大数据学习之HDFS基本API操作(下)06
hdfs文件流操作方法一:
package it.dawn.HDFSPra; import java.io.BufferedReader; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStreamReader; import java.net.URI; import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.zookeeper.common.IOUtils; import org.junit.Before; import org.junit.Test; /** * @version 1.0 * @author Dawn * @date 2019年4月28日22:28:53 * @return hdfs的读写操作。顺便练习一下java的IO操作 */ public class HdfsReadData02 { public static FileSystem fs=null; public static String hdfs="hdfs://bigdata11:9000"; @Before public void init() throws IOException, InterruptedException, URISyntaxException { //其实这一句我也不是很清楚。不加这个有个异常,我看起来感觉很恶心。不过没有影响。大家加不加都没问题 System.setProperty("hadoop.home.dir", "E:\\hadoop2.7.3\\hadoop-2.7.3"); //1 加载配置 Configuration conf=new Configuration(); //2 构造客服端 fs=FileSystem.get(new URI(hdfs), conf, "root"); } //读数据方式1 @Test public void testReadData1() throws IllegalArgumentException, IOException { //1 拿到流 //其实和这个没啥差别fs.copyToLocalFile(new Path("/xxx.txt"), new Path("f:/")); FSDataInputStream in=fs.open(new Path("/xxx.txt")); byte[] buf=new byte[1024]; in.read(buf); //打印出来 System.out.println(new String(buf)); //记得关闭流 in.close(); fs.close(); } //读数据方式2 (加了一个缓冲流而已) @Test public void testReadData2() throws IllegalArgumentException, IOException { //1 拿到流 FSDataInputStream in=fs.open(new Path("/xxx.txt")); //2.缓冲流 BufferedReader br=new BufferedReader(new InputStreamReader(in, "UTF-8")); //3.按行读取 String line=null; //4:一行一行的读数据 while((line=br.readLine()) != null) { //打印出来 System.out.println(line); } //5.关闭资源 br.close(); in.close(); fs.close(); } /* * 读取hdfs中指定偏移量 */ @Test public void testRandomRead() throws IllegalArgumentException, IOException { //1:拿到流 FSDataInputStream in= fs.open(new Path("/xxx.txt")); in.seek(3); byte[] b=new byte[5]; in.read(b); System.out.println(new String(b)); in.close(); fs.close(); } /** * 在hdfs中写数据 直接对存在的文件进行写操作 * fs.creat(hdfsFilename,false) * @param Path f * @param boolean overwrite */ @Test public void testWriteData() throws IllegalArgumentException, IOException { //拿到输出流 FSDataOutputStream out=fs.create(new Path("/dawn.txt"),false);//第二个参数。是否覆盖 //2.输入流 FileInputStream in=new FileInputStream("f:/temp/a.txt");//其实我觉得new一个File好一点 byte[] buf=new byte[1024]; int read=0; while((read=in.read(buf)) != -1) { //the total number of bytes read into the buffer, or -1 if there is no more data because the end of the file has been reached. out.write(buf,0,read); } in.close(); out.close(); fs.close(); } /* * 在hdfs中写数据 写一个新的数据 */ @Test public void testWriteData1() throws IllegalArgumentException, IOException { //1.创建输出流 FSDataOutputStream out=fs.create(new Path("/haha")); //2.创建输入流 // FileInputStream in=new FileInputStream(new File("f:/temp/data.txt"));//没啥用 //3.写数据 out.write("dawn will success".getBytes()); //4.关闭资源 IOUtils.closeStream(out); fs.close(); } }
hdfs文件流操作方法二:
package it.dawn.HDFSPra; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.junit.Before; import org.junit.Test; /** * @version 1.0 * @author Dawn * @date 2019年4月28日23:21:03 * @return 使用IOUtills更为方便 */ public class HdfsIOUtilsTest { public static String hdfs="hdfs://bigdata11:9000"; public static FileSystem fs=null; public static Configuration conf=null; @Before public void init() throws IOException, InterruptedException, URISyntaxException { conf =new Configuration(); fs=FileSystem.get(new URI(hdfs), conf, "root"); } /* * 文件上传HDFS * */ @Test public void putFileToHDFS() throws IllegalArgumentException, IOException { //1.获取输入流 FileInputStream fis=new FileInputStream(new File("f:/temp/lol.txt")); //2获取输出流 FSDataOutputStream fos=fs.create(new Path("/dawn/n.txt")); //3 流的拷贝 IOUtils.copyBytes(fis, fos, conf); //4.关闭资源 IOUtils.closeStream(fis); IOUtils.closeStream(fos); } /* * 文件下载HDFS */ @Test public void getFileFromHDFS() throws IllegalArgumentException, IOException { //1.获取输入流 FSDataInputStream fis=fs.open(new Path("/xxx.txt")); //2.获取输出流 FileOutputStream fos=new FileOutputStream("f:/temp/lala.txt"); //3.流的对拷 IOUtils.copyBytes(fis, fos, conf); //4.关闭资源 IOUtils.closeStream(fos); IOUtils.closeStream(fis); } }
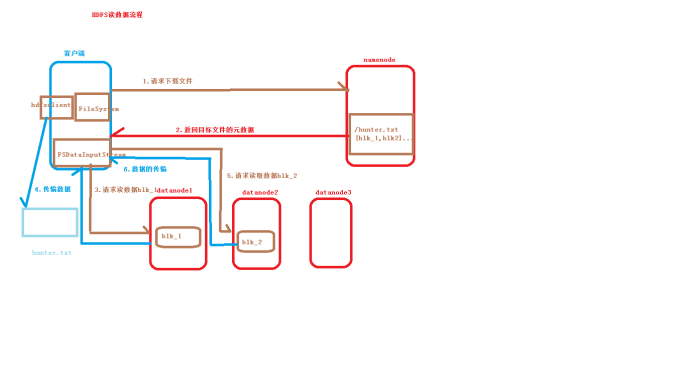
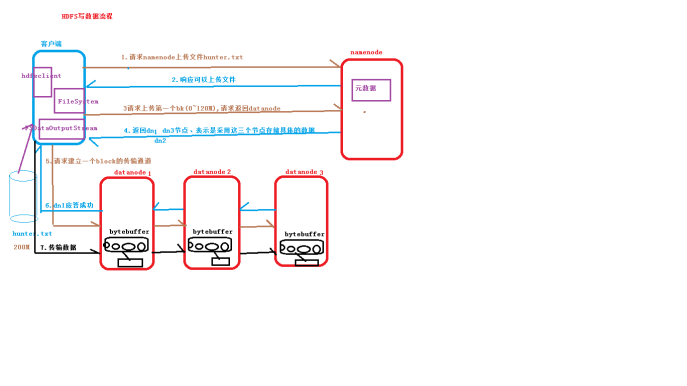
附上读写流程图