论文阅读-Causality Inspired Framework for Model Interpretation
标题:A Causality Inspired Framework for Model Interpretation
关键词:自然语言处理,因果推理,可解释机器学习
论文链接:https://dl.acm.org/doi/pdf/10.1145/3580305.3599240
会议:KDD
1. 简介
解释(explanation) 能否揭示 模型表现的根本原因(root cause)是XAI的重要问题。
文章提出了Causality Inspired Model Interpreter (CIMI),一种基于因果推理的解释器。
- 在XAI中 变量集合(a set of variables)可以作为模型预测的可能原因(possible causes),如果其满足因果充分性假设(causal sufficiency assumption)。
- 核心问题:如何有效地 发现突出的共同原因(prominent common causes),并能从大量特征和数据点推广到不同实例(泛化性generalizability)。
2. 因果图
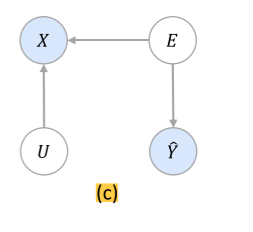
- X:输入实例
- E:模型预测的泛化因果解释(generalized causal explanation for predeiction)
- U:非解释部分(non-explanation)
- \(\hat{Y}\):预测结果
- \(M\):掩码,和X作运算之后能得到E
- \(g(.)\):解释器Interpreter.
\(g(X) = E\)
\(E = M \odot X\)
\(U = (1-M) \odot X\)
\(\odot\)是逐元素乘法,\(M_i\in[0,1]\) 表示特征对输出的贡献。
3. 框架结构
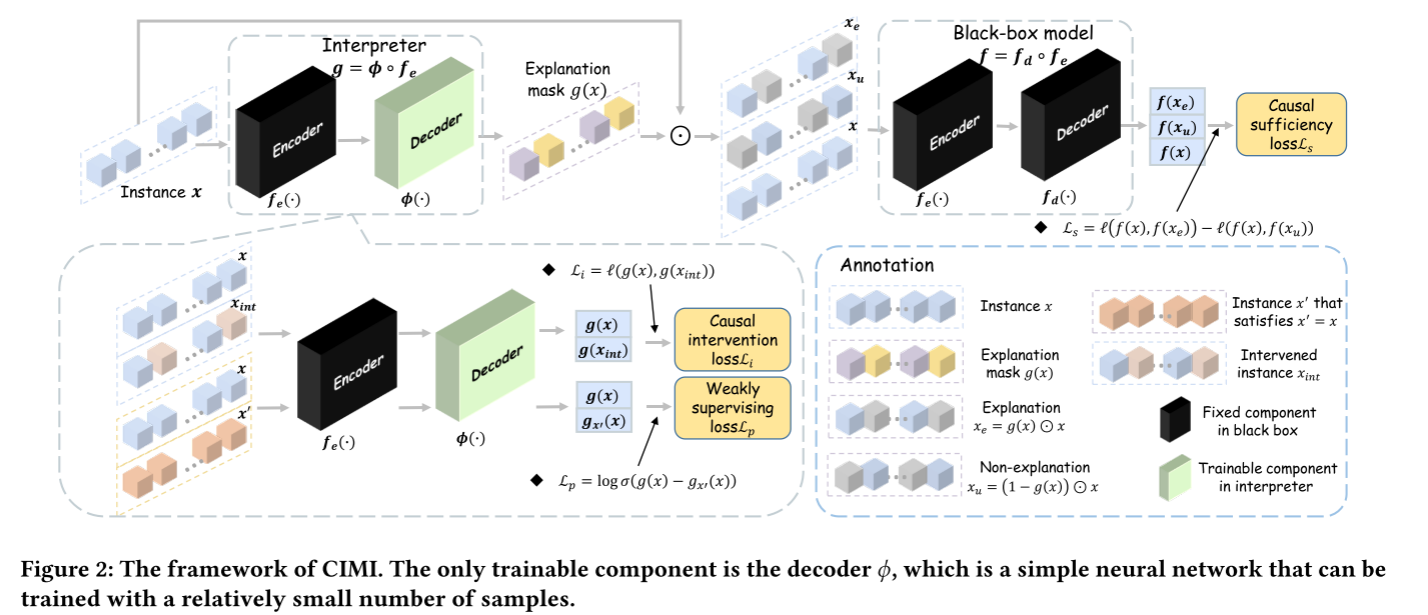
解释器 Interpreter \(g(.)\)由 encoder \(f_e(.)\) 和 decoder \(\phi(.)\)组成
\(f_e(.)\)是预训练模型Bert的encoder
\(\phi(.)\)是唯一可以训练的模型,由1层LSTM和2层MLP组成。
- 1-layer LSTM: hidden size is 64
- 2-layers MLP: 64 × 16, 16 × 2
\(g(x) = \phi([f_e(x);v_x]_1)\)
- \([f_e(x); v_x]_1\)表示Bert编码器 和 词嵌入\(v_x\)在axis 1上作连接操作。
- \(d\): 嵌入(embedding)的维度
- $\phi(.): $$R^{|x| \times 2d} \rightarrow [0,1]^{|x| \times 1}$
- 输出第i维度的值:token i 被选中作为解释的概率
信息瓶颈理论:infomation bottleneck theory 在前向传播过程中,神经网络会逐渐专注于输入中最重要的部分,过滤掉不重要的部分。(信息量是逐渐衰减的)
