
图神经网络的预训练与自监督学习
图神经网络的预训练与自监督学习
图神经网络简史
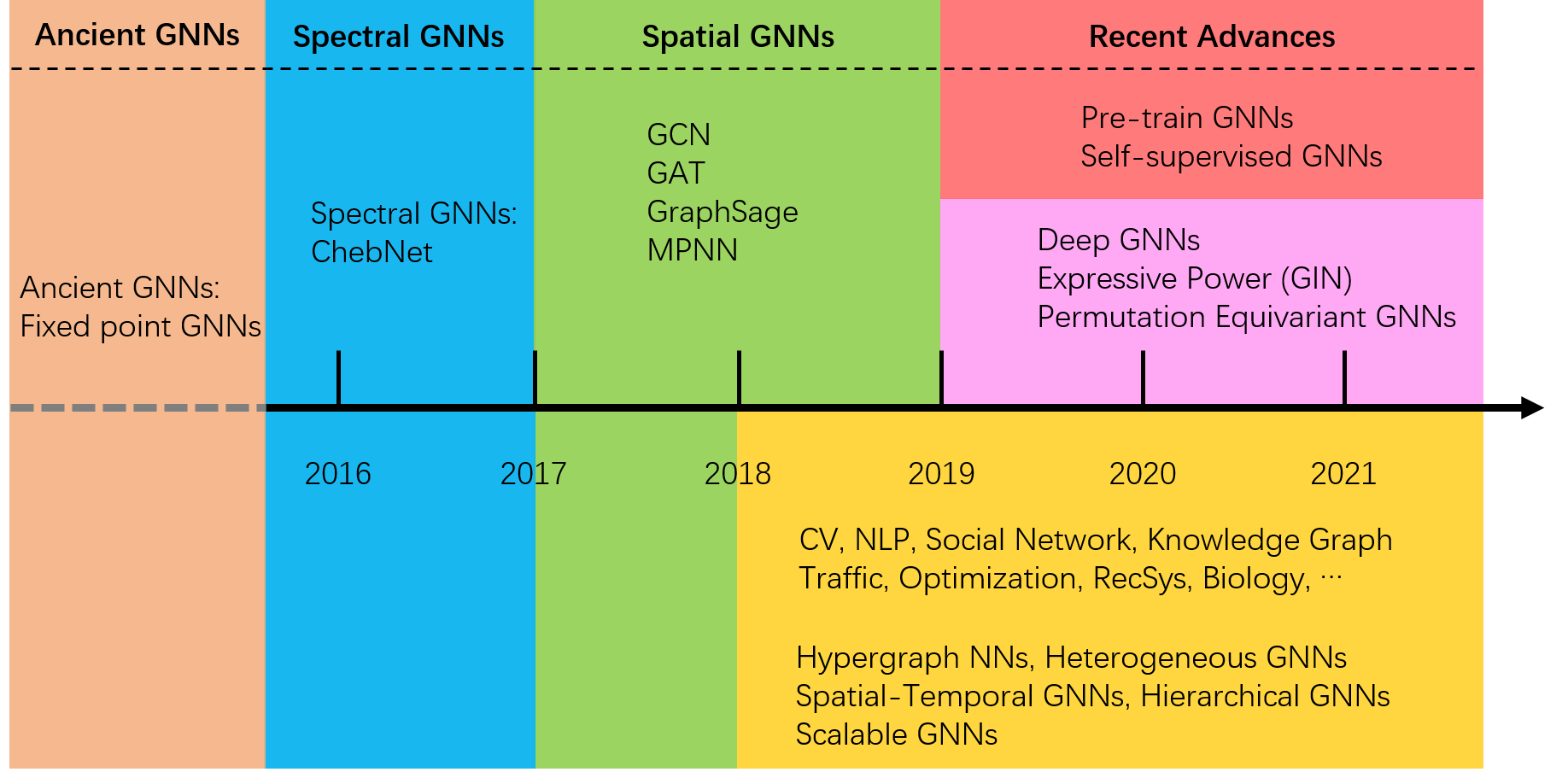
图神经网络(GNN)2005年发端于不动点迭代,2014-2016年引入傅里叶分析定义频域卷积(ChebNet)之后开始引人注目,2017-2018引入简单通用的空间卷积(GCN,GAT,GraphSage,MPNN)后一举掀起GNN研究的热潮,这一时期产生的空间域GNN也成为使用最广泛的GNN构建单元,2019年GNN被应用于计算机视觉、自然语言处理、社交网络分析、交通流预测等多个领域,交叉产生了超图GNN、时空GNN、异质GNN、层次GNN等多个子类,亦开发了面向大图的采样方法(FastGCN)。同时,为了进一步增强GNN处理大规模数据的能力,研究者开始探索深层GNN(DeepGCNs,JKNet),研究GNN的表达能力(GIN),并探索具有更强表达能力的置换不变GNN。至此,GNN已经具备了相对成熟的模型,相对成功的应用,但仍缺少泛用性强的GNN,因为当前GNN的应用仍囿于深度学习的经典范式——面向特定任务使用大量标注数据训练模型,当任务改变或标签不足时,GNN亦回天乏术。因此我们希望GNN具有知识迁移的能力,鉴于预训练模型在图像和语言领域取得的革命性的成功,预训练GNN呼之欲出,而这恰恰是2019年末到2021年初孕育的新的研究方向。
预训练GNN的前置条件
兴奋之余,我们禁不住要问,现阶段真的具备研究预训练GNN的条件吗,成功的预训练模型需要具备什么前置条件?以下是笔者自己的总结:
| 条件 | 图像 | 语言 | 图 |
|---|---|---|---|
| 可迁移的知识 | 纹理等 | 单词语义 | 子结构(存疑) |
| 大容量深层模型 | ResNet | Transformer | 尚未成熟 |
| 大量训练数据 | ImageNet | 维基百科 | 引用网络,分子网络 |
| 有效的训练方法 | 分类 | 自回归 | 自监督 |
表中仅列出代表性内容,不一定完整。对比分析可知,目前研究预训练GNN的条件尚未完全满足,如尚未明确图中什么知识是可迁移的,因为不同图的结构千差万别,而且目前深层GNN虽有研究但仍未带来革命性的提升。幸运的是,图机器学习社区已经积累了大规模的图数据,并且已经发展出诸如图重构的自监督训练方法。笔者认为,预训练GNN的研究恰逢其时,将来与深层GNN、表达能力更强的GNN等研究路线会合终可实现泛用性强的GNN。
自监督学习
前文提及自监督学习,但尚未解释其含义及其与预训练的联系,下面根据个人理解做简单的概念澄清。
| 概念 | 内涵 |
|---|---|
| 有监督 | 基于有标签数据训练 |
| 无监督 | 基于无标签数据训练 |
| 半监督 | 同时运用有标签和无标签数据训练 |
| 自监督 | 无监督训练的一种,模仿有监督方法构造伪标签 |
| 预训练 | 使用有监督和无监督方法均可 |
