【scarpy】实战:关于正则匹配rule,个人躺坑小记
最近研究scarpy框架,尝试用到rule正则匹配模式
参考:https://my.oschina.net/u/2340880/blog/403508
比如我要匹配前1-9页数据
http://www.uzaobao.com/plus/list.php?tid=17&TotalResult=6270&PageNo=4
输入start_url: http://www.uzaobao.com/plus/list.php?tid=17&TotalResult=6270&PageNo=1
通过rule自动匹配下一页
第一次:
r'uzaobao.com/plus/list.php\?tid=17&PageNo=\d'
尽管没有TotalResult参数,也能访问网页,
但是scrapy rule不这么认为,偏偏傻傻地匹配不到,即使后面follow=true也没效果。
第二次:
r'uzaobao.com/plus/list.php\?tid=17&TotalResult=\d+&PageNo=\d'
结果把http://www.uzaobao.com/plus/list.php?tid=17&TotalResult=6270&PageNo=13匹配出来,还是有问题
第三次:
r'uzaobao.com/plus/list.php\?tid=17&TotalResult=\d+&PageNo=(\d{1})'
同第二次,匹配两位数
查询需要非贪婪模式
第四次:
r'uzaobao.com/plus/list.php\?tid=17&TotalResult=\d+&PageNo=(\d{1}?)'
失败
参考在线正则表达式测试:https://tool.oschina.net/regex/
有了这个可以省去看代码时间,专注正则

最后使出杀手锏[^0-9]
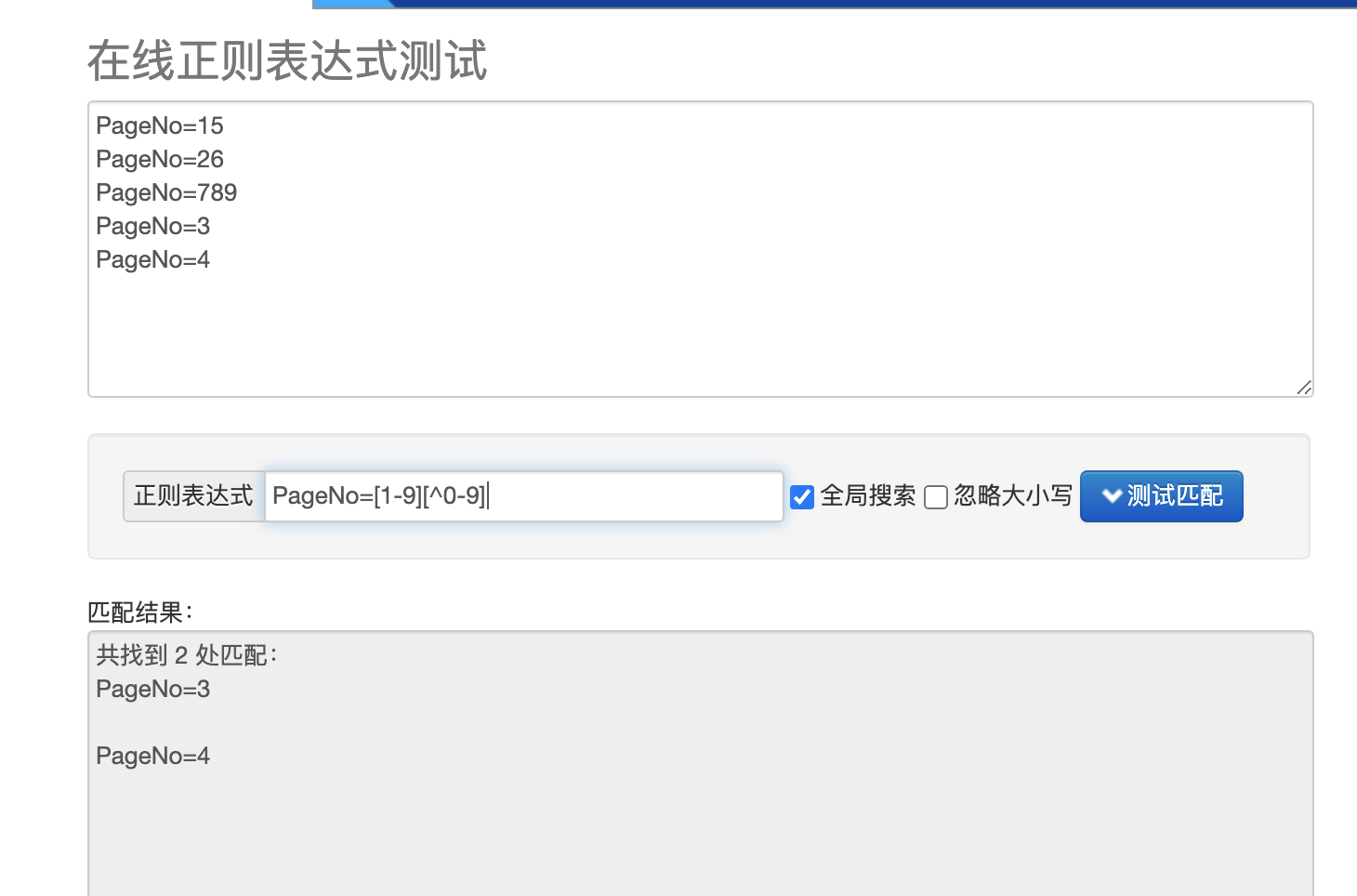
