust_contact = 'Y Lie';输出如下:
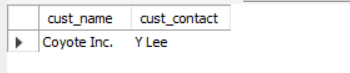
现在试一下使用Soundex()函数进行搜索,它匹配所有发音类似于Y Lie的联系名:
select cust_name, cust_contact from customers where soundex(cust_contact) = soundex('Y Lie');输出如下:
在这个例子中,WHERE子句使用
Soundex()函数来转换cust_contact列值和搜索串为它们的SOUNDEX值。因为Y.Lee和Y.Lie发音相似,所以它们的SOUNDEX值匹配,因此WHERE子句正确地过滤出了所需的数据。 -
对
Left()做进一步的解释:在 MySQL 中,LEFT() 函数用于从字符串的左边提取指定长度的子字符串。
语法:
LEFT(string, length)-
string:要从中提取子字符串的字符串。
-
length:要提取的字符数。
举例:
SELECT LEFT('Hello, World!', 5); -- 输出 'Hello'即从字符串 'Hello, World!' 中提取从左边开始的 5 个字符。
再比如,如果你有一个存储姓名的表 students,并且想要提取每个学生姓名的前两个字符,你可以这样写:
SELECT LEFT(name, 2) FROM students;这个查询会返回每个姓名的前两个字符。
注意:
在 MySQL 中,
LEFT()函数同样可以处理中文字符。它会根据字符的个数(而不是字节数)来提取中文字符。举个例子:

第一条select语句的结果如下:
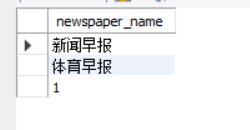
第二条select语句的结果如下:
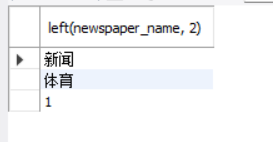
-
-
对
Right()做进一步的解释:在 MySQL 中,RIGHT() 函数用于从字符串的右边提取指定长度的子字符串。
其余的和
Left()一样,不赘叙 -
对
locate()做进一步的解释:在 MySQL 中,LOCATE 函数用于查找子字符串在字符串中的位置。它返回子字符串第一次出现的起始位置索引,如果未找到则返回 0。
语法
LOCATE(substring, string[, start])-
substring:要查找的子字符串。
-
string:要在其中查找的字符串。
-
start(可选):指定查找的起始位置(从 1 开始),默认从第一个字符开始。
返回值
-
如果找到子字符串,返回其在字符串中的 起始位置索引(从 1 开始)。
-
如果找不到子字符串,返回 0。
举例
-
查找子字符串的简单示例
查找子字符串 "cat" 在字符串 "concatenate" 中的位置:
SELECT LOCATE('cat', 'concatenate');返回结果:4(cat 从第 4 个字符开始)。
-
指定查找的起始位置
从位置 5 开始查找 "cat" 在 "concatenate" 中的位置:
SELECT LOCATE('cat', 'concatenate', 5);返回结果:0(因为在第 5 位及之后没有 cat 出现)。
-
与 WHERE 子句结合使用
在表中查找包含特定子字符串的记录。例如,在 products 表中查找产品描述包含 "special" 的记录:
SELECT product_id, description FROM products WHERE LOCATE('special', description) > 0;该查询将返回 description 列中包含 "special" 的所有记录。
注意
-
LOCATE 区分大小写。如果需要不区分大小写的查找,可以使用
LOWER()函数来转换为小写后再查找。SELECT LOCATE('special', LOWER(description)) FROM products;
-
-
对
substring()做进一步解释在 MySQL 中,SUBSTRING 函数用于从一个字符串中提取子字符串。它可以根据指定的起始位置和长度来截取部分内容。
语法
SUBSTRING(string, start[, length])-
string:要提取子字符串的字符串。
-
start:子字符串的起始位置(从 1 开始,负数表示从字符串末尾开始计数)。
-
length(可选):要提取的子字符串的长度。如果省略,则会一直提取到字符串末尾。
举例
-
从指定位置提取子字符串
提取字符串 "Hello, World!" 从第 8 个字符开始的内容:
SELECT SUBSTRING('Hello, World!', 8);返回结果:"World!"
