Creating, Reading and Writing(pandas学习一)
开始入门
要使用pandas库,通常从以下这行代码开始。
import pandas as pd
创建数据
pandas 中有两个核心对象:DataFrame(数据框)和 Series(系列)。
DataFrame
-
DataFrame是一个表格。它包含一个单独条目的数组,每个条目都有特定的值。每个条目对应一行(或一条记录)和一列。pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]})输出如下:
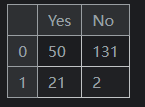
在这个例子中,“0, No”条目的值为 131。“0, Yes”条目的值为 50,依此类推。 -
DataFrame的条目不限于整数。例如,这里有一个DataFrame,其值为字符串:pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland.']})输出如下:
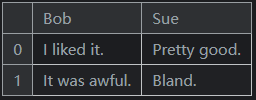
我们使用pd.DataFrame()构造函数来生成这些DataFrame对象。声明对象的语法是字典,其键是列名(本例中为Bob和Sue),其值是条目列表。这是构造DataFrame的标准方法,也是最有可能遇到的方法。 -
字典列表构造函数为列标签赋值,但只对行标签使用从0(0,1,2,3,…)开始的升序计数。有 时这是可以的,但通常我们希望自己分配这些标签。
在
DataFrame()中使用的行标签列表被称为索引。我们可以在构造函数中使用索引参数为其分配值:pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland.']}, index=['Product A', 'Product B'])输出如下:
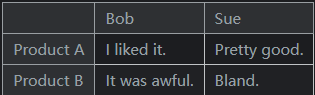
Series
-
与之相反,
Series是一系列数据值。如果说DataFrame是一个表格,那么Series就是一个列表。实际上,仅用一个列表就可以创建一个Series。pd.Series([1, 2, 3, 4, 5])输出如下:
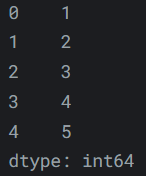
-