当然这样也可以
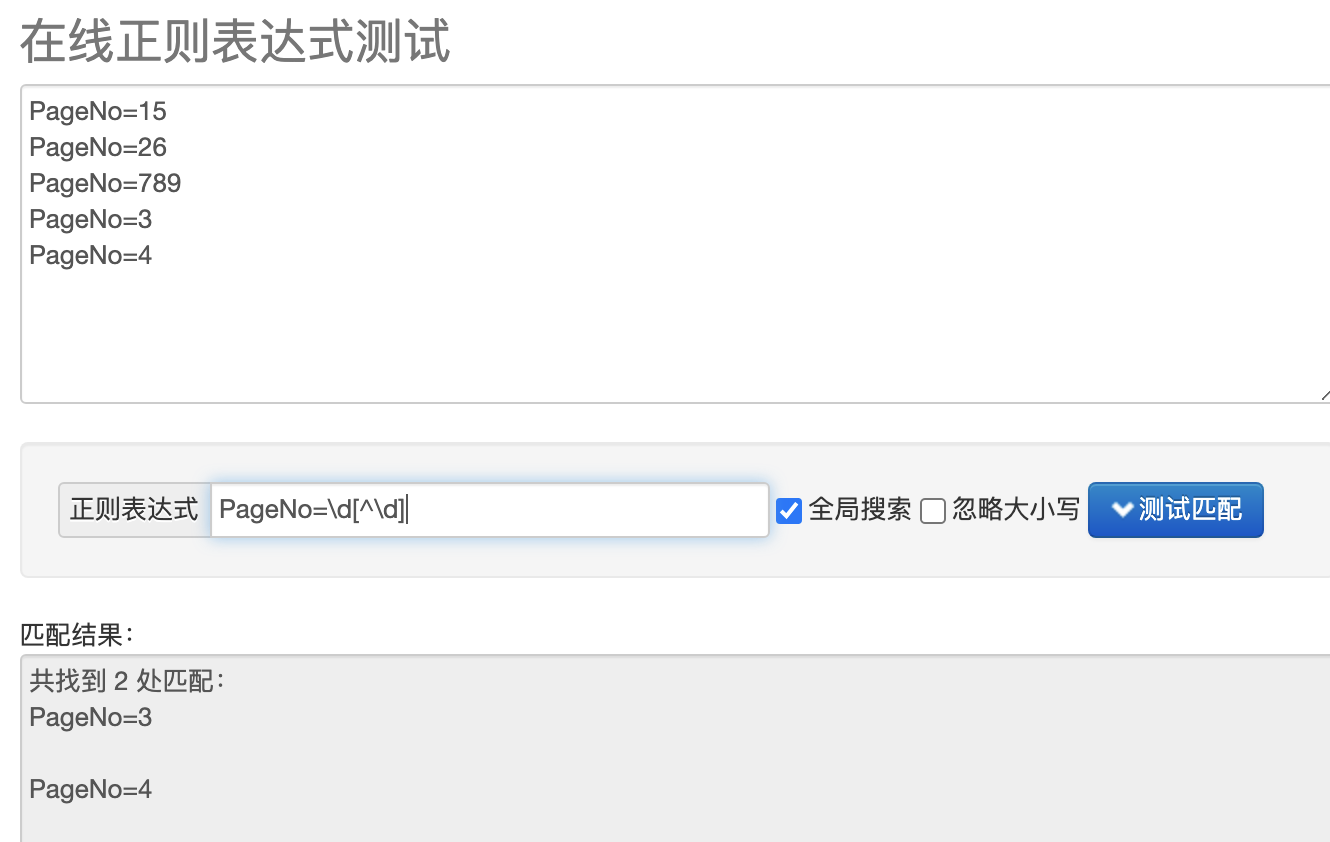
最后整理代码
r'uzaobao.com/plus/list.php\?tid=17&TotalResult=\d+&PageNo=\d[^\d]'
----20200706更新------
拓展到实例
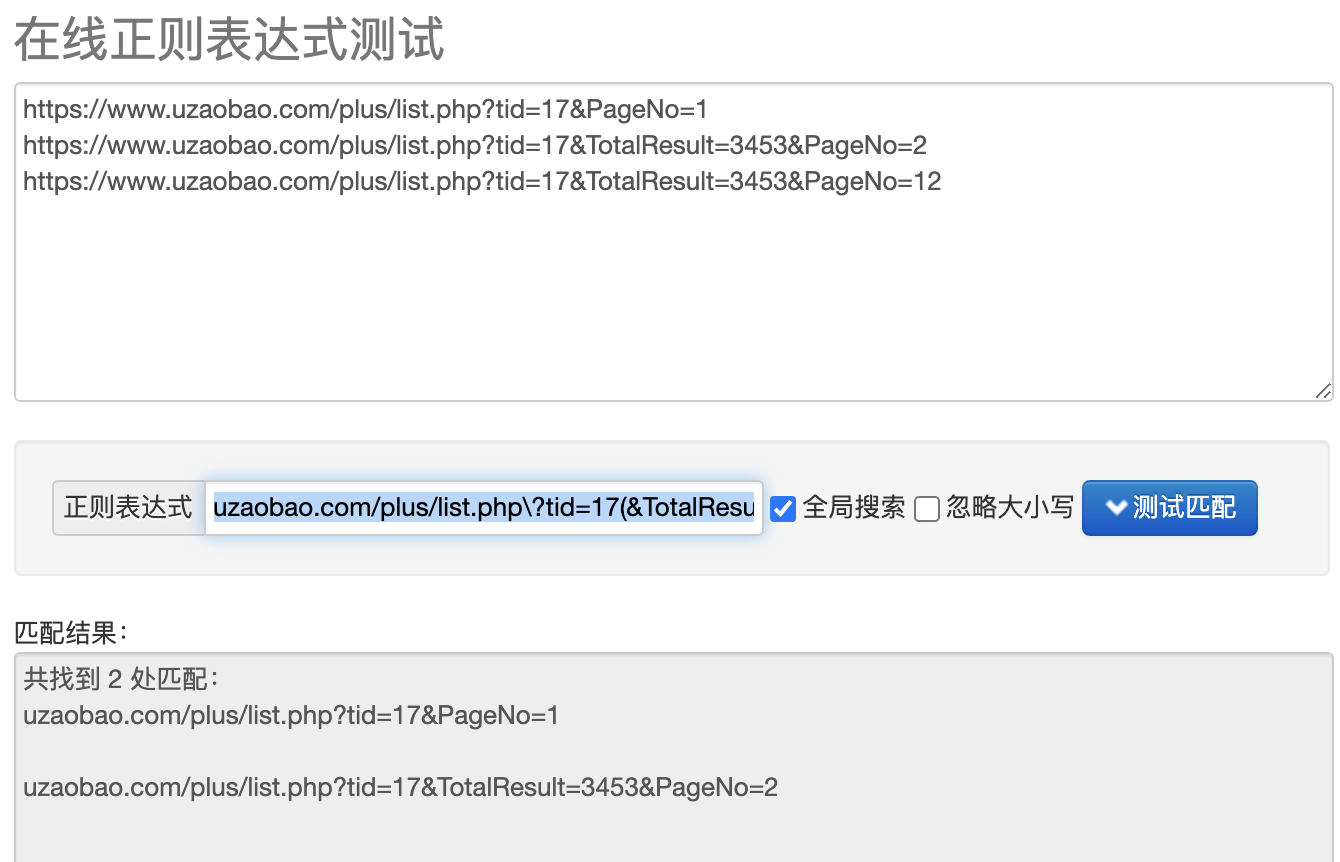
最终代码又变难了
r'uzaobao.com/plus/list.php\?tid=17(&TotalResult=\d+)*&PageNo=\d[^\d]'
-------------------------------
********厚德达理,励志勤工********
-------------------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号