-
提取指定长度的子字符串
从字符串 "Hello, World!" 的第 8 个字符开始提取 5 个字符:
SELECT SUBSTRING('Hello, World!', 8, 5);返回结果:"World"
-
从字符串末尾开始提取
如果 start 是负数,则从字符串末尾开始计数。提取字符串 "Hello, World!" 的最后 6 个字符:
SELECT SUBSTRING('Hello, World!', -6);返回结果:"World!"
-
与 WHERE 子句结合
从 products 表中的 description 列提取每个描述的前 10 个字符:
SELECT product_id, SUBSTRING(description, 1, 10) AS short_description FROM products;
注意
-
SUBSTRING 的起始位置从 1 开始,而不是 0。
-
如果只提供 start 而不提供 length,SUBSTRING 会提取到字符串末尾。
-
-
对
substring_index做进一步解释:在 MySQL 中,SUBSTRING_INDEX 函数用于根据指定的分隔符从字符串中提取子字符串。它会在字符串中查找指定的分隔符,然后根据出现的次数截取字符串的一部分。
语法
SUBSTRING_INDEX(string, delimiter, count)-
string:要操作的字符串。
-
delimiter:用来分隔字符串的分隔符。
-
count:指定提取部分的次数:
-
如果 count 为正数,则从字符串的 开始位置起提取,直到遇到的第 count 个分隔符。
-
如果 count 为负数,则从字符串的 结尾位置起提取,直到遇到的第 count 个分隔符。
-
举例
-
提取字符串的前几部分
提取字符串 "apple,banana,cherry" 中前两个逗号分隔的部分:
SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', 2);返回结果:"apple,banana"
这里,count 为 2,表示返回前两个分隔符(逗号)之前的部分。
-
提取字符串的后几部分
从字符串 "apple,banana,cherry" 中提取逗号分隔的最后两个部分:
SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', -2);返回结果:"banana,cherry"
这里,count 为 -2,表示返回从字符串结尾处起,倒数两个分隔符之后的部分。
-
在 WHERE 子句中使用
假设 emails 表的 email_address 列存储邮箱地址,并且希望提取邮箱地址中的域名(即 @ 符号后的部分):
SELECT email_address, SUBSTRING_INDEX(email_address, '@', -1) AS domain FROM emails;返回结果将是每个邮箱地址的域名部分。
-
提取文件路径中的文件名
从文件路径中提取文件名。例如,提取路径 /home/user/docs/report.pdf 中的文件名:
SELECT SUBSTRING_INDEX('/home/user/docs/report.pdf', '/', -1);返回结果:"report.pdf"
注意
-
count 指定了分隔符的数量,而不是字符数量。
-
SUBSTRING_INDEX 是一种基于分隔符的提取方法,不适用于按字符位置截取子字符串的情况。
-
2.2 日期和时间处理函数
日期和时间采用相应的数据类型和特殊的格式存储,以便能快速和有效地排序或过滤,并且节省物理存储空间。
插入一个题外话:
MySQL 提供了几种专门用于日期和时间的数据类型,能够以高效的方式存储和操作这些数据。以下是主要的数据类型以及它们的格式:
-
DATE 类型
用于存储日期(不包括时间部分),格式为 'YYYY-MM-DD'。
存储大小:3 字节。
范围:1000-01-01 到 9999-12-31。
比如:
DATE '2024-10-24' -
TIME 类型
用于存储时间(不包括日期部分),格式为 'HH:MM:SS'。
存储大小:3 字节。
范围:'-838:59:59' 到 '838:59:59'(支持负时间表示持续时间的情况)
比如:
TIME '14:30:45' -
DATETIME 类型
用于存储日期和时间的组合,格式为 'YYYY-MM-DD HH:MM:SS'。
存储大小:8 字节。
范围:1000-01-01 00:00:00 到 9999-12-31 23:59:59。
比如:
DATETIME '2024-10-24 14:30:45' -
TIMESTAMP 类型
用于存储自 1970-01-01 00:00:00 UTC(Unix Epoch 时间)以来的秒数。与 DATETIME 类似,格式为 'YYYY-MM-DD HH:MM:SS'。
存储大小:4 字节(比 DATETIME 占用空间更小)。
范围:1970-01-01 00:00:01 UTC 到 2038-01-19 03:14:07 UTC。
TIMESTAMP 可以随着时区的不同而自动调整,因此常用于记录操作的时间戳(例如记录插入或更新时的时间)。
比如:
TIMESTAMP '2024-10-24 14:30:45' -
YEAR 类型
用于存储年份,格式为 'YYYY'。
存储大小:1 字节。
范围:1901 到 2155。
比如:
YEAR '2024'一个好玩的
如果是year '2156'呢?MySQL会做什么?
