
大数据学习之Hbase基本架构以及集群安装部署27
1:Hbase概述
Apache HBase™是Hadoop数据库,是一个分布式,可扩展的大数据存储。
当您需要对大数据进行随机,实时读/写访问时,请使用Apache HBase™。该项目的目标是托
管非常大的表 - 数十亿行X百万列 - 在商品硬件集群上。Apache HBase是一个开源的,分布式的,
版本化的非关系数据库,模仿Google的Bigtable: Chang等人的结构化数据分布式存储系统。
正如Bigtable利用Google文件系统提供的分布式数据存储一样,
ApacheHBase在Hadoop和HDFS之上提供类似Bigtable的功能。
2006年-google发表了bigtable的白皮书
2006年-开始开发hbase
2008年-hbase正式成为apache的子项目
2010年-正式成为apache的顶级项目
2:Hbase架构
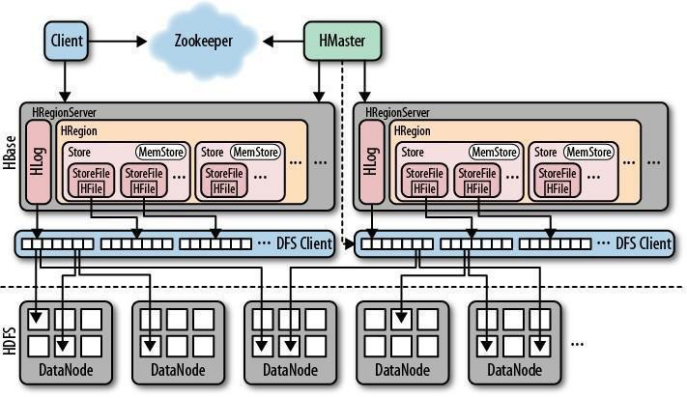
hbase的详细架构说明可以参照这篇文章。很详细https://www.cnblogs.com/shitouer/archive/2012/06/04/2533518.html
3:HBase 数据模型

4:Hbase读取数据流程图
读取数据流程
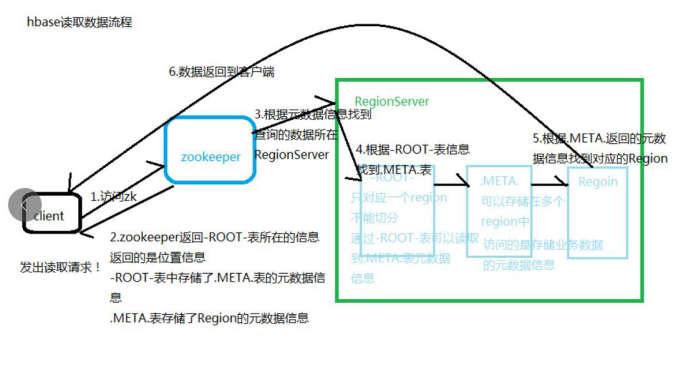
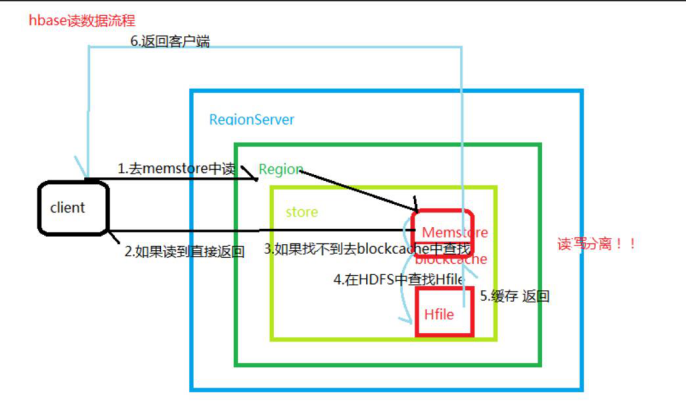
详细图:
这里对region中读取数据进行了放大。上述的第五步根据.META.返回元数据信息找到对应的Region。。而这里客服端首先读取的Memstore中的blockcache。也就是读取内存里的。如果内存里面没有再去读取HFile中的数据。这样读写效率更高
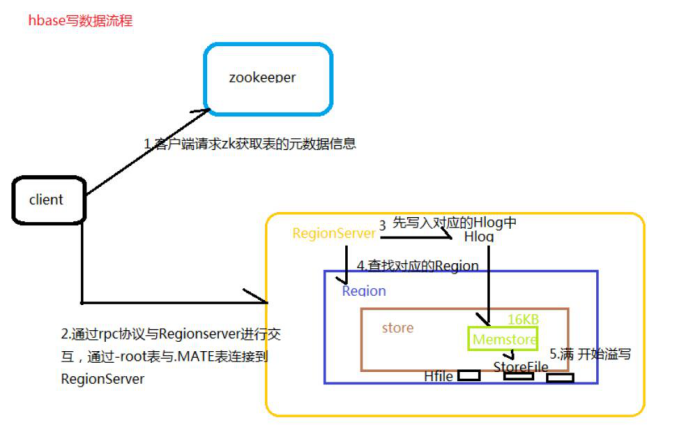
写数据流程
5:Hbase集群安装部署
集群配置:
zk集群3台
hadoop集群3台
hbase集群3台
1)上传
2)解压
3)修改配置文件
hbase-env.sh
JAVA_HOME=
ZK=


hbase-site.xml
加入配置信息
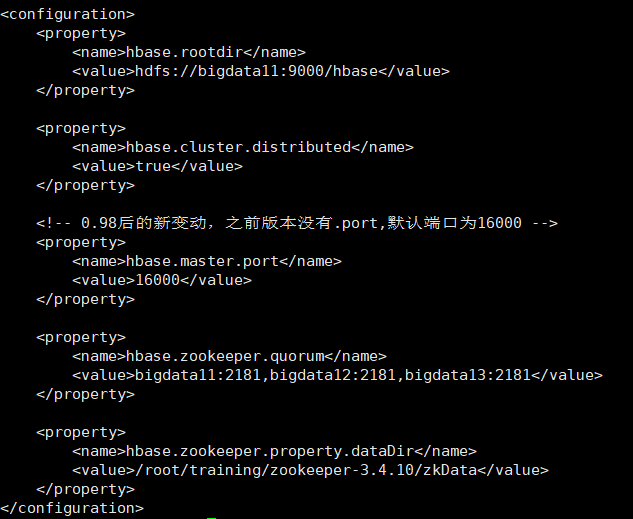
regionservers
加入从节点

4)解决依赖问题
把相关版本的zookeeper和hadoop的依赖包导入到hbase/lib下
我的hadoop是2.8.4版本的,把所有的hadoop的包全部换成2.8.4版本的。换成你用的hadoop包还有zookeeper的一个包

软连接hadoop配置(因为hbase是基于hdfs的)
软连接就像Windows上的一个快捷方式
ln -s /hadoop/core-site.xml /hbase/conf
ln -s /hadoop/hdfs-site.xml /hbase/conf

5)启动集群
bin/hbase-daemon.sh start master (bigdata11)
bin/hbase-daemon.sh start regionserver (bigdata11,bigdata12,bigdata13)
6)启动终端
bin/hbase shell
7)ui界面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号