
大数据学习之zookeeper组件基本原理17
zookeeper
一:Zookeeper(动物管理员)简介
整个大数据生态圈就是一个动物园。Hadoop就是小象,hive就是一个小蜜蜂,hbase图标就是一个鲸鱼。等等都是用动物来作为图标,zookeeper的图标就是一个管理员。所以顾名思义,zookeeper就是管理他们的嘛!嘻嘻嘻嘻
Apache ZooKeeper致力于开发和维护开源服务器,实现高度可靠的分布式协调。
二:什么是ZooKeeper?
ZooKeeper是一种集中式服务,用于维护配置信息,命名,提供分布式同步和提供组服务。所有这 些类型的服务都以分布式应用程序的某种形式使用。每次实施它们都需要做很多工作来修复不可避 免的错误和竞争条件。由于难以实现这些类型的服务,应用程序最初通常会吝啬它们,这使得它们 在变化的情况下变得脆弱并且难以管理。即使正确完成,这些服务的不同实现也会在部署应用程序 时导致管理复杂性。
三:zookeeper功能
(1)存储数据
(2)监听
四:zookeeper工作机制
基于观察者模式设计的分布式服务管理框架

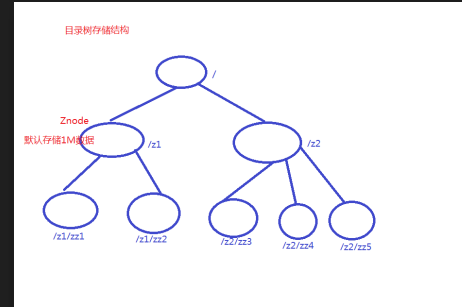
五:zookeeper的存储结构
目录树结构(树结构)
六:zookeeper应用场景
(1)集群统一配置管理
(2)集群统一命名服务
(3)集群统一管理
(4)服务器的动态上下线感知
(5)负载均衡
七:安装zookeeper集群
1:本地模式(单节点)
(1)下载安装包
(2)上传安装包到Linux alt+p
(3)解压 tar -zxvf .tar
(4)修改配置文件 vi zoo.cfg dataDir=/root/hd/zookeeper-3.4.10/zkData
(5)启动zk bin/zkServer.sh start
(6)查看状态 bin/zkServer.sh status
(7)启动客户端 bin/zkCli.sh
2:完全分布式安装
(1)下载安装包
(2)上传安装包到Linux alt+p
(3)解压 tar -zxvf .tar
(4)修改配置文件 vi zoo.cfg dataDir=/root/hd/zookeeper-3.4.10/zkData
2181zookeeper端口号
3888通信端口
###############cluster###############
server.1=bigdata11:2888:3888
server.2=bigdata12:2888:3888
server.3=bigdata13:2888:3888
(5)添加文件myid
$cd zookeeper-3.4.10/zkData
$touch myid
(6)添加内容在myid为1
$ vi myid 1
(7)发送zookeeper文件到其它机器

$ scp -r zookeeper-3.4.10 bigdata12:$PWD
(8) 修改myid依次为2 3
(9) 修改环境变量
vi /etc/profile export
ZOOKEEPER_HOME=/root/training/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin
(10) 生效环境变量
source /etc/profile
(8) 启动zookeeper
zkServer.sh start
(9) 查看状态
zkServer.sh status
(10) 关闭zookeeper
zkServer.sh stop
八:zookeeper的选举机制
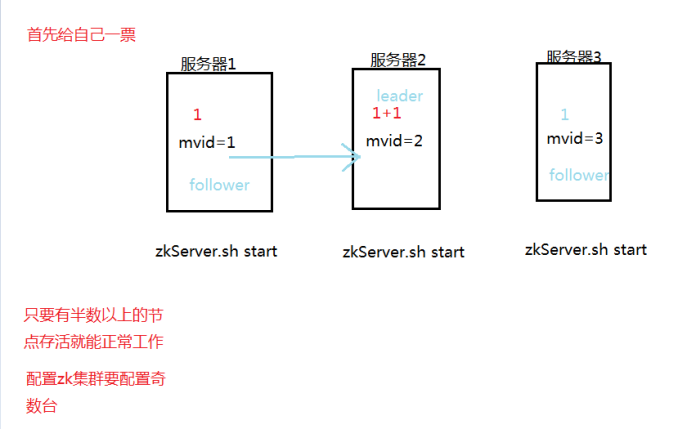
选举原理:
首先我们立个规矩,就是3个人的话我们只需要前2个人参与投票就行了。5个人的话我们就要前3个人参与投票,依次类推,7个人就只用4个人参与投票,,也就是前“过半加一”参与投票
假如我们有3台服务器(2人参与投票),结合图看
第一步:启动第一台服务器(zkServe.sh start)
这个时候,server1首先会给自己一票(有点直接,像老外投票一样,上来就给自己一票。不像我们国家一样,都是给别人投票。)
第二步:启动第二台服务器(zkServe.sh start)
此时,还是老规矩,server2也会投自己一票,然后server1再给他一票,就是2票了,比server1票数多,这时候server2就是leader了,老大。server1只有1票,只能做follower小弟
第三步:启动第三台服务器(zkServe.sh start)
先看规矩:发现server2已经是老大了,这时候他就认命了。也不要server1,server2的票了,自愿做follwer小弟
所以每次我们的启动3台zk的时候一般都是第二个启动的是老大leader,其他2个就是小弟
假如我们有5台服务器,和上面分析的一样:
第一步:启动第一台服务器(zkServe.sh start)
这个时候,server1首先会给自己一票(有点直接,像老外投票一样,上来就给自己一票。不像我们国家一样,都是给别人投票。)
第二步:启动第二台服务器(zkServe.sh start)
此时,还是老规矩,server2也会投自己一票,然后server1再给他一票,就是2票了,比server1票数多,但是还有server3还没有参加选举,继续选举
第三步:启动第三台服务器(zkServe.sh start)
此时,还是老规矩,server3会投自己一票,然后server1,server2再给他2票,就是3票了,比server2票数多,这时候server3就是leader了,老大。server1只有1票,server2只有2票,这2人只能做follower小弟
其他的也就依次类推了。。。。。。。。。。。。。。



注意事项:一般zk集群配置要配置奇数台,应为在一个集群中,只要有半数以上节点存活就能正常工作,如果你是偶数台,死了一半,五五开就不好进行判断。。