在 MySQL 中,YEAR 数据类型的有效范围是 1901 到 2155,因此 YEAR '2156' 是超出有效范围的。如果你尝试将 '2156' 存储在 YEAR 类型的字段中,会导致错误或数据被截断。
处理超出范围的值:
- 如果你尝试插入 YEAR '2156',MySQL 会产生一个警告或错误,具体行为取决于 SQL 模式的设置。如果是严格模式(STRICT 模式),则会抛出错误并阻止插入。如果不是严格模式,MySQL 可能会插入一个默认值(通常为 0000),并发出警告。
解决方案:
-
保持在范围内:在使用 YEAR 类型时,确保年份在 1901 到 2155 之间。如果需要存储 2156 或更大的年份,你可以考虑使用其他数据类型,如 INT 或 VARCHAR,以手动存储年份。
-
使用 DATETIME 或 TIMESTAMP:如果你需要存储更大范围的日期和时间,可以考虑使用 DATETIME 数据类型,虽然它占用更多的存储空间,但它能表示更大范围的年份(1000 到 9999)。
-
数据类型和格式的优势:
-
高效的存储:
这些数据类型经过优化,采用内部的二进制表示方式,从而节省存储空间。例如,DATE 只占 3 个字节,而一个字符型字符串表示同样的日期需要更多的空间。
-
高效的排序和过滤:
使用内置的日期和时间数据类型,可以高效地进行排序和过滤操作,而不需要额外的转换。
-
特殊的格式:
MySQL 在后台使用一种二进制格式来存储日期和时间,使得它们可以快速解析和计算。例如,虽然 DATETIME 看起来像 'YYYY-MM-DD HH:MM:SS',但它实际是以压缩的方式存储,并且能够快速比较和操作。
-
回归正题:
一般,应用程序不使用用来存储日期和时间的格式,因此日期和时间函数总是被用来读取、统计和处理这些值。由于这个原因,日期和时间函数在MySQL语言中具有重要的作用。
表11-2列出了某些常用的日期和时间处理函数。

迄今为止,我们都是用比较数值和文本的WHERE子句过滤数据,但数据经常需要用日期进行过滤。用日期进行过滤需要注意一些别的问题和使用特殊的MySQL函数。
首先需要注意的是MySQL使用的日期格式。
无论你什么时候指定一个日期,不管是插入或更新表值还是用WHERE子句进行过滤,日期必须为格式yyyy-mm-dd。因此,2005年9月1日,给出为2005-09-01。
虽然其他的日期格式可能也行,但这是首选的日期格式,因为它排除了多义性(如,04/05/06是2006年5月4日或2006年4月5日或2004年5月6日或……)
-
补充:
应该总是使用4位数字的年份:
支持2位数字的年份,MySQL处理00-69为2000-2069,处理70-99为1970-1999。虽然它们可能是打算要的年份,但使用完整的4位数字年份更可靠,因为MySQL不必做出任何假定。
因此,基本的日期比较应该很简单:
select cust_id, order_num
from orders
where order_date = '2005-09-01';
输出如下:
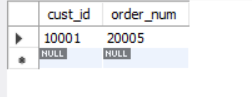
此SELECT语句正常运行。它检索出一个订单记录,该订单记录的order_date为2005-09-01。
但是,使用WHERE order_date = '2005-09-01'可靠吗?