黑盒模型的编码器\(f_e(x)\)能够通过已经训练好的模型过滤掉一部分噪音。
4. 损失函数
1. causal sufficiency loss
\(x_e\)的部分对于预测\(f(x)\)的结果已经足够(sufficient)了,\(x_u\)对于预测没有帮助。
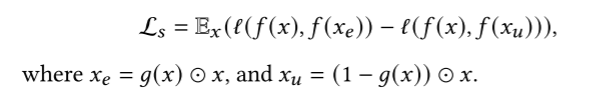
2. causal intervention loss
对非解释部分进行线性插值,不会影响解释的生成。\(g(X) = E\)。
\(x'\)是从\(X\)中随机抽样得到。
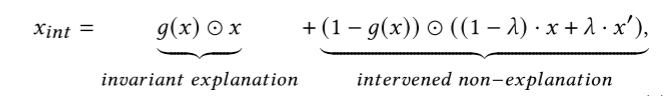
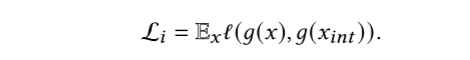
3. weakly supervised loss
为了防止生成平凡解(包含所有token的解),设置了此弱监督损失。
- 最大化实例x中的 token 被包括在解释\(x_e\)中的概率(maximizing the probability that the token in instance 𝑥 is included in 𝑥𝑒)
- 最小化不在x中的token(噪音)被预测为解释的概率(minimizing the probability that a token not in 𝑥 (noise) is predicted to be the explanation)
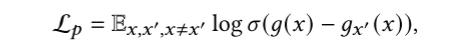
5. 实验
5.1 评价指标
1. causul sufficiency(3个)
