操作系统:保护模式 (三)分页机制
分页机制#
对于编译器而言,地址本身是连续的,被称作线性地址。在只分段的情况下,CPU 认为线性地址等同于物理地址,这种传统模型有以下缺陷:
- 分段模式要求每个段的内存是连续的,因此当需要分配大块内存时,可能会因为内存碎片的问题导致无法找到足够大的连续空间。这在程序运行过程中,特别是随着内存分配和释放的频繁进行,会造成内存的碎片化。
- 分段模式无法有效实现进程间的完全隔离。不同的进程共享相同的内存空间模型,如果段描述符配置错误,可能导致进程之间的内存冲突或数据泄露。
分页机制是通过将内存分为固定大小的页来进行管理,每个页在物理内存中的位置可以不连续。分页机制是 CPU 从硬件层面就支持的功能。因此一旦启用分页机制,汇编代码的线性的地址都会被CPU根据页表自动转化为物理地址。
一级页表#
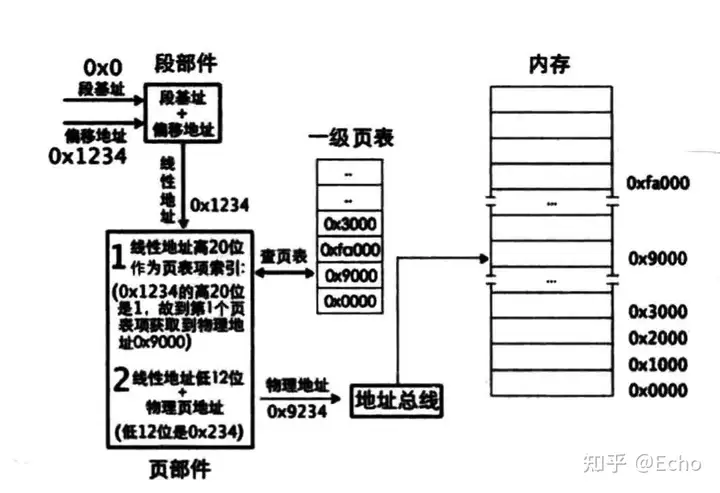
CPU 规定一页的长度为 4KB, 于是 4GB 空间被分为 1 M 页,32位的线性地址被分为两部分:高20位为页表索引,低12位为页内偏移。
二级页表#
一个页表项为 4个字节,完整的物理内存映射至少需要 4MB 空间以建立一级页表映射。每个进程都需要自己独立的地址空间,因此一级页表方案的内存消耗过大。
x86 默认使用二级页表分页,将1M个页平均放置到1K个页表中,每个页表包含1K个页表项,每个页表项4字节,即二级页表这个大小恰好是4KB大小,即一个页。与一级页表不同的是一级页表必须提前建立,每个进程都需要 4MB 空间进行映射,但是二级页表除了页目录表以外,其二级页表是动态建立的。极大的节约了空间。
传统x86二级分页,将线性空间分为:
- 高10位:用来定位页目录表中的一个页目录项 (PDE)(页目录项中包含页表的物理地址)
- 中间10位:用于在某个页表中定位页表项 (PTE)
- 低12位:页内偏移量
由于 PDE,PTE 的均为 4 字节长,在访问一个线性地址时:
- 用虚拟地址的高10位乘以4,再加上页目录表的物理地址,便是页目录项的物理地址,读取该物理地址处的内容,获得页表的物理地址
- 用虚拟地址的中间10位乘以4,再加上一步获得的页表的物理地址,便是页表项的的物理地址,读取页表项的内容,便可从页表项的数据结构中获取我们需要访问的物理地址
- 将该物理地址再加上虚拟地址的低12位,便是最终我们要访问的物理地址
页表项与页目录项一致:

| 位位置 | 属性位名称 | 含义 | 常见取值 |
|---|---|---|---|
| 0 | P (Present) | 页是否存在 | 0: 不存在,1: 存在 |
| 1 | R/W (Read/Write) | 页面读写权限 | 0: 只读,1: 可读写 |
| 2 | U/S (User/Supervisor) | 用户模式和内核模式的访问权限 | 0: 内核模式,1: 用户模式 |
| 3 | PWT (Page Write-Through) | 写策略 | 0: 回写(Write-back),1: 写通(Write-through) |
| 4 | PCD (Page Cache Disable) | 缓存策略 | 0: 允许缓存,1: 禁止缓存 |
| 5 | A (Accessed) | 该页是否被访问过 | 0: 未访问,1: 已访问 |
| 6 | D (Dirty) | 该页是否被修改过(仅页表项有效) | 0: 未修改,1: 已修改 |
| 7 | PS (Page Size) | 页的大小 | 0: 4KB 页,1: 4MB 页 |
| 8 | G (Global) | 是否为全局页面(TLB切换时不刷新) | 0: 非全局,1: 全局 |
| 9-11 | AVL (Available) | 保留位,操作系统可用 | 未定义,操作系统自定义使用 |
| 12-31 | Base Address | 页表或页的物理地址(对齐到4KB,低12位为0) | 页表或物理页的基地址 |
特别的,唯一的页目录物理地址需要提前存放到 CR3 寄存器(页目录基址寄存器):

PCD, PWT 位一般都取0. 因此低12位均为0.
