机器学习笔记:sklearn.datasets样本生成器——make_classification、make_blobs、make_regression
一、介绍
scikit-learn 包含各种随机样本的生成器,可以用来建立可控制大小和复杂性的人工数据集。
- make_blob() —— 聚类生成器
- make_classification() —— 单标签分类生成器
- make_multilabel_classification() —— 多标签生成器
- make_regression() —— 回归生成器
二、分类生成器 make_classification
专门通过引入相关的,冗余的和未知的噪音特征,将高斯集群的每个类复杂化。
1.使用语法
sklearn.datasets.make_classification(
n_samples=100, # 样本个数
n_features=20, # 特征个数
n_informative=2, # 有效特征个数
n_redundant=2, # 冗余特征个数(有效特征的随机组合)
n_repeated=0, # 重复特征个数(有效特征和冗余特征的随机组合)
n_classes=2, # 样本类别
n_clusters_per_class=2, # 蔟的个数
weights=None, # 每个类的权重 用于分配样本点
flip_y=0.01, # 随机交换样本的一段 y噪声值的比重
class_sep=1.0, # 类与类之间区分清楚的程度
hypercube=True, # 如果为True,则将簇放置在超立方体的顶点上;如果为False,则将簇放置在随机多面体的顶点上。
shift=0.0, # 将各个特征的值移动,即加上或减去某个值
scale=1.0, # 将各个特征的值乘上某个数,放大或缩小
shuffle=True, # 是否洗牌样本
random_state=None) # 随机种子
- n_informative —— 有价值的重要特征
- n_redundant —— 将重要特征进行线性组合的特征
- n_clusters_per_class —— 簇的个数,某一个类别由几个簇构成
2.实操
- 默认参数
from collections import Counter
from sklearn.datasets import make_classification
X, y = make_classification()
Counter(y) # Counter({0: 50, 1: 50})
- 修改参数
from collections import Counter
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(
n_samples=1000,
n_features=25,
n_informative=3,
n_redundant=2,
n_repeated=0,
n_classes=3,
n_clusters_per_class=1,
random_state=42
)
Counter(y) # Counter({0: 332, 1: 335, 2: 333})
print("原始特征维度:", X.shape)
# 原始特征维度: (1000, 25)
# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.3)
三、聚类生成器 make_blobs
对于中心和各簇的标准偏差提供了更好的控制,可用于演示聚类。
1.使用语法
sklearn.datasets.make_blobs(
n_samples=100, # 样本数量
n_features=2, # 特征数量
centers=None, # 中心个数 int
cluster_std=1.0, # 聚簇的标准差
center_box(-10.0, 10.0), # 聚簇中心的边界框
shuffle=True, # 是否洗牌样本
random_state=None #随机种子
)
2.实操
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
import numpy as np
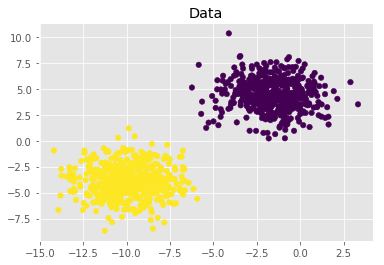
X, y = make_blobs(n_samples=1000,
n_features=2,
centers=2,
cluster_std=1.5,
random_state=1)
plt.style.use('ggplot')
plt.figure()
plt.title('Data')
plt.scatter(X[:, 0], X[:, 1], marker='o', c=np.squeeze(y), s=30)
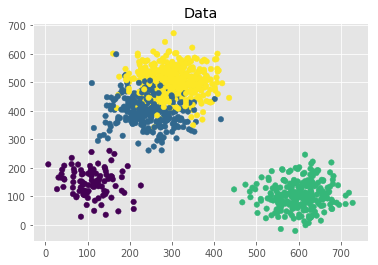
X, y = make_blobs(n_samples=[100,300,250,400],
n_features=2,
centers=[[100,150],[250,400],[600,100],[300,500]],
cluster_std=50,
random_state=1)
plt.style.use('ggplot')
plt.figure()
plt.title('Data')
plt.scatter(X[:, 0], X[:, 1], marker='o', c=np.squeeze(y), s=30)
生成4个聚簇,数量分别为:100、300、250、400。
中心坐标为[数组]。
四、多标签生成器 make_multilabel_classification
sklearn.datasets.make_multilabel_classification(
n_samples=100,
n_features=20,
n_classes=5,
n_labels=2,
length=50,
allow_unlabeled=True,
sparse=False,
return_indicator='dense',
return_distributions=False,
random_state=None)
五、回归生成器 make_regression
回归生成器所产生的回归目标作为一个可选择的稀疏线性组合的具有噪声的随机的特征。
它的信息特征可能是不相关的或低秩(少数特征占大多数的方差),也即用于回归任务测试的样本生成器。
sklearn.datasets.make_regression(
n_samples=100,
n_features=100,
n_informative=10,
n_targets=1,
bias=0.0,
effective_rank=None,
tail_strength=0.5,
noise=0.0,
shuffle=True,
coef=False,
random_state=None
)
参考链接:sklearn.datasets.make_classification
参考链接:生成分类数据集(make_classification)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号