d2l-seq2seq和束搜索
1. seq2seq
seq2seq是一个编码器-解码器架构:
- 编码器是一个RNN,读取输入句子(可以是双向)
- 解码器是另一个RNN来输出
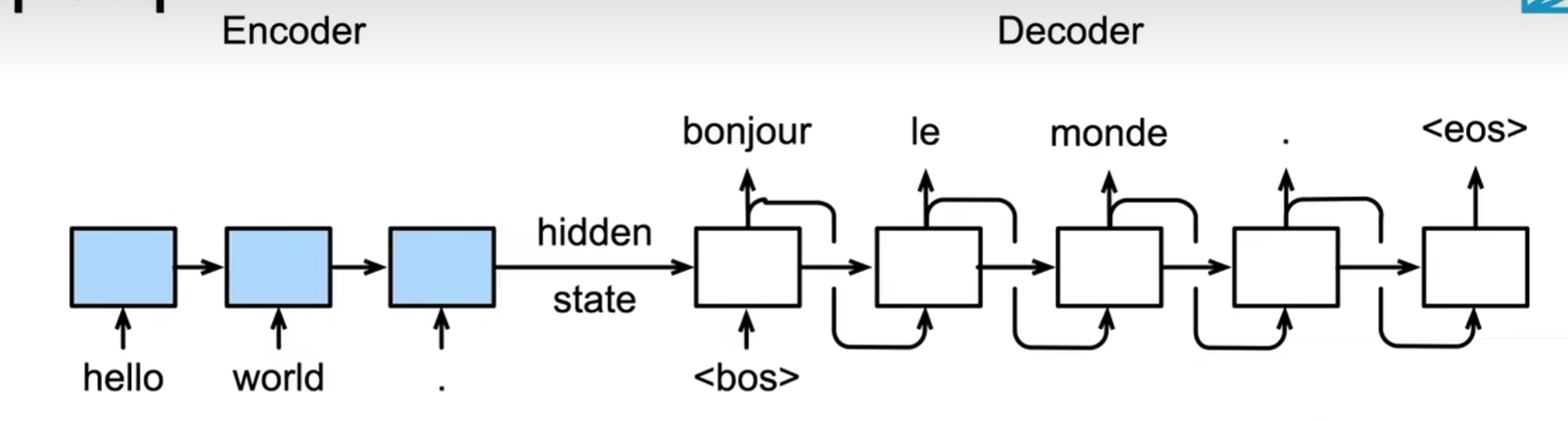
编码器
class Seq2SeqEncoder(d2l.Encoder):
"""用于序列到序列学习的循环神经网络编码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
# 嵌入层
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers,
dropout=dropout)
def forward(self, X, *args):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X)
# 在循环神经网络模型中,第一个轴对应于时间步
X = X.permute(1, 0, 2)
# 如果未提及状态,则默认为0
output, state = self.rnn(X)
# output的形状:(num_steps,batch_size,num_hiddens)
# state的形状:(num_layers,batch_size,num_hiddens)
return output, state
解码器
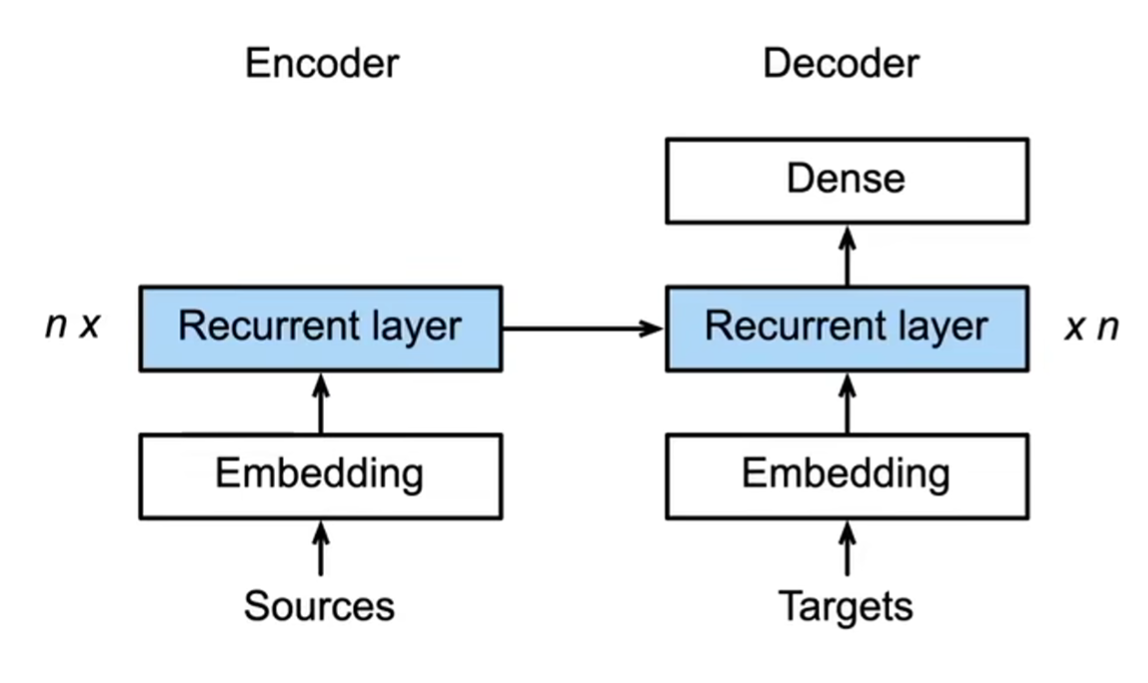
- 编码器是没有输出的RNN(没有全连接层)
- 编码器最后时间步的隐状态用作解码器的初始隐状态
class Seq2SeqDecoder(d2l.Decoder):
"""用于序列到序列学习的循环神经网络解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
