TCP学习记录
-
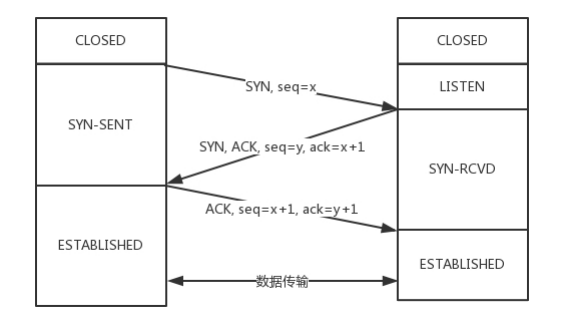
3次握手的流程

-
开始客户端和服务端都处于 CLOSED 状态。
-
先是服务端主动监听某个端口,处于 LISTEN 状态。
-
客户端主动发起连接 SYN,之后处于 SYN-SENT 状态
-
服务端收到发起的连接,返回 SYN,并且 ACK 客户端的 SYN,之后处于 SYN-RCVD 状态。
-
客户端收到服务端发送的 SYN 和 ACK 之后,发送 ACK 的 ACK,之后处于 ESTABLISHED 状态,因为它一发一收成功了。
-
服务端收到 ACK 的 ACK 之后,处于 ESTABLISHED 状态,因为它也一发一收了。
为什么是三次握手?
我认为核心的思想是为了发送端、接收端双方互相确认处于基本就绪的状态。
设定A为发送端,B为接收端。若为两次握手,在B确认应答后即确认连接。这个时候,A是知道B的状态是可用的,但B不确定A的状态是否还在可用状态。另一方面,如果A在发起连接的时候存在超时重传,多发了几个连接包,在A、B数据传输完毕关闭连接后,这个重传的包到达,如果B认为可以建立,那么就会引发无效连接。
那么,又为什么不是四次呢?这里四次、四十次都是差不多的,在A给B回复应答包(即第三次握手),也有可能会因为网络原因将应答包丢失,那岂不是意味着还得B来个应答包的应答?那这不是没完没了了吗。所以,这里保证双方都有一个来回,处于基本就绪状态即可。而且,就算第三次握手的包丢了,后续作为主动发起连接的A可以发送数据到B,也可以作为一个应答。而如果B关闭了,那么可以返回B不可达。
三次握手建立连接额外做的事情。
