IO模型以及IO多路复用概念简述
概念说明
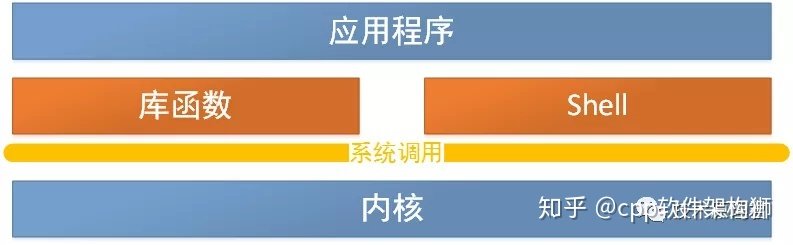
用户态与内核态
内核态:实从本质上说就是我们所说的内核,它是一种特殊的软件程序,特殊在哪儿呢?控制计算机的硬件资源,例如协调CPU资源,分配内存资源,并且提供稳定的环境供应用程序运行。内核程序可以访问内存的所有数据,包括外围设备,例如硬盘,网卡,cpu也可以将自己从一个程序切换到另一个程序。
用户态:用户态就是提供应用程序运行的空间,为了使应用程序访问到内核管理的资源例如CPU,内存,I/O。内核必须提供一组通用的访问接口,这些接口就叫系统调用。
文件描述符fd
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
基于文件描述符的I/O操作兼容POSIX标准,它既可以用于文件IO、也可以用于网络IO,因此大量的系统调用都是依赖于文件描述符。
IO模型的介绍
以下模型的介绍均参考书籍《UNIX网络编程卷1:套接字联网API(第3版)》
阻塞 I/O(blocking IO)
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
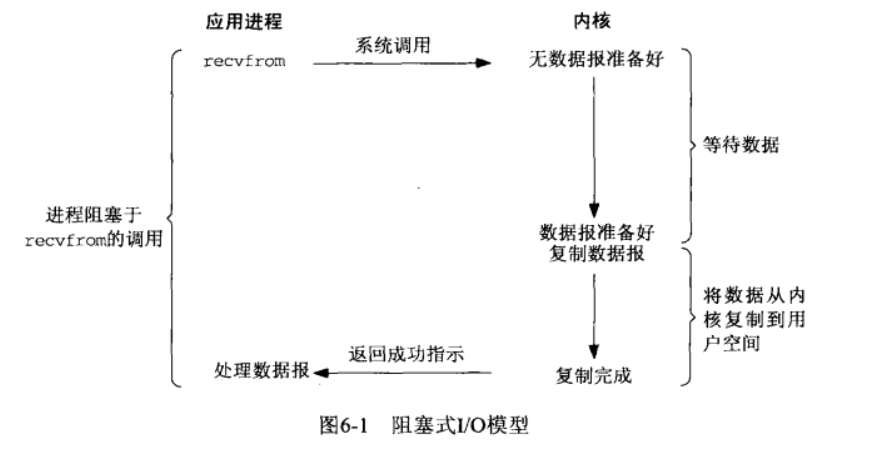
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从内核中拷贝到用户内存,然后内核返回结果,用户进程才解除block的状态,重新运行起来。
也就是说即使数据没准备好,程序依旧在这里等待。
非阻塞 I/O(nonblocking IO)
linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,流程是这个样子:
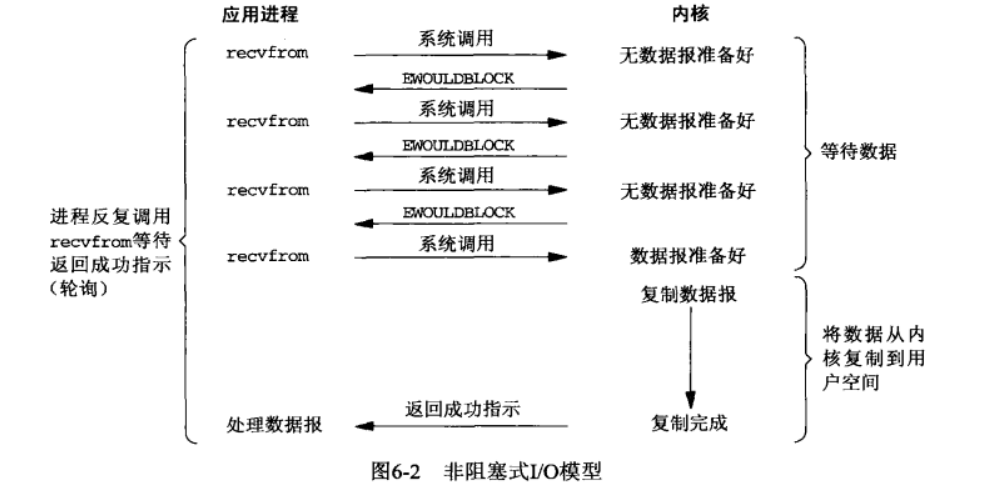