多进程与分页机制#
- 页表是多进程操作系统实现虚拟内存的基础,每个进程有独立的页表,保证了内存隔离。
- 操作系统通过按需分配内存、共享内存、分页换页等机制,动态管理进程的虚拟地址空间。
- 虚拟地址空间的划分通常包括用户空间和内核空间,进程通过页表实现虚拟地址到物理地址的映射。
用户进程通常依赖操作系统的系统调用。也即内核空间的代码,操作系统在划分地址空间时,通常会将内核映射到高位地址。所有进程的内核空间都实际上对应同一片物理地址。
![[Pasted image 20240922150102.png]]
示例: 类 Linux 的地址空间映射#
startup_page:
mov ecx, 4096
mov esi, 0
.clear_page_dir:
mov byte [PAGE_DIR_TABLE_BASE + esi], 0
inc esi
loop .clear_page_dir
.create_pde:
mov eax, PAGE_DIR_TABLE_BASE
add eax, 0x1000
mov ebx, eax
or eax, PG_US_U | PG_RW_W | PG_P
; 第 0 PDE 和 第 768 PDE 都指向同一个页表(第0PTE)
; 第 0 PDE 是为了将 0x00000000 - 0x003FFFFF 映射到 0x00000000 - 0x003FFFFF.
; 第 768 PDE 是为了将 0x00000000 - 0x003FFFFF 映射到 0xC0000000 - 0xC03FFFFF.
; 因为我们内核和 loader 位于 低端 4 MB 之内, 而我们规定内核将会映射到虚拟地址的高 3GB 以上 (0xC0000000 - 0xFFFFFFFF)
; 至于 0 PDE 是为了保证,对于 loader 代码 (0 - 0xfffff) ,线性地址和物理地址是一样的。
mov dword [PAGE_DIR_TABLE_BASE + 0x0], eax
mov dword [PAGE_DIR_TABLE_BASE + 0xc00], eax
; 将最后 PDE 设为页目录表的物理地址,这是为了动态操作页表
sub eax, 0x1000
mov dword [PAGE_DIR_TABLE_BASE + 4092], eax
; 创建第 0 PTE
mov ecx, 1024 ; map 4MB
mov esi, 0
mov edx, PG_US_U | PG_RW_W | PG_P
.create_pte:
mov dword [ebx + esi * 4], edx
add edx, 4096
inc esi
loop .create_pte
; 创建内核其它 PDE
mov eax, PAGE_DIR_TABLE_BASE
add eax, 0x2000
or eax, PG_RW_W | PG_US_U | PG_P
mov ebx, PAGE_DIR_TABLE_BASE
mov ecx, 254 ; 769 - 1022 PDE
mov esi, 769
.create_kernel_pde:
mov [ebx + esi * 4], eax
inc esi
add eax, 0x1000
loop .create_kernel_pde
ret
在 Bochs 下的映射
0x00000000-0x003fffff -> 0x000000000000-0x0000003fffff
0xc0000000-0xc03fffff -> 0x000000000000-0x0000003fffff
# 后面三项是由于最后 PDE 设为页目录表的物理地址,bochs 将 PDE 表本身当作了 256 项 PTE 表导致的。
0xffc00000-0xffc00fff -> 0x000000101000-0x000000101fff
0xfff00000-0xffffefff -> 0x000000101000-0x0000001fffff
0xfffff000-0xffffffff -> 0x000000100000-0x000000100fff
- 访问页目录项:0xfffffxxx, 其中 xxx 是页目录项的索引 * 4
作者:himu-qaq
出处:https://www.cnblogs.com/himu-qaq/p/18429176
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构