如何用BERT的输出做分类?
第一次使用BERT时,发现如果我的输入是[1,512]的形状的 (512个token的index),那么输入就会是[1,512,768],这个时候就麻了,为啥会有512个768呀,虽然说我有512个输入,但是为啥BERT要输出512个768呢,原因目前还不清楚,不过现在知道了第一个768(outputs[0][0])是用来做分类的。
As we have seen earlier, BERT separates sentences with a special [SEP] token. During training the model is fed with two input sentences at a time such that:
- 50% of the time the second sentence comes after the first one.
- 50% of the time it is a a random sentence from the full corpus.
BERT is then required to predict whether the second sentence is random or not, with the assumption that the random sentence will be disconnected from the first sentence:

To predict if the second sentence is connected to the first one or not, basically the complete input sequence goes through the Transformer based model, the output of the [CLS] token is transformed into a 2×1 shaped vector using a simple classification layer, and the IsNext-Label is assigned using softmax.
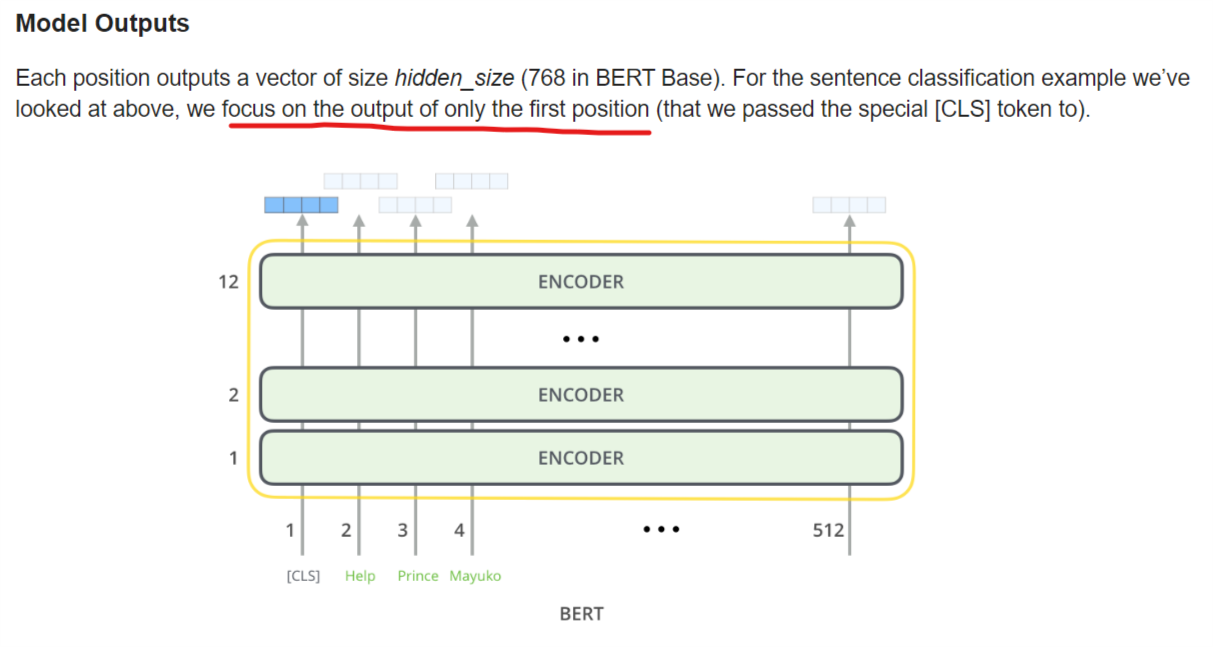
上面的图片说对于句子分类,我们用[CLS]对应的输出向量(第一个768维度的向量),如果有多个需要预测的目标呢?比如一个句子中有多个MaskedToken,个人觉得可以用MaskedToken所在位置的输出向量(比如,如果MaskToken在遮掩了第三个token,那我们是不是可以用第三个输出向量(output[0][2],并用argmax得到预测结果?)
参考文章:
https://jalammar.github.io/illustrated-bert/
https://medium.com/@samia.khalid/bert-explained-a-complete-guide-with-theory-and-tutorial-3ac9ebc8fa7c

 浙公网安备 33010602011771号
浙公网安备 33010602011771号