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
所以,nonblocking IO的特点是用户进程在执行read操作时并且数据没有准备好时,可以不被阻塞。
I/O 多路复用( IO multiplexing)
IO多路复用简单的说,就是通过select、poll、epoll等系统库的实现,利用单个线程监听多个连接,当其中一个连接的数据变得可读时,由操作系统通知线程进行读取。
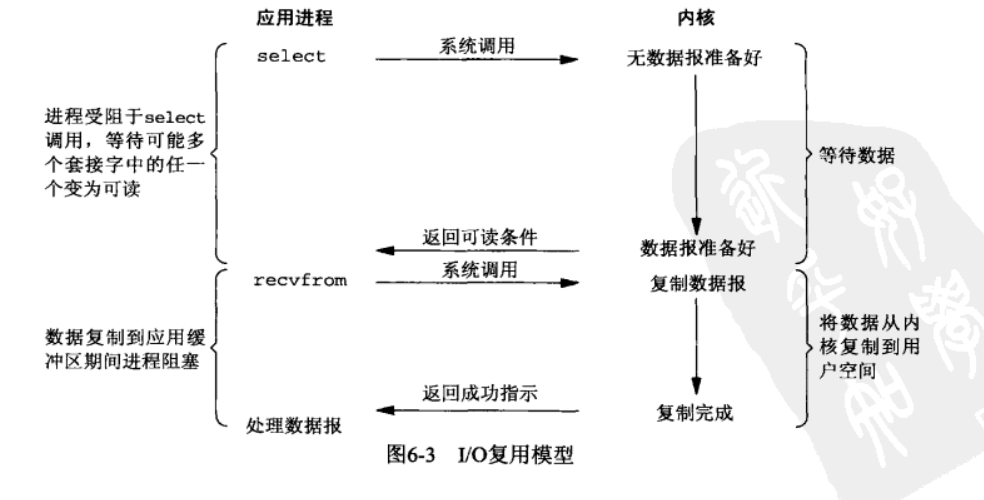
事实上如果并发量不高,维护一个线程池来对连接进行处理反而会比IO多路复用更加的高效,毕竟IO多路复用有两次系统调用。当然这个得具体情况具体分析。
信号驱动式I/O (signal-driven IO)
由于这个IO模型还没有比较出名的应用示例,这里也只是提一下有这么个模型,不做具体的说明,当然书里面还是有说的,有兴趣可以去看一看书。
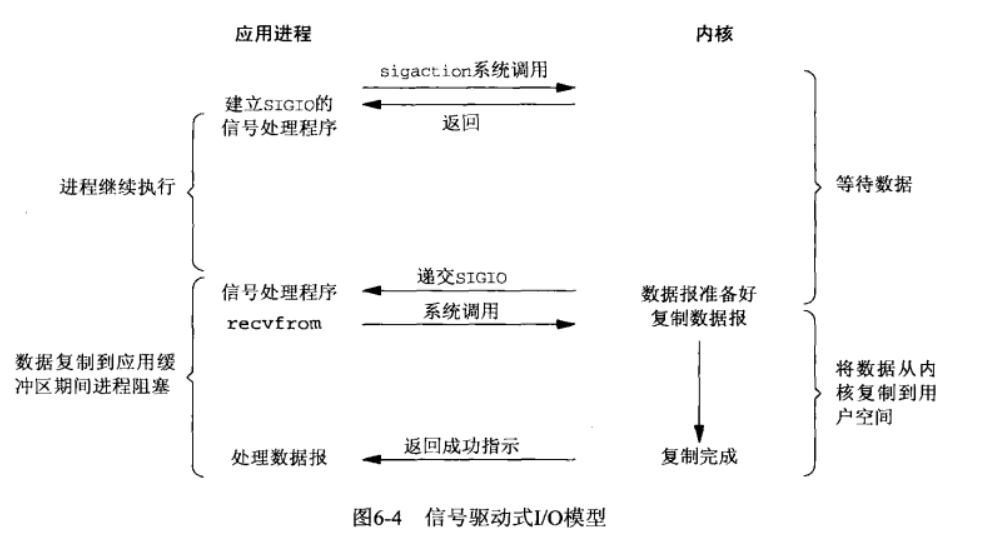
异步 I/O(asynchronous IO)
一般地说,它的工作机制是:告知内核启动某个操作,并让内核在整个操作 (包括将数据从内核复制到程序自己的缓冲区)完成后通知我们。这种模型与信号驱动模型的主要区别在于:信号驱动式IO是由内核通知我们何时可以启动一个IO操作,而异步IO模型是由内核通知我们IO操作何时完成。
IO模式比较
同步IO: 上述我们提到的模型,除了异步 I/O外,其余的模型都被认为是同步IO。仔细分析它的特征,可以得出它们主要的差别是在数据还未可读的时候,有着不同的处理方式:阻塞、非阻塞、内核回调等。
异步IO:而异步IO则是在哪个阶段不会阻塞,当进程收到通知时,数据已经被复制到进程空间里了。
IO多路复用的优势
前四种既然都是同步IO,IO多路复用比阻塞IO模型和非阻塞式IO模型好在哪里?
