d2l-现代卷积神经网络
1. 使用块的神经网络 (VGG)
AlexNet加深神经网络得到了良好的效果,但是没有提供一个通用的神经网络设计模板。
类似于芯片设计中从基本原件到逻辑块,神经网络的设计也可以从 单层 到 块/重复层。
基本思想:使用 可重复使用的卷积块 来构建神经网络。
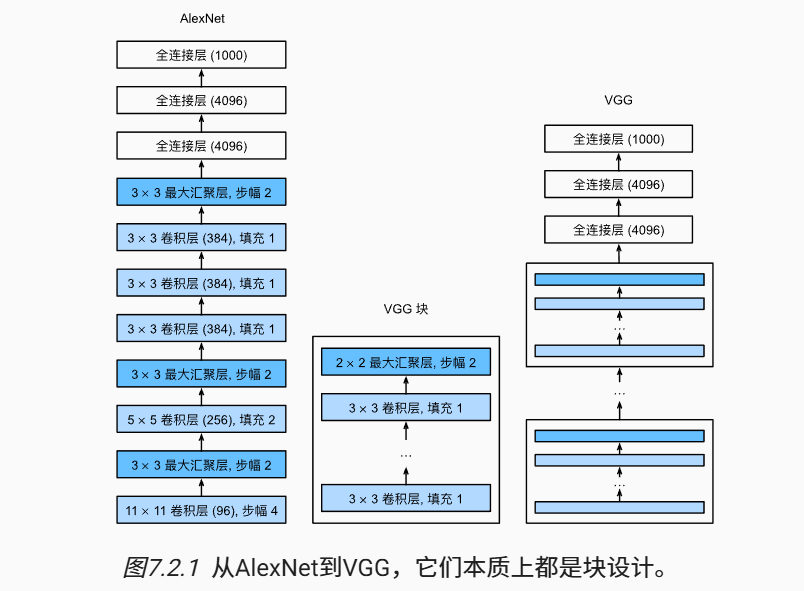
VGG中的卷积层为 3*3, 1层padding。
根据计算公式 h - 3 + 1*2 + 1 = h,经过卷积层图片尺寸不变。
经过 最大池化层 后图片的尺寸缩小一半。
import torch
from torch import nn
from d2l import torch as d2l
# in_channel, out_channel 为输入通道数和输出通道数
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
net = vgg(conv_arch)
2. 网络中的网络 NiN
一个NiN块由 3个部分组成:1个卷积层 + 2个 1*1 的卷积层
11 的卷积层相当于全连接层的作用,但是可以改变通道数。
NiN 和 AlexNet、VGG 相比 参数更少,不容易过拟合(因为用11的卷积层和全局平均池化层替代了全连接层)。
import torch
from torch import nn
from d2l import torch as d2l
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2),
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
# 将四维的输出转成二维的输出,其形状为(批量大小,10)
nn.Flatten())
3. 含并行连结的网络 GoogLeNet
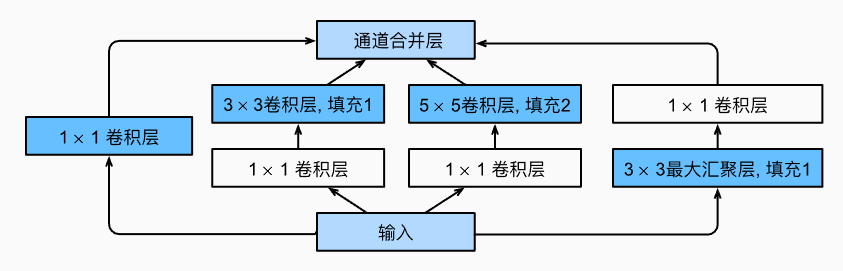
GoogLeNet 中的基本块被称为 Inception 块
- Inception 块 是由
4条并行路径组成,能够识别不同范围的图像细节。 - 每条路径都添加了适当的填充使得输入输出的尺寸不变,通道数改变
- 跟单 3*3 或 5*5 卷积层比,Inception 块的参数量少,计算复杂度低
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
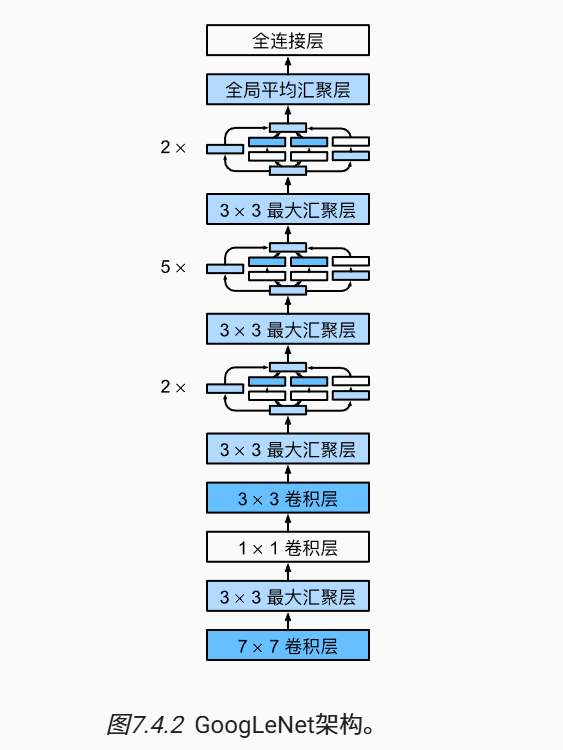
- GoogLeNet 包含了 5个stage,9个Inception块
- 1个stage 指的是 图像的高宽减半
4. 批量归一化 Batch Normalization
深度学习中存在的问题:
- 后面的层接近损失函数,更新速度快;前面的层更新慢。
- 前面的层发生改变时,后面的层也需要更新(之前白学了),导致收敛慢。
为了加速收敛,使训练过程更加稳定,提出了批量归一化 Batch Normalization。公式如下:

BN的位置:
- 全连接层和卷积层输出上,在激活函数前
- 全连接层和卷积层输入上
BN有效的原因:
随机性- 随机性往往能够加速收敛,缓解过拟合等问题,可以视为某种形式的正则化


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律