由表分析可知,有监督和无监督方法均可对模型进行预训练,考虑到实际情况标注数据少,而图本身有丰富的结构和属性信息可以提供监督信息,因此,自监督学习在图上大有可为。自监督学习是一个正在蓬勃发展的领域,当前主要有两大研究范式:基于重构的生成式方法,最大化正例对与负例对差异的对比学习。恰巧,对比学习也是图自监督学习研究最多成效最显著的一个技术路线。
另一方面,自监督学习其实是一种通用的学习方法,不限于预训练,但是两者有共通之处,以下试图将两者统一起来考虑。
预训练GNN的技术路线
笔者从预训练GNN和自监督GNN两方面收集文献。专门的预训练GNN论文尚少,如下表所示:
| 年份 | 会议 | 论文 | 贡献 |
|---|---|---|---|
| 2019 | ICLR | Strategies for Pre-training Graph Neural Networks | 首次提出预训练GNN,提出Attribute Masking和Context Prediction两种预训练方法 |
| 2020 | KDD | 1. GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training 2. GPT-GNN: Generative Pre-Training of Graph Neural Networks |
1. 基于ego network的对比学习 2. 基于边和属性重构的对比学习 |
| 2021 | AAAI | Learning to Pre-train Graph Neural Networks | 引入元学习缩小预训练和微调的差距,“边-边”和“图-图”的对比学习 |
自监督GNN的研究较多,选取近年较重要的文章如下
| 年份 | 会议 | 论文 | 贡献 |
|---|---|---|---|
| -2018 | Various | 1. Variational Graph Auto-Encoders 2. Inductive Representation Learning on Large Graphs |
1. 直接进行边重构 2. 基于边重构的对比学习 |
| 2019 | ICLR | Deep Graph Infomax | “子图表示-全图表示”的对比学习 |
| 2020 | ICLR | InfoGraph: Unsupervised and Semi-supervised Graph-Level Representation Learning via Mutual Information Maximization | “中间层图表示-末尾层图表示”的对比学习 |
| 2020 | ICML | 1. When Does Self-Supervision Help Graph Convolutional Networks? 2. Contrastive Multi-View Representation Learning on Graphs |