上面提到的两种模式要想及时响应请求:
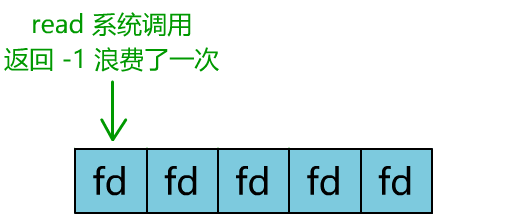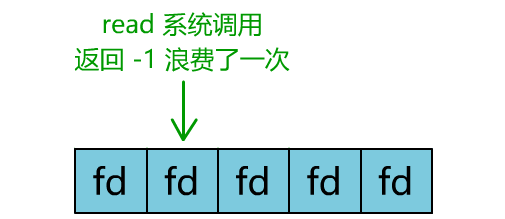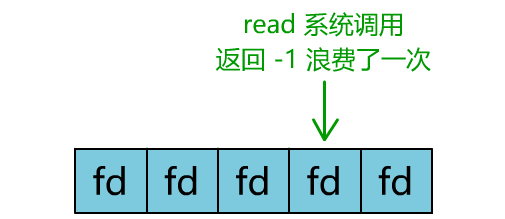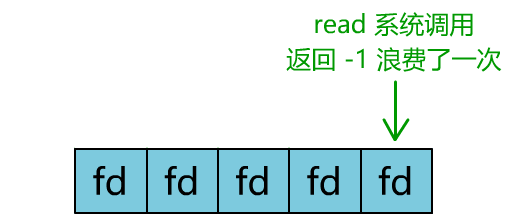
blocking IO需要创建多个线程去处理不同的连接请求,如果有很多个请求,每个请求都创一个线程那么系统资源很容易被耗光。nonblocking IO需要维护一个链表,然后不断的调用read()这个系统调用去轮询,如果轮询频率过高,会增加很多无意义的系统调用,要知道系统调用的代价还是很高的,轮询频率过低则会影响响应速度。
![]()
那么有没有一种方式,将要监听的文件描述符交给操作系统,由操作系统帮我们轮询呢?答案就是IO多路复用模型。而我们提到的select、poll、epoll就是基于这个模型不同的实现方式。
select
select的实现方式就是顾名思义,进程将自己要监听的文件描述符列表通过select系统调用传给内核,然后由内核帮我们确定哪些可以读写,然后做好标记并返回给我们,我们再通过遍历找到可以读写的文件描述符。
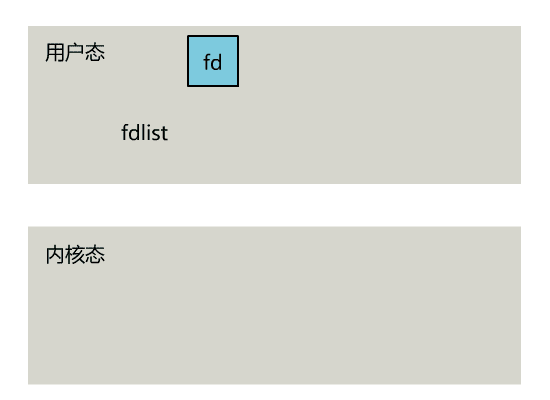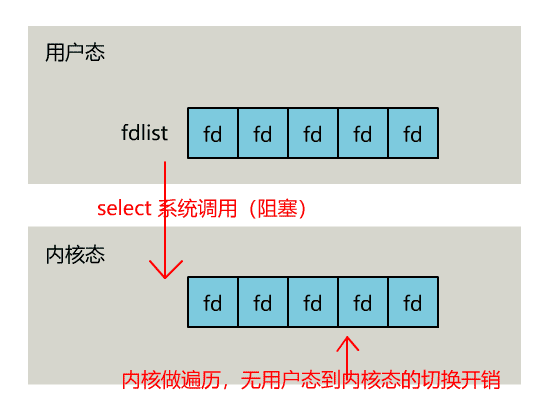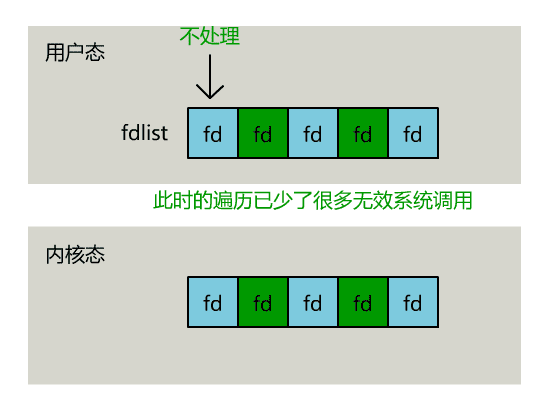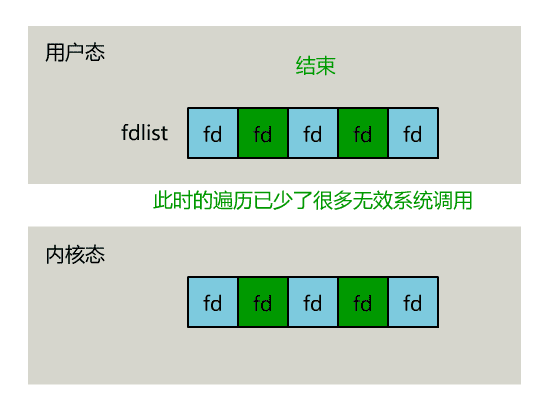
伪代码如下
// 接收连接请求,创建一个文件描述符
while(1) {
connfd = accept(listenfd);
fcntl(connfd, F_SETFL, O_NONBLOCK);
fdlist.add(connfd);
}
while(1) {
// 进行select调用,没有数据可读时阻塞
nready = select(list);
// 用户层依然要遍历,只不过少了很多无效的系统调用
for(fd <-- fdlist) {
if(fd != -1) {
// 只读已就绪的文件描述符
read(fd, buf);