建立连接时确认包的序号,A在发起时需要提供自己序号(seq)给B,而B在应答A的SYN请求时,也需要回复一个自己的序号(seq)给A。而这个序号的生成策略又是怎么样的呢,这个策略可以概括为(计数器+随机hash)组合而成。计数器可以看成是32位的int类型,每过4毫秒就会+1,重新一轮开始大概需要4个多小时,已经远大于IP包的TTL时间。而仅仅依靠计数器还是有可能遇到重复的序号,所以还需要把发送端和接受端的ip和端口组合,再利用hash函数生成一个随机值即可避免重复。具体的规则为:hash (localhost, localport, remotehost, remoteport) 。
-
四次握手
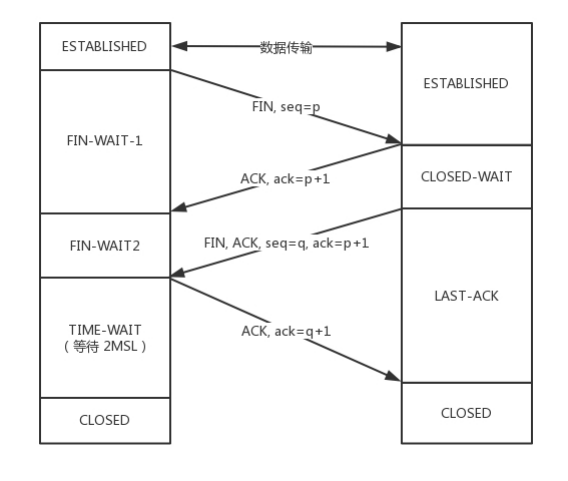
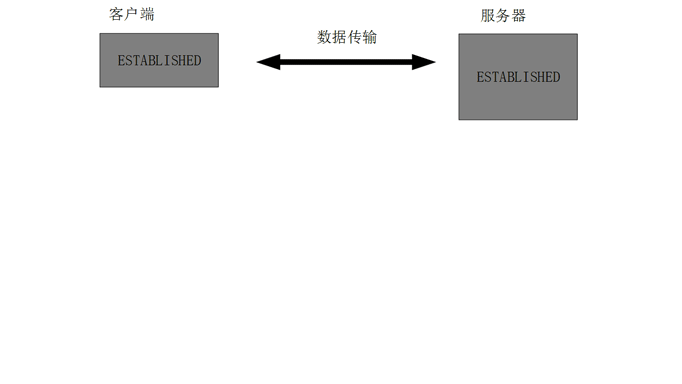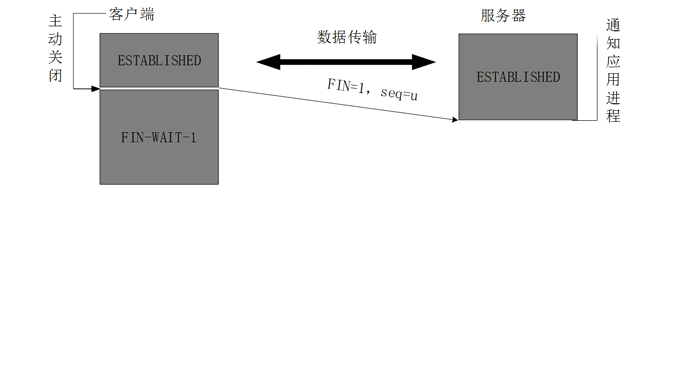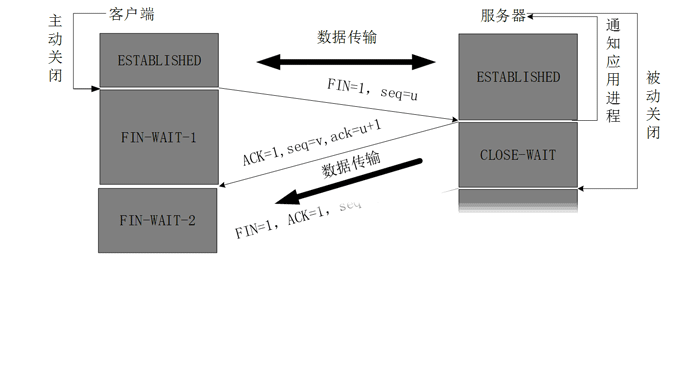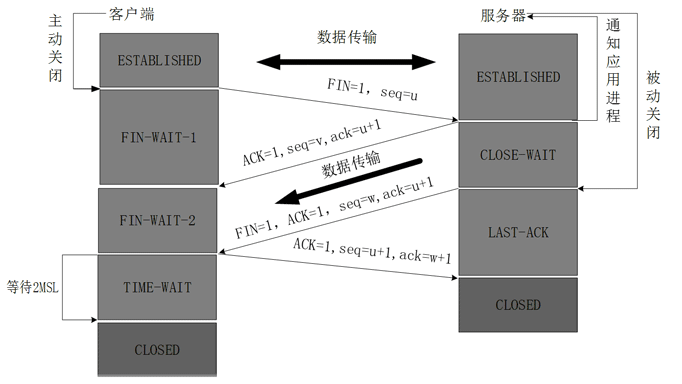
假设主动发起关闭的为客户端A。被动关闭的为服务端B。流程如下:
-
A主动发起Fin信号,请求关闭连接,进入Fin-wait-1状态。
-
B收到关闭请求后,回复Ack包。但此时被动关闭的那一方还可能有数据未发送,因此没有发送Fin包表示可以关闭连接。
-
A收到应答包后,进入Fin-wait-2状态,等待B完成数据传输。
-
A收到B的Fin包,表明B的数据已经传输完成,此时A进入TimeWait状态,等待最多2MSL。同时向B发送应答包。
-
B收到A的应答包,随即关闭连接。
-
2MSL时间过后,A也关闭连接。
为什么要等待2MSL的时间?
