d2l-现代循环神经网络
1. 深层循环神经网络
之前介绍的循环神经网络都只有一个单向隐藏层。
我们可以通过添加更多的层,引入更多的非线性,增大模型的复杂度。
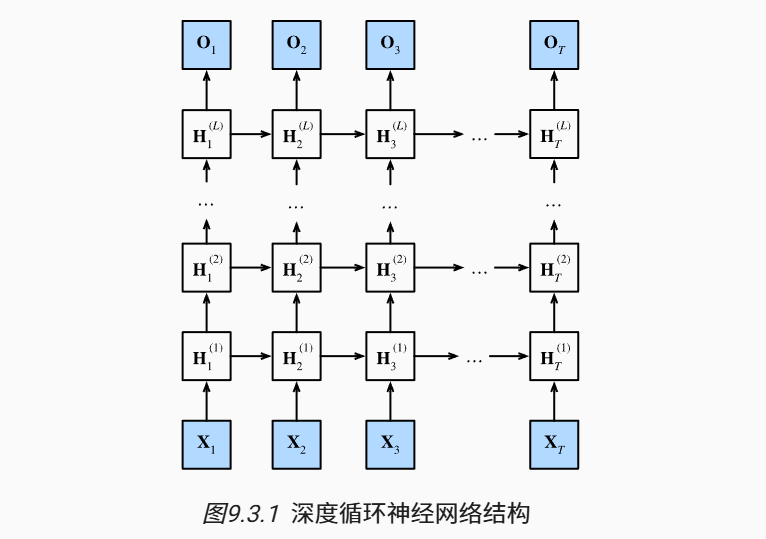
上图描述了一个具有L个隐藏层的深度循环神经网络,每个隐状态都连续地传递到:
- 当前层的下一个时间步
- 下一层的当前时间步
- 在Pytorch中只需指定
num_layers,即可增加循环神经网络中的隐藏层。 - RNN、GRU、LSTM等模型,都可以设计成深层模型。
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
device = d2l.try_gpu()
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
2. 双向循环神经网络
之前的循环神经网络只考虑了过去的历史信息(即,上文),而没有考虑下文。
事实上,下文也传达了重要的信息。例如:
- 我___。
- 我___饿了。
- 我___饿了,我可以吃半头猪。

不适用:双向循环神经网络不好做推理、预测,因为无法获知后面的内容/未来
适用:对序列抽取特征、填空,词元注释(例如,用于命名实体识别)
由于梯度链更长,双向循环神经网络的训练代价非常高。
import torch
from torch import nn
from d2l import torch as d2l
# 加载数据
batch_size, num_steps, device = 32, 35, d2l.try_gpu()
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 通过设置“bidirective=True”来定义双向LSTM模型
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers, bidirectional=True)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
# 训练模型
num_epochs, lr = 500, 1
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
3. 机器翻译与数据集
语言模型是自然语言处理的关键,而机器翻译是语言模型最成功的基准测试。
因为及其翻译是将 输入序列 转换成 输出序列的序列转换模型 (sequence transduction)的核心问题。
- 机器翻译是指将序列从一种语言自动翻译成另一种语言。
- 机器翻译的数据集是由源语言和目标语言的文本序列对组成的。
- 通常用单词作为token。为了防止vocab过大,可以将低频token视为相同的未知词元。
- 通过截断和填充文本序列,可以保证所有的文本序列都具有相同的长度,一边以小批量的方式加载数据。
4. 编码器-解码器架构
编码器-解码器(Encoder-Decoder)是一种模型架构。
一个模型被分为两块:编码起处理输入;解码器生成输出。
在机器翻译任务种,编码器-解码器的作用如下:
- 编码器:它接收一个长度可变的序列作为输入,将其转换为具有固定形状的编码状态
- 解码器:它将固定形状的编码装填映射到长度可变的序列



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)