Series本质上是DataFrame的单个列。因此,可以像以前一样使用index参数为Series分配行标签。但是,Series没有列名,它只有一个整体名称:pd.Series([30, 35, 40], index=['2015 Sales', '2016 Sales', '2017 Sales'], name='Product A')输出如下:
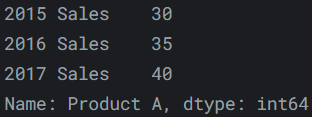
-
Series和DataFrame密切相关。将DataFrame想象成实际上只是一堆 “粘在一起” 的Series是很有帮助的。
读取数据文件
-
能够手动创建数据框或序列很方便。但是,在大多数情况下,我们实际上不会手动创建自己的数据。相反,我们将处理已经存在的数据。
-
数据可以以多种不同的形式和格式存储。其中最基本的当属
CSV文件。当你打开一个CSV文件时,会看到如下内容:
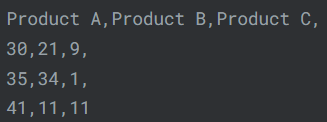
一个CSV文件是由逗号分隔的值组成的表格。因此得名:"Comma-Separated Values",即CSV。 -
我们将使用
pd.read_csv ()函数将数据读入数据框。具体如下:wine_reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv")-
我们可以使用
shape属性来检查生成的DataFrame的大小。wine_reviews.shape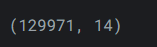
所以我们的
DataFrame有 130000 条记录分布在 14 个不同的列中。那几乎是 200 万个条目! -
我们可以使用
head()命令检查结果数据框的内容,该命令会抓取前五行。wine_reviews.head()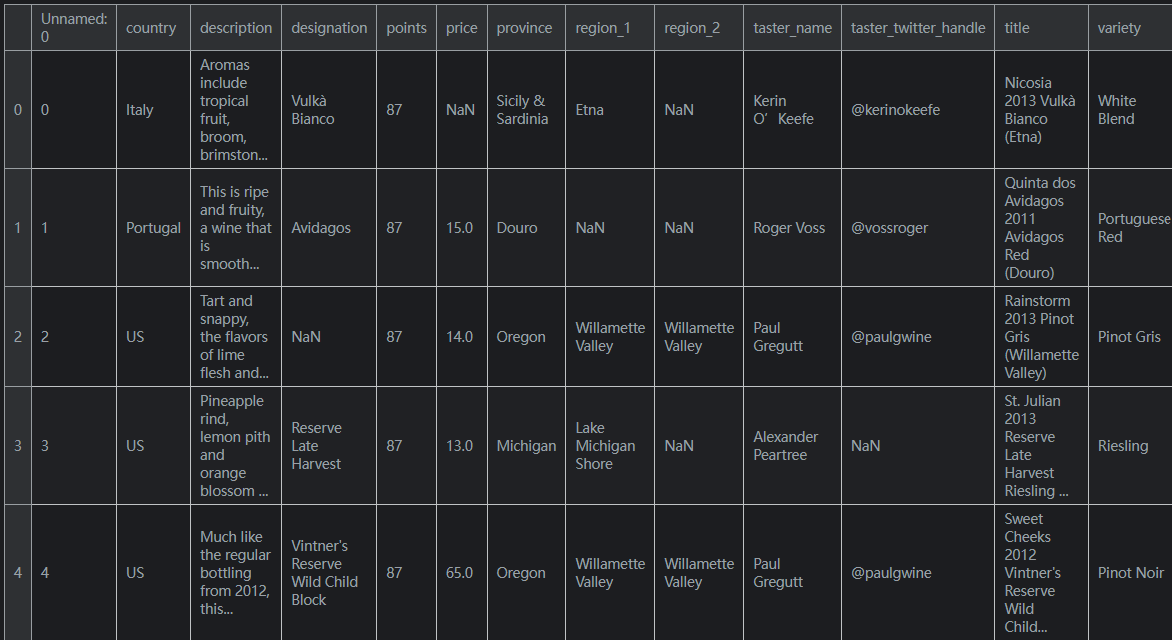
-
pd.read_csv()函数功能强大,可以指定30多个可选参数。例如,您可以在这个数据集中看到CSV文件有一个内置索引,pandas没有自动获取该索引。要使pandas使用该列作为索引(而不是从头开始创建一个新列),我们可以指定一个index_col。wine_reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col=0) wine_reviews.head()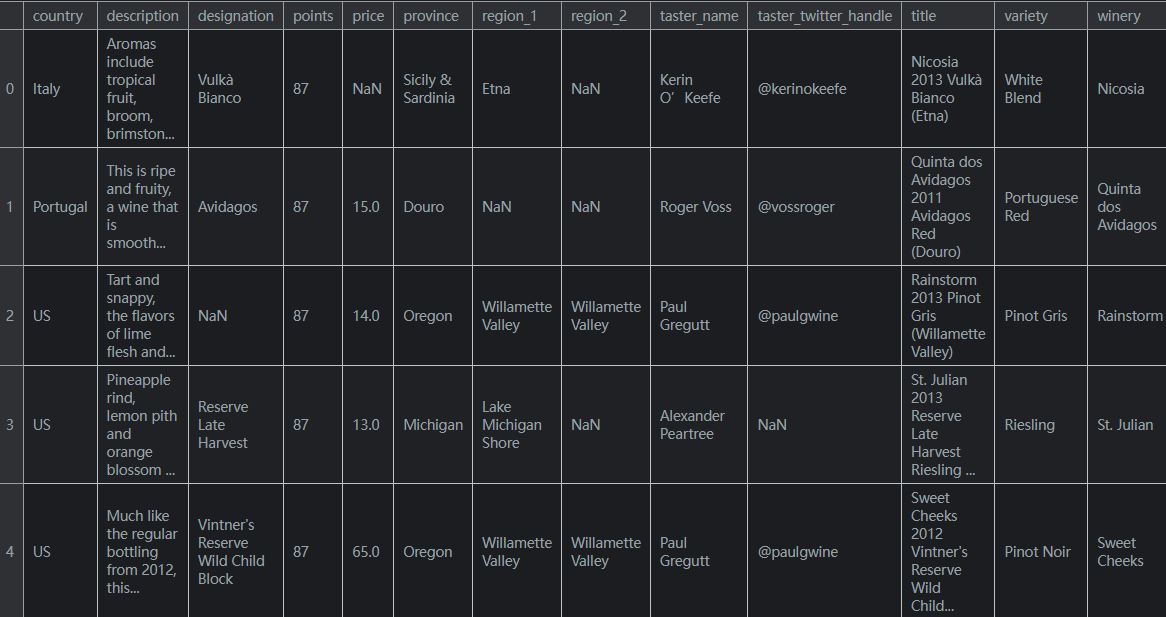
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号