// 总共只有 nready 个已就绪描述符,不用过多遍历
if(--nready == 0) break;
}
}
}
select的一些问题
- 每次调用select函数时,都需要传一份文件描述符的数据到内核,比较耗费资源。
- 调用返回的不是可以读写的列表,而是加上了一些标记返回原列表,还需要用户态进程自己遍历。
- 内核中通过轮询遍历文件描述符的可读写状态,而不是通过读写事件回调。
- select在设计上,有文件描述符列表的长度限制,现在长度限制一般为1024个。
poll
poll和select机制类似,区别在于取消了文件描述符列表的长度限制。但是select限制的目的也是为了性能。即使取消限制,当如果遇到要监听的列表很长也是不合适的。
epoll
epoll针对上面select说到的问题,进行了设计上的优化。如下:

- epoll会保存一个进程所打开的所有文件描述符列表,在调用epoll_wait时无需传入列表。
- 内核不再通过轮询的方式找到就绪的文件描述符,而是通过异步 IO 事件唤醒。
- 内核仅会将有 IO 事件的文件描述符返回给用户,用户也无需遍历整个文件描述符集合。
伪代码如下:
// 创建epoll对象
epfd = epoll_create(1024);
//向内核添加、修改或删除要监控的文件描述符
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
while(1) {
// 进行类似select的调用
nready = epoll_wait(int epfd, struct epoll_event *events, int max events, int timeout);(list);
doSomething()
}
总结
本次介绍了一系列IO模型的概念。同时说明了IO多路复用的一些实现的特点,以及分析它们存在的一些问题。根据上面的讲解,可以得出:IO多路复用在并发较高的场景下效率更好,原因是避免的创建多个线程消耗资源的同时,也避免了频繁的进行系统调用。取得了资源和性能的较好平衡,这也是为什么Redis、Nginx等一系列出名的开源软件使用该模型的原因。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号