因为A发送的最后一个应答包有可能会丢失。此时如果B长时间没有收到这个应答包,那么B就会再发一个Fin包给A。A收到这个Fin包后知道可能是自己的应答包丢失了,此时再重新发送一个应答包。并刷新2MSL时间,重新等待。
另外,如果立即关闭,端口可能会被另一个连接所占用。此时如果B还有一些因为网络原因而延迟到达的数据包,虽然因为序列号不同可以区分。但是这里的等待时间也可以让这些包都被正确的丢弃处理。
MSL (Maximum Segment Lifetime) : 报文最大生存时间。般为2分钟,根据不同的实现有一点不同。Linux系统可以通过cat /proc/sys/net/ipv4/tcp_fin_timeout 查看。
为什么是四次握手?
其实与3次握手同理。额外的不同在于,被动关闭连接的一方可能还需要处理未发送完成的数据,因此需要一次额外的Fin应答来完成第三次握手。
-
确认应答
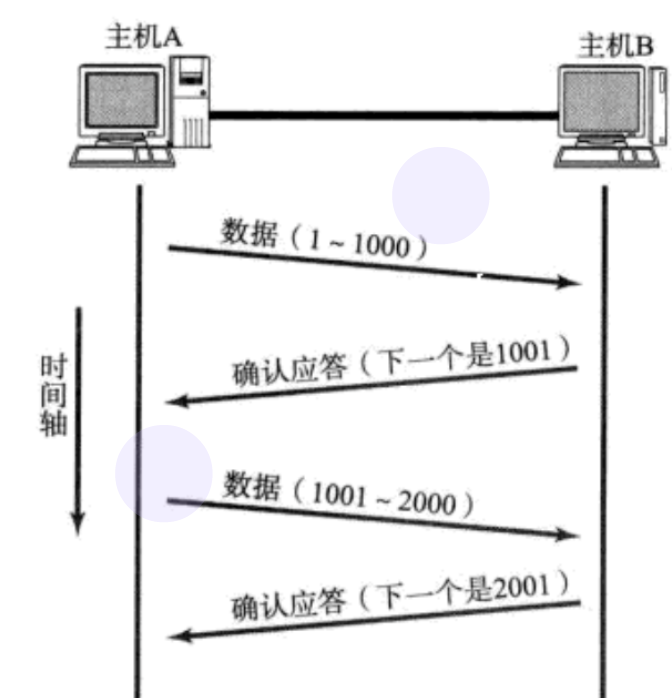
TCP协议发送的每一个数据包,都有一个唯一的序列号。通过这个序列号可以形成以下模式,通过发送与确认来保证数据包一定到达了目的地址。
发送端消息:本次数据包的序号为n。
接收端应答: 已收到序号为n的数据包,下一个数据包应该是n+1。
-
超时重传
当网络出现堵塞或故障时,某个数据包丢失。这个时候,主机A会维护一个计时器,记录每个包发送的时间,同时根据RTT(数据往返时间)加权平均算出一个数值,一旦超过了的时间阈值,主机A就会重新发送这个数据包。并且,如果触发了超时重传,即代表了网络不顺畅,不应该频繁的发送数据包,此时计时器会以原有将超时阈值*2,避免频率重传。
-
滑动窗口
上述模式,虽然可以进行数据的可靠数据传输,但是如果每次都等到接收端响应才能发送下一个,那么效率将会大大折扣。如果主机A可以一次性发送多个数据包,然后根据主机B的应答情况再进行重传或继续发送。那不是可以提高效率?