# 使用编码器的隐状态来进行初始化
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, X, state):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X).permute(1, 0, 2)
# 广播context,使其具有与X相同的num_steps
context = state[-1].repeat(X.shape[0], 1, 1)
# concat 拼接操作
X_and_context = torch.cat((X, context), 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).permute(1, 0, 2)
# output的形状:(batch_size,num_steps,vocab_size)
# state的形状:(num_layers,batch_size,num_hiddens)
return output, state
带掩码的损失函数
因为在获得训练数据时,我们将长句子截断,将短句子进行填充。
所以,在计算损失函数的时候,应该将填充词元的预测排除在外。
可以通过sequence_mask函数通过零值化屏蔽不相关的项。
def sequence_mask(X, valid_len, value=0):
"""在序列中屏蔽不相关的项"""
maxlen = X.size(1)
mask = torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return X
X = torch.tensor([[1, 2, 3], [4, 5, 6]])
sequence_mask(X, torch.tensor([1, 2]))
# tensor([[1, 0, 0],
# [4, 5, 0]])
#@save
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
"""带遮蔽的softmax交叉熵损失函数"""
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label)
weights = sequence_mask(weights, valid_len)
self.reduction='none'
unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(
pred.permute(0, 2, 1), label)
weighted_loss = (unweighted_loss * weights).mean(dim=1)
return weighted_loss
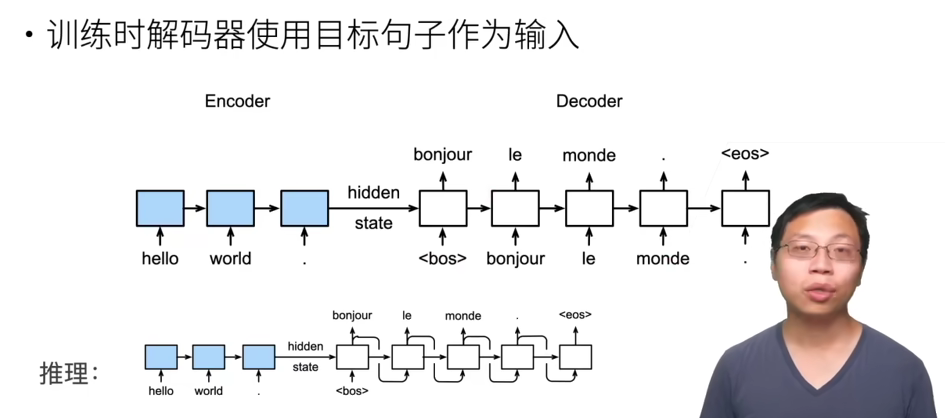
训练和推理的行为
训练和推理时解码器的行为是不同的:
- 训练时,解码器有目标句子作为输入
衡量生成序列好坏的指标 BLEU:
- 标签序列ABCDEF和预测序列ABBCD,有
- BLEU对长匹配有高权重
- BLEU 越大越好,完美是1。
2. 束搜索
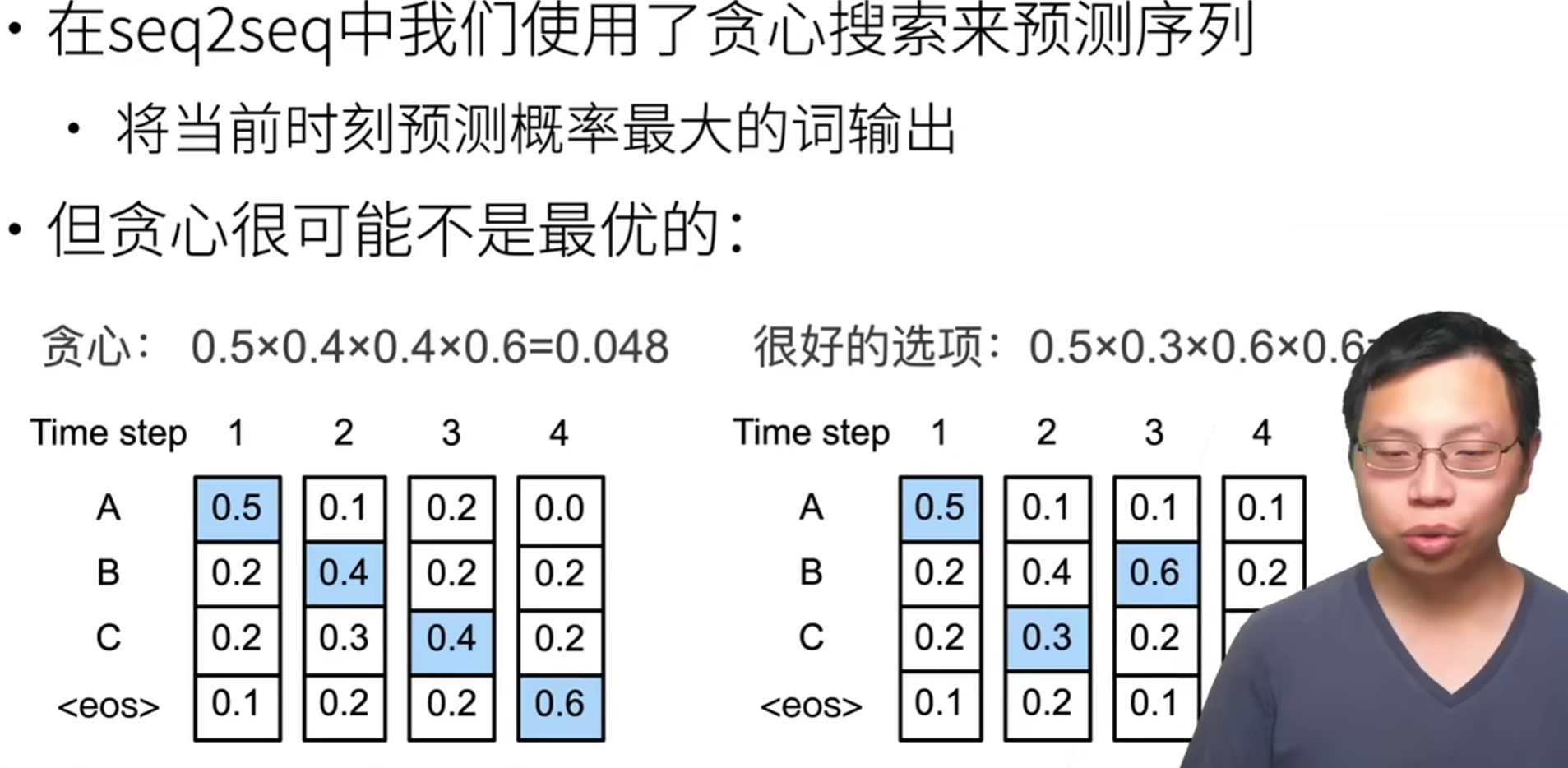
逐个预测输出休了,指导预测序列中出现<eos>(end of sentence)。
首先介绍的是贪心搜索,每次都选择具有最大条件概率的下一个词元。
然而,贪心搜索不能够保证得到的是最优解。
穷举搜索:对所有可能的序列,计算概率,然后选择最好的那个。
- 计算复杂度过大:
- 输出字典大小为
- 序列长度为
- 则需要考察
- 输出字典大小为
束搜索:保存最好的k个候选,每次都从
- 复杂度为
- 束搜索是贪心搜索和穷举法之间的折中。
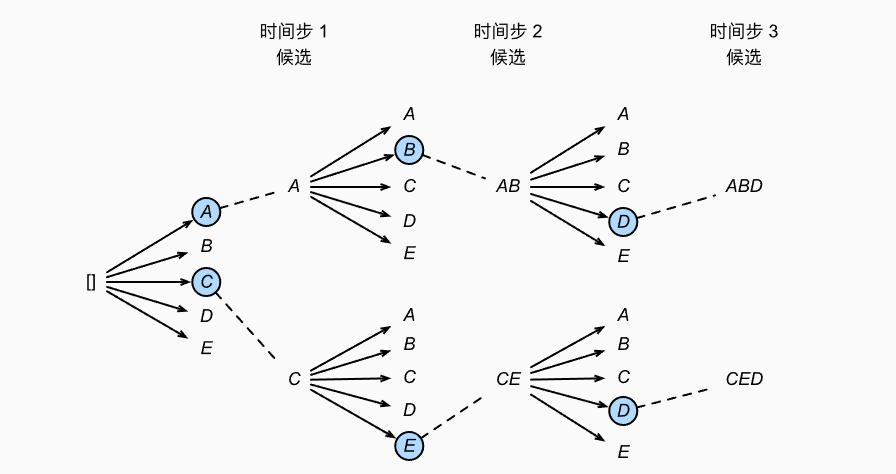
如上图所示,最终得到6个序列:A, C, AB, CE, ABD, CED
最后通过,如下公式,从候选集合中选择最终的输出序列:
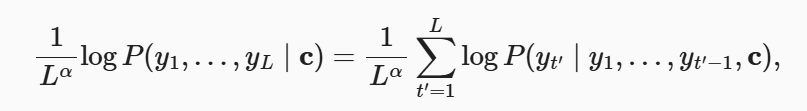


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律