1. 实验指出多任务学习优于“预训练-微调”和自训练范式,提出节点聚类、图分割、图补全3种自监督任务 2. 基于子图采样的多视图对比学习,实验发现“节点-图”对比优于“图-图”对比和层级对比 |
| 2020 | NeurIPS | Graph Contrastive Learning with Augmentations | 基于图数据增强(节点/边的增/删,子图)的对比学习 |
| 2021 | AAAI | 1. Contrastive and Generative Graph Convolutional Networks for Graph Based Semi-supervised Learning 2. Contrastive Self-Supervised Learning for Graph Classification 3. Data Augmentation for Graph Neural Networks |
1. 局部卷积与层次卷积的对比学习 2. 基于图数据增强(节点/边的增/删)的对比学习,用Moco优化 3. 重构GAE的输出 |
从上面文献可以看出预训练/自监督的关键在于定义自监督任务,主流为对比学习(阅读文献细节可知,很多参考了图像领域的对比学习方法),而对比学习的关键在于正例对和负例对的构造,以下总结了目前的构造方法:
| 级别 | 方法 |
|---|---|
| 节点 | 1. 属性遮掩 (Attribute Masking) 2. 属性删除 3. 属性置换 |
| 边 | 增/删 |
| 子图 | 1. 子图采样 2. ego network 3. 图粗粒化(Graph Coarsening) |
| 全图 | 增/删节点/边 |
通过节点、边、子图、全图的排列组合,可以定义多种多样的对比学习任务。
定义了正例对和负例对之后,一般用互信息衡量相似性,
因为涉及条件概率\(p(x|y)\)互信息难以计算,产生了一系列的估计子,如MINE,infoNCE,两者均被证明为互信息的下界,通过最大化下界限间接优化互信息。infoNCE的表达式如下
其中\(f_\theta\)为似然比\(\frac{p(x|y)}{p(x)}\)的神经网络估计子。形式上看,损失函数的每一项包含1各正例和\(K\)个负例,与网络嵌入中的负采样有异曲同工之妙
未来展望
可以看到,当前受对比学习启发,预训练/自监督GNN已经有了相当进展,但应该注意到,目前的自监督任务定义均比较直观,如果图重构等,缺少对图的子结构的探索。图自监督学习将进入深水区,基于图论和经典图数据分析定义新的自监督任务,学习更多的可迁移知识。目前已经有ICLR 2021投稿论文探索了基于motif的预训练方法,不过很不幸被拒了。此外,深层GNN和GNN表达能力方面的探索也值得期待。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号