- Decison Flip-Fraction of Tokens (DFFOT):改变模型预测所需要修改重要token的最小部分(minimum fraction)(越小越好)

- Comprehensiveness (COMP):移除important token,原预测类的概率变化量(越大越好)
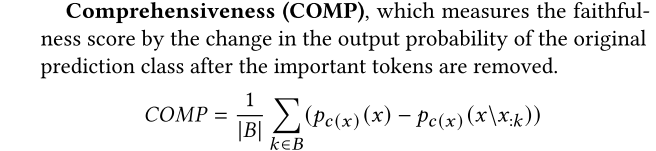
- Sufficiency (SUFF):只保留import token,原预测类的概率变化量(越小越好)
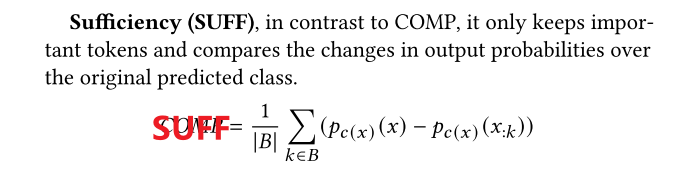
2. explanation generalizability(1个)
- Average Sensitivity (AvgSen):当输入被扰动时,一个解释的平均敏感度。(在实验中对每个实例替换5个token,并计算top-10 important token的敏感度)。
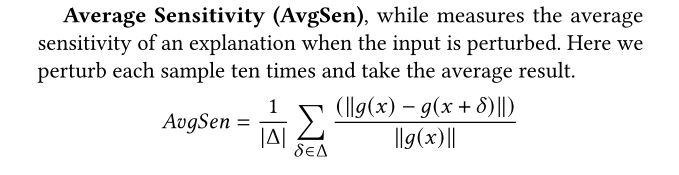
5.2 Faithfulness Comparison
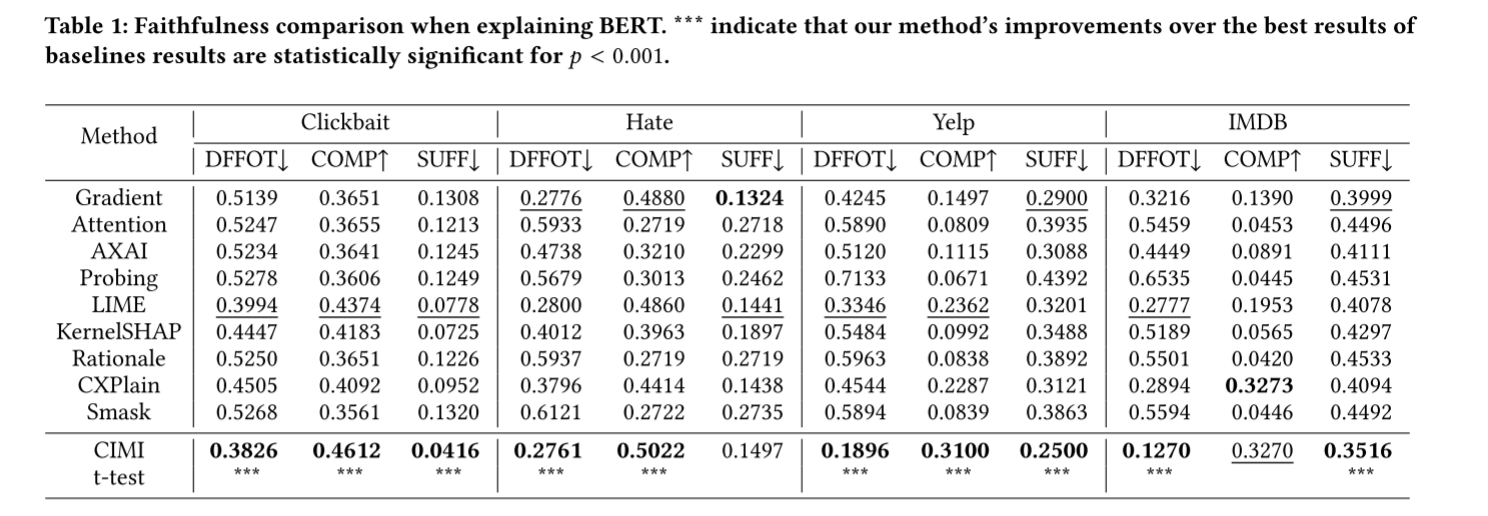
- 测量不同方法的3个指标
- 计算CIMI方法是否有显著提升
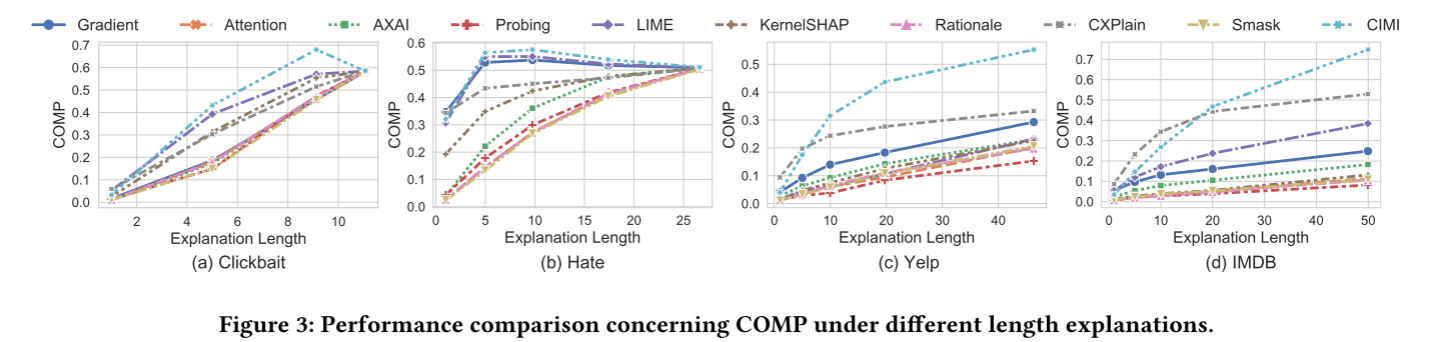
不同解释长度下的COMP指标的比较
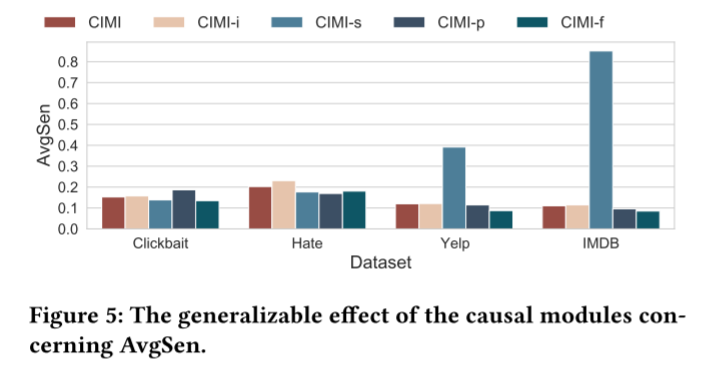
5.3 Generalizability Comparison