order_ date的数据类型为datetime。这种类型存储日期及时间值。样例表中的值全都具有时间值00:00:00。如下图:
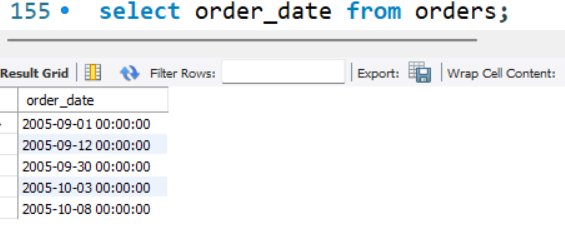
但实际中很可能并不总是这样。如果用当前日期和时间存储订单日期(因此你不仅知道订单日期,还知道下订单当天的时间), 怎么办 ?
比如,存储的 order_date 值为 2005-09-01 11:30:05,则 WHERE order_date = '2005-09-01'失败。即使给出具有该日期的一行,也不会把它检索出来,因为WHERE匹配失败。
解决办法是指示MySQL仅将给出的日期与列中的日期部分进行比较,而不是将给出的日期与整个列值进行比较。为此,必须使用 Date()函数。Date(order_date)指示MySQL仅提取列的日期部分。
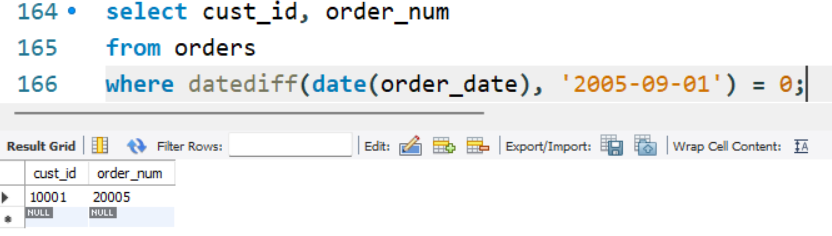
更可靠的SELECT语句为:
select cust_id, order_num
from orders
where date(order_date) = '2005-09-01';
输出如下:
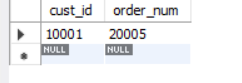
插一句题外话
自己试了下DateDiff()的写法
补充:
如果要的是日期,请使用Date():
如果你想要的仅是日期,则使用Date()是一个良好的习惯,即使你知道相应的列只包含日期也是如此。这样,如果由于某种原因表中以后有日期和时间值,你的SQL代码也不用改变。当然,也存在一个Time()函数,在你只想要时间时应该使用它。 Date()和Time()都是在MySQL 4.1.1中第一次引入的。
不过,还有一种日期比较需要说明。
如果你想检索出2005年9月下的所有订单,怎么办?简单的相等测试不行,因为它也要匹配月份中的天数。
有几种解决办法,其中之一如下所示:
select cust_id, order_num
from orders
where date(order_date) between '2005-09-01' and '2005-09-30';
输出如下:
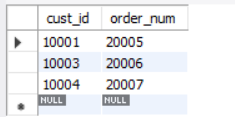
其中,BETWEEN操作符用来把2005-09-01和2005-09-30定义为一个要匹配的日期范围。
还有另外一种办法(一种不需要记住每个月中有多少天或不需要操心闰年2月的办法):
select cust_id, order_num
from orders
where year(order_date) = 2005 and month(order_date) = 9;
输出如下:
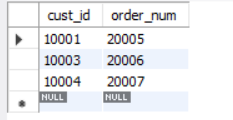
Year()是一个从日期(或日期时间)中返回年份的函数。类似,Month()从日期中返回月份。因此,WHERE Year(order_date)= 2005 AND Month(order_date) = 9检索出order_date为2005年9月的所有行。
补充:
-
MySQL的版本差异:
