对抗样本综述(二)
引言
在对抗样本综述(一)中,我们介绍了对抗样本的背景和攻击分类,下面我们来看下常见的对抗攻击和对抗防御的方法有哪些。
对抗攻击
以下是著名的攻击方法:
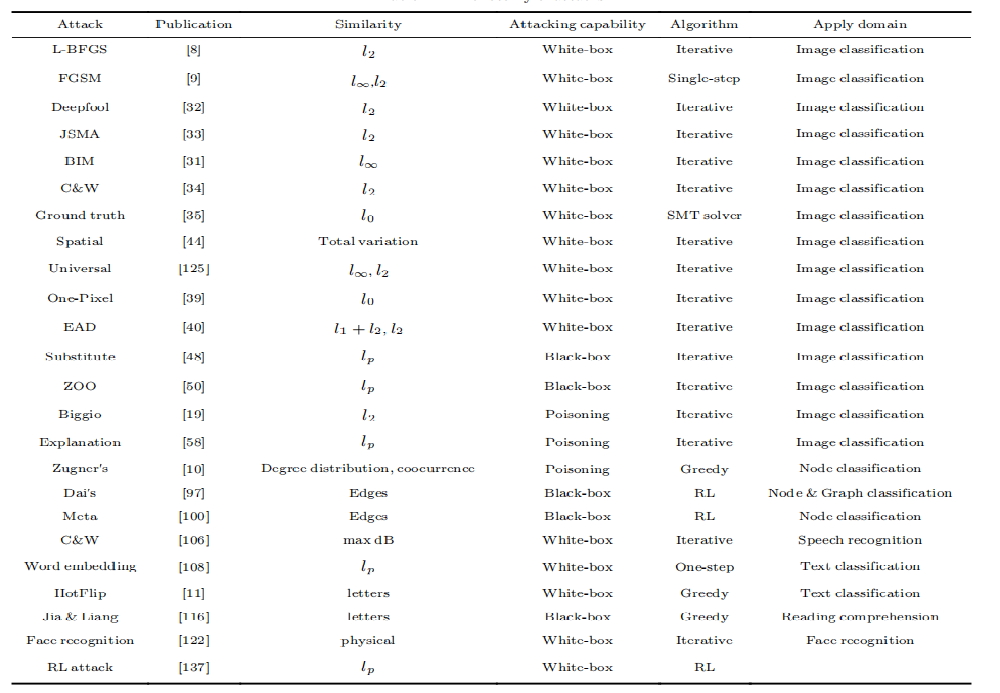
现有的对抗攻击大都通过\(L_p\)范数约束对抗样本和原图像之间的差异。需要注意的是,大多数攻击方法并不保证攻击一定使目标model产生错误分类。
对抗防御
现有的防御方法主要分为以下三类:
-
Gradient masking/Obfuscation:
指防御者故意隐藏模型梯度信息的策略,因为大多数攻击算法都是基于分类器的梯度信息。
-
Robust optimization:
重新训练DNN分类器的参数可以提高其鲁棒性。训练过的分类器将对随后生成的对抗样本进行正确地分类。
-
Adversarial example detection:
研究良性输入的分布,检测敌对输入,不允许对抗样本输入到分类器中。
Gradient masking
梯度隐藏的典型方法有
-
Defensive distillation
-
Shattered gradients
-
Stochastic/Randomized gradients
-
Exploding & vanishing gradients
Robust optimization
鲁棒性优化的典型方法有
-
Regularization methods
-
Adversarial (re)training
-
Certifified defense
Adversarial example detection
对抗样本检测是保护DNN分类器的另一种主要方法。这类方法不是直接预测模型的输入,而是首先区分输入是良性的还是敌对的。如果它能检测到输入是对抗性的,DNN分类器将拒绝预测其标签。
将检测技术应处理的威胁模型分为3类:
- 攻击者只能访问分类器的参数F,并且根本不知道检测模型D。
- 攻击者知道该模型F、检测方案D及其参数。
- 知识有限的对手知道模型F和检测方案D,但不知道D的参数。也就是说,这个对手并不知道模型的训练集。
检测方案有以下几类:
-
Secondary classification based detection:
基于二次分类的检测方式是指另外创建一个分类器用于检测对抗样本。
-
Principle component analysis detection:
主成分分析(PCA)通过线性变换,将𝑛维空间中的一组点转换为𝑘维空间(𝑘≤𝑛)中的一组新点。
-
Distributional detection:
通过比较自然图像的分布和对抗样本的分布来检测后者,使用经典的统计方法来区分自然图像和对抗样本。
-
Normalization detection:
使用Dropout Randomization等方法。Feinman等人提出了一种称为贝叶斯神经网络不确定性的方法。该方法测量神经网络对给定输入的不确定性。它们不依赖于网络所报告的置信度(很容易被攻击者控制),而是为网络添加了随机化。我们希望无论选择的随机值如何,一个自然图像都会有相同的(正确的)标签,而对抗样本并不总是被预测为相同的标签。使用Dropout作为添加随机性的方法。
参考文献:
[1] Xu, H., Ma, Y., Liu, HC. et al. Adversarial Attacks and Defenses in Images, Graphs and Text: A Review. Int. J. Autom. Comput. 17, 151–178 (2020). https://doi.org/10.1007/s11633-019-1211-x
[2] Nicholas Carlini and David Wagner. 2017. Adversarial Examples Are Not Easily Detected: Bypassing Ten Detection Methods. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security (AISec '17). Association for Computing Machinery, New York, NY, USA, 3–14. DOI:https://doi.org/10.1145/3128572.3140444