为了解决这个问题,TCP采用一种叫滑动窗口的算法,来控制发送端、接受端数据包的传送与接收。如下图所示:
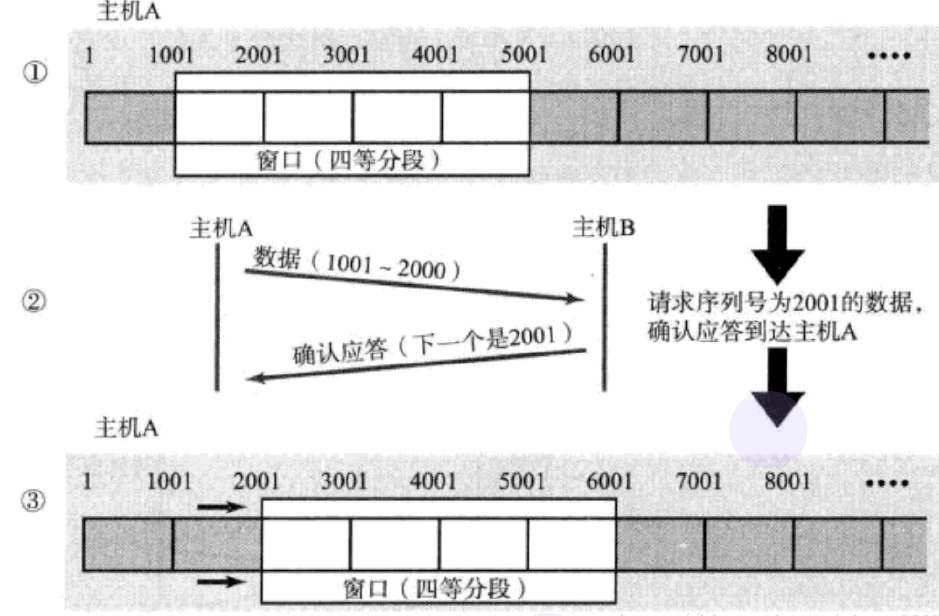
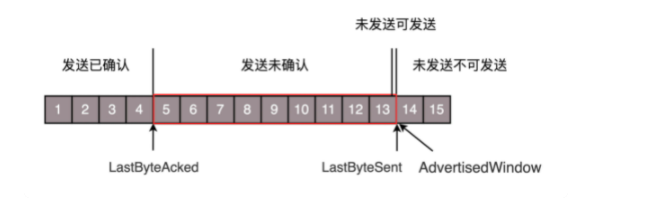
窗口左边界的左边,是已经完成并被Ack确认的数据包,窗口中是已经发送但没有Ack确认的数据包,窗口右边界右边是还未发送的数据包。每当主机B应答后,窗口就会向前滑动。同样,这里的确认应答也有优化的空间。例如:这里主机A一共发送了1、2、3、4总共四个数据包。假设主机B按照顺序收到,同时回复了4个Ack应答包,但是回复1、2、3的应答包丢失了,不过如果4的应答包收到,此时主机A还是能判断出1、2、3这几个包是已经确认收到的,就不需要触发超时重传了。
接收端同样维护着一个滑动窗口如下图。红色框就是一个滑动窗口,接收已确认是指已经发送Ack应答包给主机A的数据包,这些包在应用层程序读取后,窗口开始向右滑动。而等待接收未确认的是则是还没收到主机A的数据包。且当前能收到的最大数据包用量即为:(窗口大小-接收已确认大小)。
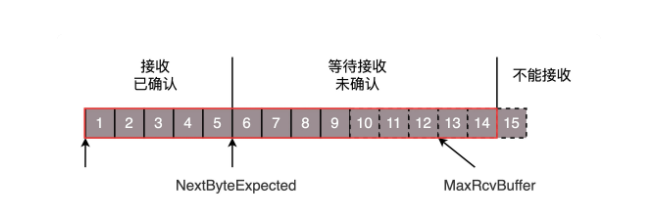
-
快速重传
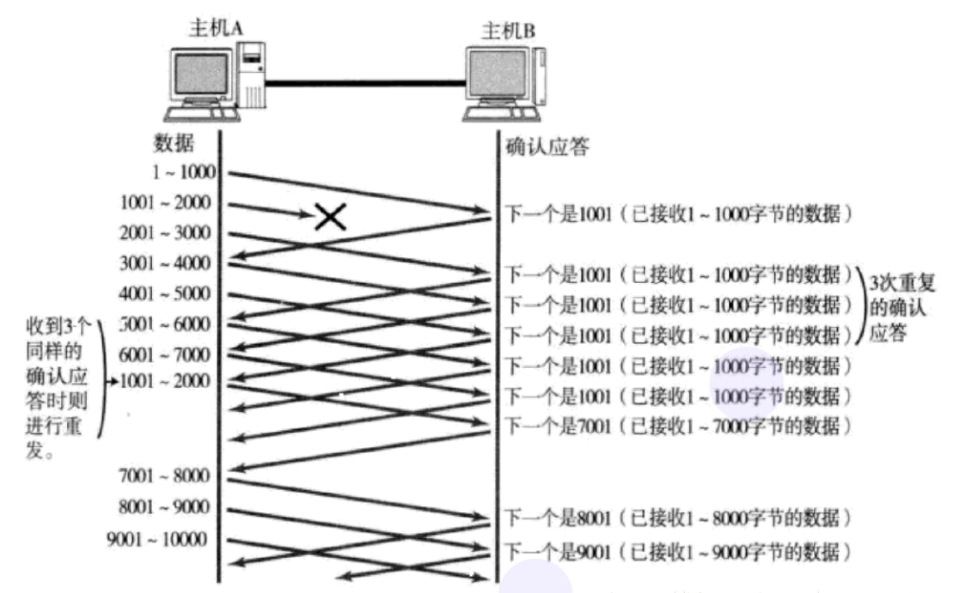
触发超时重传,需要等待一定的时间,而如果网络明明是畅通的,只是因为偶发故障而引起丢包,而又因为缺失这个应答而无法继续传输后面的数据包,那就会极大影响效率。这个时候就需要快速重传机制,这种机制概括的说:就是当一个包丢失,接收端在收到后面的数据包后,回复的应答指定的下一个包应该是丢失的那个包的序号。如下图:
在序号为1001的数据丢失后,后续接收2001、3001、4001的ACK应答都是指定要求发送1001,当发送端收到重复3个应答包时,就可以再次发送1001的数据包,而不用等待超时重传。
-
流量控制问题
在上述的滑动窗口算法中,一次性发送多个包固然可以极大的提高发送的效率。但是却引发了一个问题:最多可以发送多少数据包呢? 如果发少了那效率会受影响,如果发多了,那接收端有可能处理不过来。
这个时候就需要通过一种手段:由接收端告诉发送端当前可以接收的数据包数量,即根据接收端的处理能力来控制发送速率。这种机制就叫流量控制。
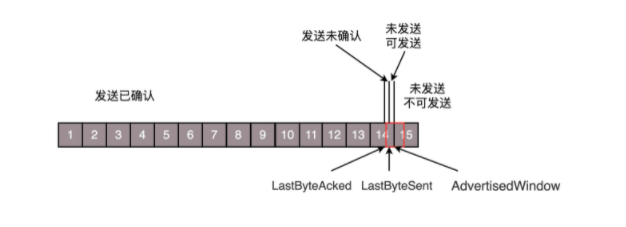
具体的做法是:在接收端发送Ack应答包的时候,都会把自己的可接受数据窗口大小返回给发送端,发送端根据这个大小来调整自己可以发送的数据包数量。在极端情况下,假设接收端一直没有读取数据,那么这个可发送的窗口会慢慢减小,甚至变为0。在等待一段时间后发送端才会主动探测是否可发送。
发送端:![]()
发送端:(极端情况下)![]()
接收端:![]()
-
拥塞控制问题
在复杂的网络环境中,发送端发送数据的速率不仅仅要考虑接收端是否能处理。还需要考虑网络带宽的承受能力,如果网络出现堵塞,那么此时的发送速率也应该降下来,否则发送出去的包会丢失,同时经进一步加重网络堵塞的情况。而具体的做法就称作拥塞控制。
我们应该要明白一个道理,网络带宽是有限的,而发送速率刚好能填满带宽的时候是效率最高的时候。多了会引起包丢失,触发超时重传。少了则会导致效率不高。
那就引出了一个问题:TCP怎么判断当前的发送速率是效率最高的呢?