MySQL 4.1.1中增加了许多日期和时间函数。如果你使用的是更早的MySQL版本,应该查阅具体的文档以确定可以使用哪些函数。
-
DATE_SUB()和DATEDIFF()的区别:DATE_SUB() 和 DATEDIFF() 都是 MySQL 中用于操作日期的函数,但它们的功能完全不同:
-
DATE_SUB()用于从日期中减去一个时间间隔(如天、月、年等),返回一个新的日期。-
语法:
DATE_SUB(date, INTERVAL expr unit)-
date: 原始日期。
-
expr: 时间间隔的数量。
-
unit: 时间单位(如 DAY, MONTH, YEAR 等)。
-
-
功能:从日期减去指定的时间间隔,返回一个新的日期。
-
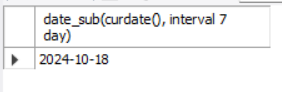
示例: 从当前日期减去 7 天:
select date_sub(curdate(), interval 7 day);输出如下:
-
-
DATEDIFF()用于计算两个日期之间的天数差,返回一个整数值,表示两个日期之间相差多少天。-
语法:
DATEDIFF(date1, date2)-
date1 和 date2: 两个日期,用于计算相差的天数。
-
结果为 date1 - date2,即 date1 减去 date2。
-
-
功能:计算两个日期之间的天数差,并返回整数结果。
-
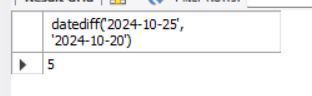
示例: 计算两个日期之间相差多少天:
select datediff('2024-10-25', '2024-10-20')输出如下:
-
-
-
ADDDATE()和DATE_ADD()的区别:在 MySQL 中,
ADDDATE()和DATE_ADD()这两个函数都用于向日期添加时间间隔,功能非常相似,主要的区别在于语法上的细微差异。-
ADDDATE() 用于向日期添加天数或指定的时间间隔。该函数有两种不同的用法:
-
可以直接添加天数。
-
也可以与 INTERVAL 一起使用,添加年、月、天等不同的时间单位。
语法:
-
直接添加天数:
ADDDATE(date, number_of_days)-
date: 要修改的日期。
-
number_of_days: 添加的天数,必须是整数
-
-
使用 INTERVAL:
ADDDATE(date, INTERVAL expr unit)-
date: 要修改的日期。
-
expr: 时间间隔的数量。
-
unit: 时间单位(如 DAY, MONTH, YEAR 等)。
-
-
-
-
DATE_ADD()函数与ADDDATE()的功能相同,但只能与 INTERVAL 结合使用,语法结构与 ADDDATE() 的第二种形式一致。
-
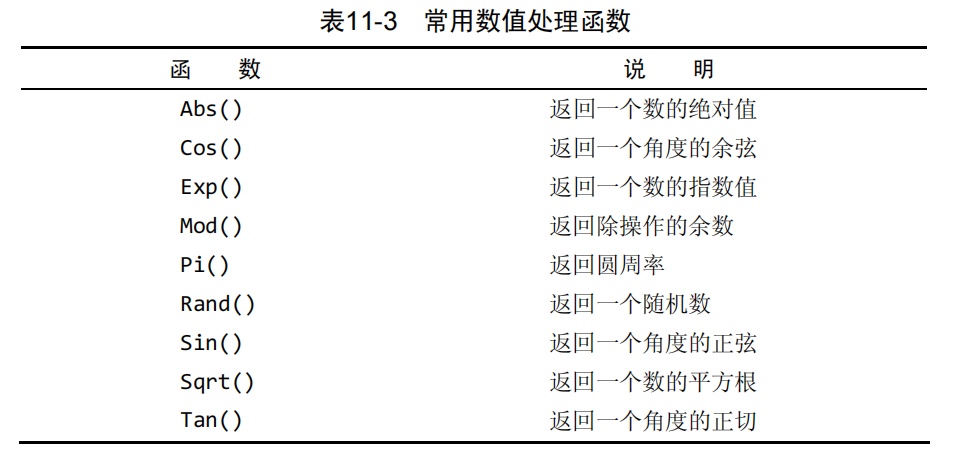
2.3 数值处理函数
数值处理函数仅处理数值数据。这些函数一般主要用于代数、三角或几何运算,因此没有串或日期—时间处理函数的使用那么频繁。
具有讽刺意味的是,在主要DBMS的函数中,数值函数是最一致最统一的函数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号