论文阅读-Self-supervised and Interpretable Data Cleaning with Sequence Generative Adversarial Networks
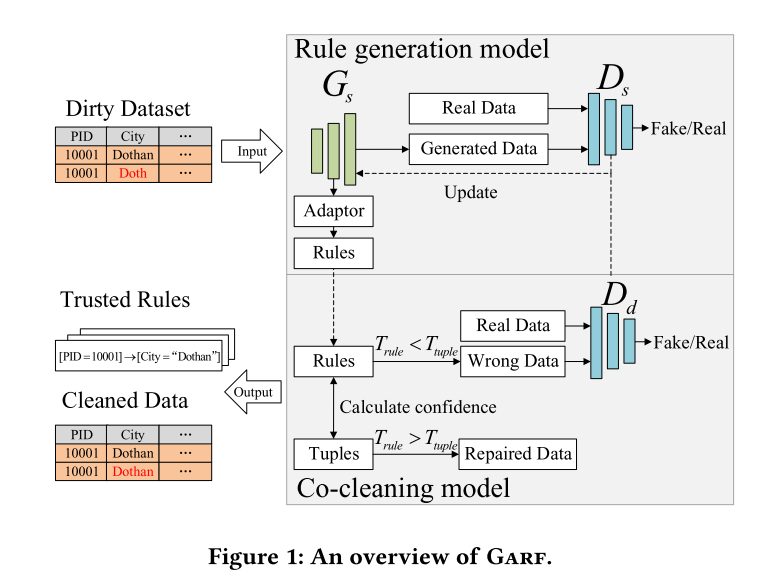
1. GARF 简介
代码地址:https://github.com/PJinfeng/Garf-master
基于 SeqGAN 提出了一种自监督、数据驱动的数据清洗框架——GARF。
GARF 的数据清洗分为两个步骤:
- 规则生成 (Rule generation with SeqGAN):利用 SeqGAN 学习数据中的关系 (data relationship)。然后利用 SeqGAN 中的 genarator 生成用于数据清洗的规则 rules。
- 协同清洗 (Co-cleaning):第1步中的部分规则可能是基于脏数据得到的不可信规则。在第2步中分别计算 数据 (data) 和 规则 (rules) 的可信度,
- 若数据更可信,则使用数据来更新规则
- 若规则更可信,则使用规则来更新数据
2. 规则生成
2.1 训练SeqGAN
GAN 在图像领域有良好的表现,但是处理离散数据生成时表现不佳。
SeqGAN 利用了强化学习 (Reinforcement Learning)的优点解决了离散值生成的问题。
将本文中的问题转化为SeqGAN中的概念:
- 相关属性值 作为 上下文 (context)
- 数据集 作为 全集/语料库 (corpus)
- 元组\((v_1,v_2,...,v_n)\) 作为 数据集D中的一组值序列 (value sequence)

2.2 生成数据修复规则
为了将 SeqGAN 学习到的知识以可解释的方式展现, 使用 adaptor 将关系转化为规则 (rules)。
规则形式:\([AL, v (AL)] → [AL, v (AR)]\)
其中, \(AL\), \(AR\)为属性名称,\(v (AL)\), \(v (AR)\)为属性的值
SeqGAN 中的生成器 \(G_s\) 的输入作为 \(AV_L\),预测结果作为 \(AV_R\) 。
先将第\(i\)个属性键值对确定为 \(AV_R\) ,然后从 \(i-1\) 到 \(1\) 依次添加属性作为\(AV_L\),直到 \(G_s\) 的预测结果为 \(AV_R\)。

2.3 数据修复规则优化
优化的两个操作
- 去除匹配元组数小于2的规则
- 去除规则左侧冗余属性

3. 协同清洗错误规则和脏数据

3.1 置信度计算
使用 SeqGAN 训练并提取得到的规则可能是不准确的。
因此论文动态计算 数据 和 规则的置信度。基于置信度高的一方来更新另一方,即
- 若数据置信度高,则使用数据来更新规则
- 若规则置信度高,则使用规则来更新数据
-
数据/元组的置信度计算
元组的表示形式:\(𝑡 = (AV_1, . . . , AV_i, . . . , AV_n)\)

-
规则的置信度计算
无论是 trusted tuple 违反规则 还是 untrusted tuple 违反规则。规则的置信度\(T_r\)都会受到惩罚。
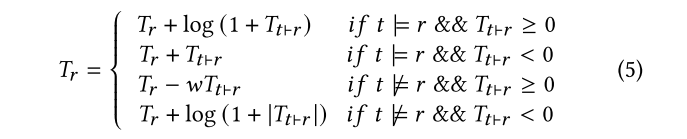
3.2 基于置信度清洗规则或数据
3.2.1 规则更可信 修复数据
需要根据规则修改元组数据。元组中出错的可能是规则左侧的属性\(AV_L\),也可能是规则右侧的属性\(AV_R\)。分别计算 左右两侧的属性置信度,更新置信度小一侧的属性值。
- \(𝑇_{𝐿𝐻𝑆} = min (𝑇_𝑡 (𝐴𝑉_𝑖 )) , 𝐴𝑉_𝑖 ⊆ 𝐴𝑉_𝐿\)
- \(𝑇_{𝑅𝐻𝑆} = 𝑇_𝑡 (𝐴𝑉_𝑖 ), 𝐴_𝑖 ∈ 𝐴𝑉_R\)
3.2.2 数据更可信 修复规则
由于直接根据元组数据修改错误规则,很可能从一个错误规则到另一个错误规则。
所以修复规则需要更新SeqGAN中的鉴别器(discriminator) \(D_d\) ,然后用 \(D_d\) 更新生成器 \(G_s\),用于生成新的规则。
\(D_d\) 的参数被初始化为 \(D_s\),然后通过 真实数据 和 基于不可信规则生成的新的伪造数据 来更新它。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号