用AvgSen作为衡量泛化能力的指标
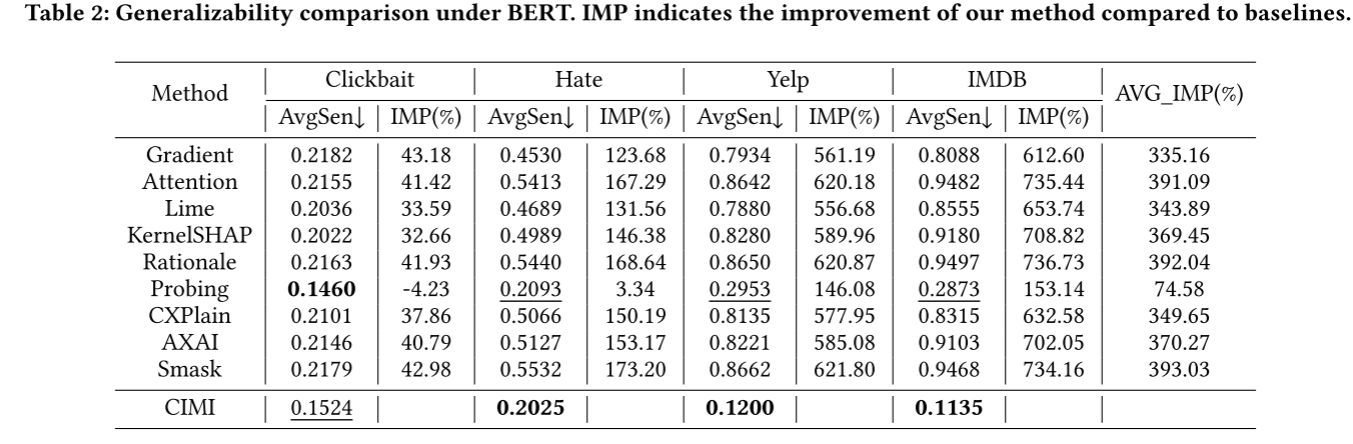
在4个数据集上CIMI的top-10 token中有8个能保持一致,说明该方法能够抓住具有不变的泛化特征(invariant generalizable features)。
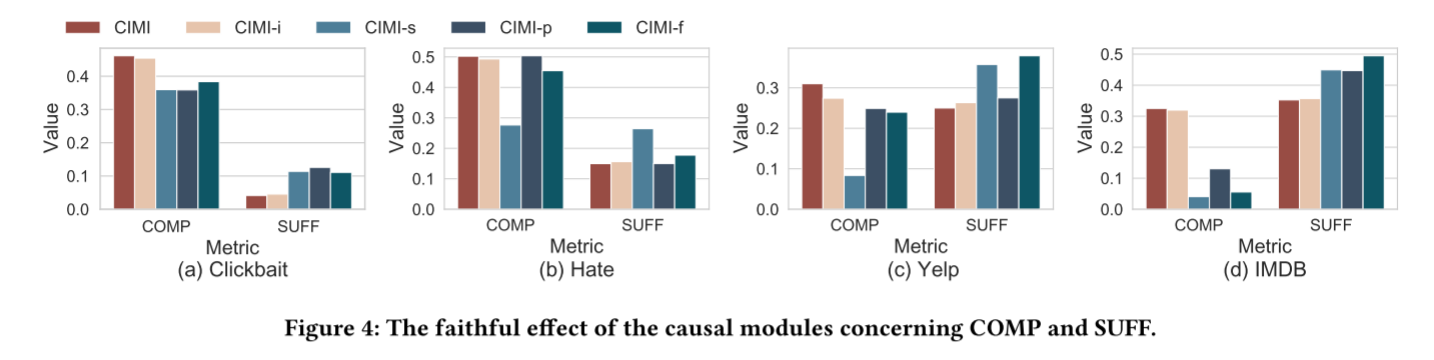
5.4 消融实验
尝试移除不同的模块,观察模型表现的变化,进而证明模型设计理念的正确性。
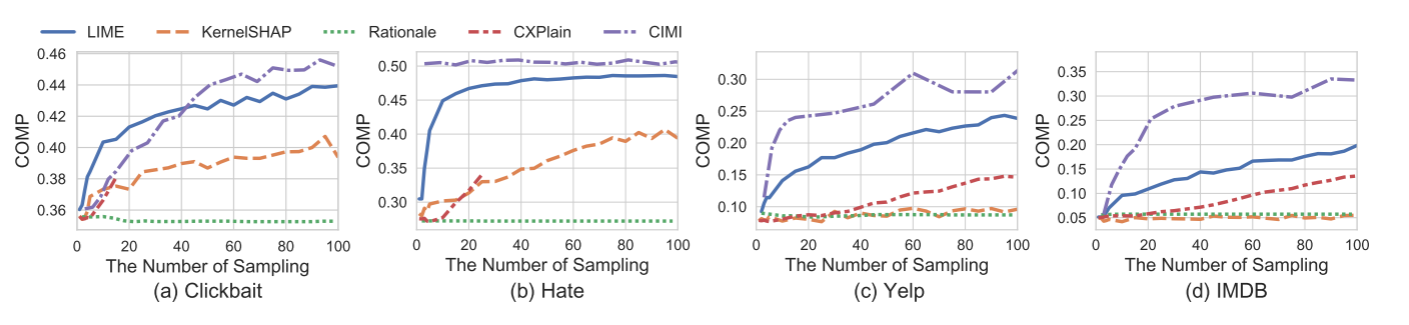
5.5 采样效率(Sampling Efficiency)
用 各种基于扰动的方法 在 相同前向传播次数下 的表现来衡量 采样效率。
5.6 不同离散化策略的表现
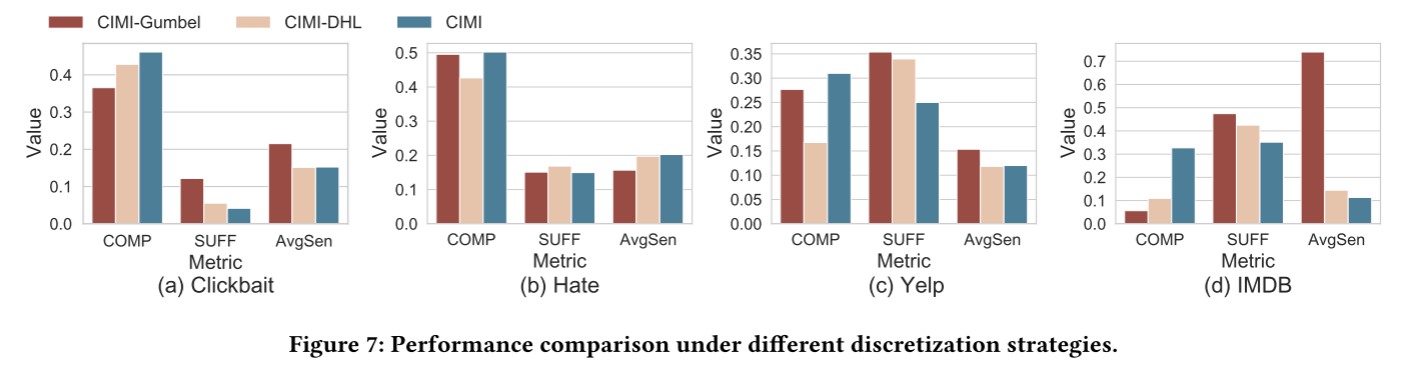
原来的方法采用的是可微的Softmax,本实验尝试将其替换为 Gumbel-Softmax 和 Deep Hash Learning 两个离散函数。
离散化的掩码能够提高解释的泛化能力,但是以模型表现下降为代价。
5.7 Usefulness Evaluation 模型排错
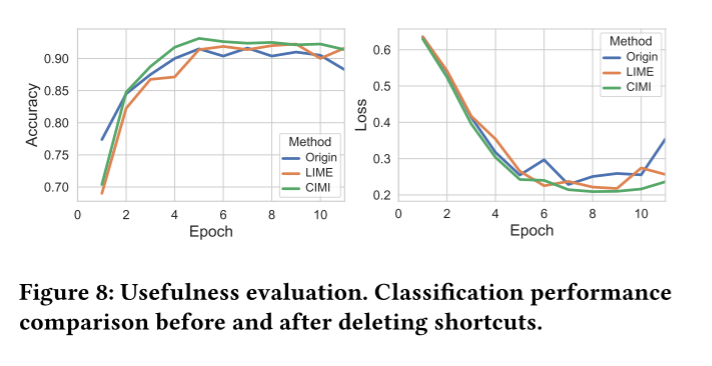
利用模型生成的解释剔除shortcut features。在CIMI debugging 之后模型表现是最好的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号