理解DeepL中的参数惩罚(penalty)
penalty机制中有L2范数的penalty,它长这个样子:
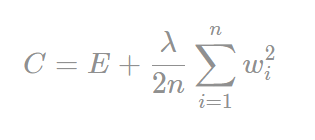
E是指一次前向计算, 输入与输出之间的 误差。后面的一部分就是L2 penalty。
现在让我们来看看C对某个参数Wi求导的结果:
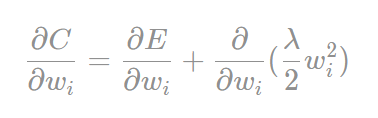
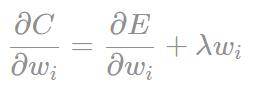
如果我们更新梯度的话:
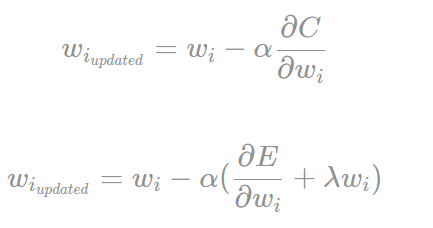
从上面的一个式子我们可以看出,w若越大,那么w衰减越厉害。(梯度始终为正数)
下面来说说为什么w不能很大:
w越大,模型就会越激进,它会不遗余力的去拟合训练集,所以会学习到一些对预测没用的东西。
The more big weights we have, the more active our neurons will be. They will use that additional power to fit the training data as closely as possible. As a consequence, they are more likely to pick up more of the random noise.


激进的模型 中庸的模型 摆烂的模型
本文截图均来自此文:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号