对于TCP协议而言,它也不知道当前的网络状况,所以它开始也是不知道最佳发送速率是多少。那怎么办?只能慢慢的尝试。就好像擀面皮,一开始有一斤粉,你快速的倒入水。后面发现水倒得有点多了,就开始加一点面粉进去(相当于减少水的含量),然后继续观察是否合适,最后慢慢减少添加的面粉,成功做出一个最佳状态的面皮。
而对于TCP协议而言,它通过维护一个拥塞窗口,这里也可以理解为发送包的最大数量。刚开始,窗口大小为1,随着发送端收到Ack应答包后,TCP开始对网络有点信心,于是指数级的增大该窗口,即:第一次为1,第二次为2,第三次为4·····。等增加到超过某个阈值的时候,经验指导此时不能再指数级的递增了,那么就开始线性递增。然而带宽终究是有限度的,经过递增后发生了包丢失、超时重传等现象,那么TCP就判断发生了网络拥堵,应该降低窗口的大小。
降低的策略是什么呢?传统的方法是直接变为最开始的大小。这种明显过于粗暴,如果只是偶发事件,一下子清空窗口大小会导致效率大受影响。所以,更好的策略是将当前窗口大小减半,然后继续以线性增长的形式增长。如下图所示:
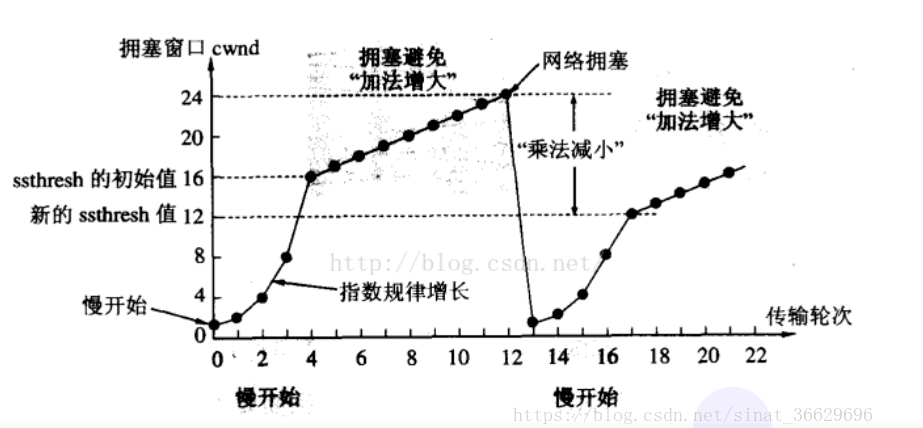
拥塞控制的算法是不断的改进的,还有一个TCP BBR拥塞算法,它针对偶发丢包引发的拥塞控制问题、提高带宽利用率等问题进行了改进。连接如下: https://queue.acm.org/detail.cfm?id=3022184
总结:拥塞控制(发送端限制发送数量),流量控制(接收端限定发送端的发送数量)。两者的最小值就是最大发送速率。max_speed = min{ 拥塞窗口,流量窗口}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号